为什么要使用RabbitMQ?
异步,解耦,削峰。
异步
提高效率;一个挂了,另外的服务不受影响。
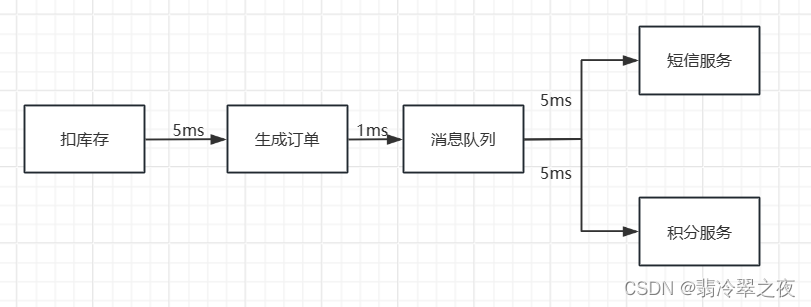
解耦
增加或减少服务比较方便。
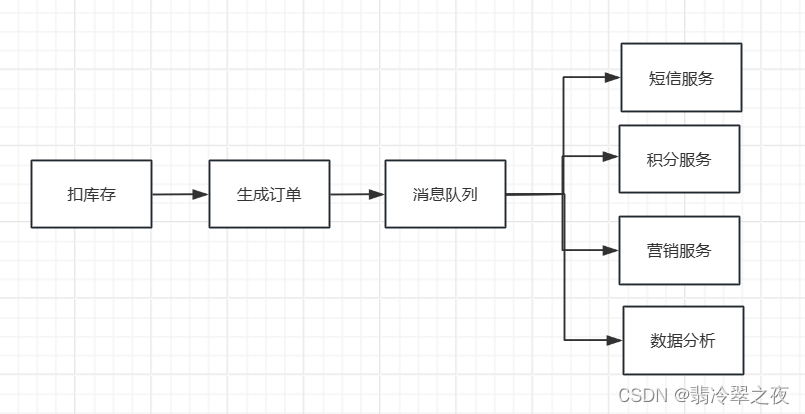
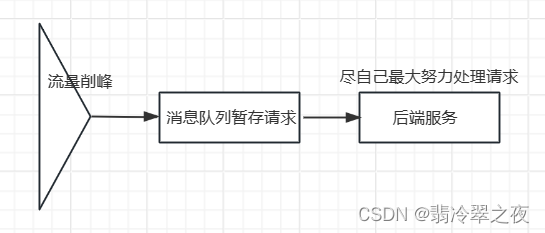
削峰
每天0点到16点,A系统风平浪静,每秒并发数量就100个。结果每次到了16点到23点,每秒并发数量突然会增加到1w条。但是系统最大的处理能力就只能是每秒处理1000个请求。需要我们进行流量的削峰,让系统可以平缓的处理突增的请求。
存在的问题
-
RabbitMQ对消息队列的支持并不好,当大量消息积压的时候,会导致RabbitMQ的性能急剧下降
-
RabbitMQ的性能是这几个消息队列当中最差的,大概每秒钟可以处理几万到十几万条消息,如果应用对消息队列的性能要求非常高,不要选择RabbitMQ
-
使用的语言是Erlang,拓展和二次开发成本高
RabbitMQ如何保证消息不丢失?
-
确保消息到MQ(发送方的确认模式)
-
确保消息能够路由到正确的队列当中(路由失败通知)
-
确保消息在队列中正确的存储(交换器,队列,消息都需要持久化)
-
确保消息从队列中正确的投递给消费者(手动确认->交给消费者来确认)
什么是MQ中的消息重复?
-
消息发送端产生消息重复的原因是消息成功进入消息存储后,因为各种原因使得消息发送端没有收到“成功”的返回结果,并且因为存在重试机制,所以消息重复发送。
-
在投递过程中产生的消息重复接收主要是因为消息接收者成功处理完消息之后,消息中间件不能及时更新投递状态造成的(就是MQ没有收到ACK,就没删除掉消息)
如何保证幂等性?
主要是消息接收者来处理这种重复的情况,也就是要求消息接收方的消息处理是幂等操作。
对于消息接收端的情况,幂等的含义是采用相同的输入多次调用处理函数,得到同样的结果。
-
MVCC
多版本并发控制,乐观锁的一种实现,在生产者发送消息时进行数据更新时需要带上数据的版本号,消费者去更新时需要去比较持有数据的版本号。
版本号不一致的操作无法更新成功,例如博客点赞次数自动+1的接口。
public boolean addCount(Long id,Long version){
update blogTable set count = count + 1,version = version+1 where id=321 and verison=123;
}
每个version只有一次执行成功的机会,一旦失败了生产者必须重新获取数据的最新版本号再次发起更新。
-
去重表
利用数据库表单的特性来实现幂等,常用的一个思路是在表上构建唯一性索引,保证某一类数据一旦执行完毕,后续同样的请求不再重复处理了(利用一张日志表来记录已经处理成功的消息的 ID,如果新到的消息 ID 已经在日志表中,那么就不再处理这条消息。)
以电商平台为例子,电商平台上的订单 id 就是最适合的 token。当用户下单时,会经历多个环节,比如生成订单,减库存,减优惠券等等。每一个环节执行时都先检测一下该订单 id 是否已经执行过这一步骤,对未执行的请求,执行操作并缓存结果,而对已经执行过的 id,则直接返回之前的执行结果,不做任何操作。
这样可以在最大程度上避免操作的重复执行问题,缓存起来的执行结果也能用于事务的控制等。

![[笔试强训]day3](https://img-blog.csdnimg.cn/direct/4e81a85c6ee34a8e8e74a7f057d54d42.png)