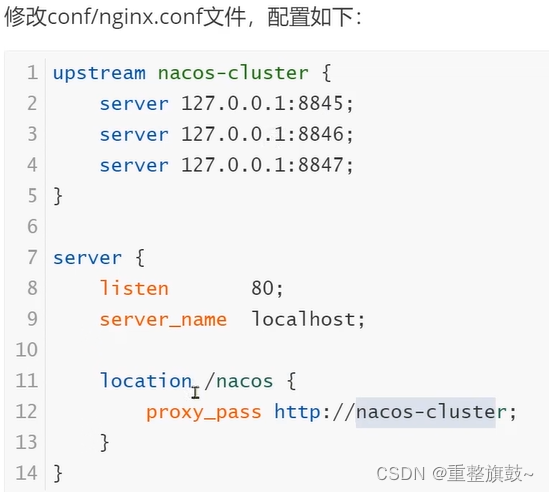
原论文:The Log-Structured Merge-Tree (LSM-Tree)
LSM-Tree的简介和关键技术要点
LSM-Tree(Log-Structured Merge-Tree)是一种为高吞吐量读写操作优化的数据结构,特别适用于写入密集型的应用场景。它由Patrick O’Neil等人开发,旨在提供一种低成本的索引方法,以处理大量记录插入和删除的操作。以下是对LSM-Tree的简介和关键技术要点的总结:
简介
- 目的:LSM-Tree是为了解决传统磁盘索引结构(如B树)在处理高比例插入和删除操作时遇到的性能问题。
- 应用场景:适用于那些插入操作远比查找操作频繁的场景(写多读少),如历史表(History tables)和日志文件(log files)。
- 设计原则:通过将数据首先写入内存中的结构(C0树),然后通过合并过程将数据批量写入磁盘上的结构(C1树),以此减少磁盘I/O操作。
关键技术要点
- 两层结构:
- C0树(内存中):较小,用于快速插入新记录。
- C1树(磁盘上):较大,用于存储经过合并操作后的数据。
- 延迟更新和批量I/O:
- 写操作首先在C0树中进行,当C0树达到一定大小后,通过合并(merge)操作将数据批量写入C1树。
- 合并策略:
- 使用滚动合并(rolling merge)过程,将C0树中的数据与C1树中的数据合并,去除重复数据,减少磁盘寻址时间。
- 查找操作:
- 查找操作需要同时搜索C0树和C1树,可能会带来轻微的CPU开销。
- 索引更新:
- 删除和更新操作也可以通过合并过程中的延迟处理来优化。
- 多组件LSM树:
- 为了提高性能和减少内存使用,可以设计多于两个组件的LSM树,通过增加中间大小的磁盘基组件来平衡内存和磁盘成本。
- 并发控制和恢复:
- 通过节点锁定机制来处理并发访问,并使用检查点(checkpoint)和日志来确保系统崩溃后的恢复。
LSM-Tree通过其创新的结构和算法,在保证查找(读)性能的情况下,实现了对大量写入操作的优化,使其成为许多现代数据库和索引结构的基础。
原论文阅读
1. Introduction
- 长事务处理系统的需求:随着长事务活动流管理系统的商业化,对事务日志记录提供索引访问的需求增加。传统上,事务日志着重于中止和恢复,但随着系统处理更复杂活动的能力增加,需要实时回顾过去的事务步骤。
- 索引访问的重要性:对于大量的过去活动日志,索引日志访问变得日益重要,以支持对历史表的查询,尤其是在高插入量的情况下。
- B树的局限性:标准磁盘索引结构,如B树,在实时维护索引时,会显著增加系统的I/O成本,有时甚至使系统总成本增加高达50%。
- LSM树的提出:LSM树(Log-Structured Merge-tree)作为一种磁盘数据结构,旨在为高比例记录插入(和删除)的文件提供低成本索引。
- LSM树的工作原理:LSM树使用一种算法,将索引变更推迟并批量处理,通过内存组件和磁盘组件以类似归并排序的方式高效地进行变更。
- LSM树的优势:与传统的访问方法(如B树)相比,LSM树大大减少了磁盘臂移动,提高了成本效益,特别是在磁盘臂成本超过存储介质成本的领域。
- LSM树的应用场景:LSM树特别适用于插入操作比查找操作更频繁的场景,如历史表和日志文件。
- 五分钟规则:引入了“五分钟规则”的概念,即如果一个数据页的引用频率超过大约每60秒一次,那么通过购买内存缓冲区来保持这些页在内存中,从而避免磁盘I/O操作,是经济上划算的。这是一个关于内存缓冲和磁盘I/O成本权衡的经验法则。
- 两个例子
- 示例1.1考虑了TPC-A基准测试中的多用户应用,该应用以每秒1000个事务的处理速度运行。每个事务更新一个随机选择的账户记录中的余额列,然后向历史表中写入一行记录。历史表包含有关账户ID、分行ID、出纳员ID、交易金额和时间戳的信息。论文讨论了在这种高事务量下,如何通过磁盘I/O操作来维护账户表,并指出如果账户表的页面不能常驻内存,那么每个事务将需要两次磁盘I/O操作:一次用于读取账户记录,一次用于写入(为了在缓冲区中为新读取腾出空间)。这种高I/O需求导致需要大量的磁盘驱动器。
- 示例1.2探讨了在高插入量的History表上建立索引的情况。论文指出,如果没有一个有效的索引,那么对于特定账户的近期活动查询将变得不可行,因为需要直接搜索整个History表的所有行。论文考虑了一个基于“Acct-ID||Timestamp”的B树索引,这对于支持高效的账户活动查询至关重要。然而,维护这样一个实时的B树索引将会使磁盘成本增加一倍,因为每个事务都需要至少一次页面读取和一次页面写入。
2. The Two Component LSM-Tree Algorithm

- 两组件结构:LSM树由两个主要组件构成,即C0树和C1树。C0树是内存中的组件,而C1树是磁盘上的组件。
- C0树的插入操作:当新的数据行生成时,首先会在C0树中插入相应的索引条目。由于C0树是内存中的结构,插入操作不涉及I/O成本。
- C1树的迁移:随着C0树的增长,当达到一定的阈值时,会触发一个合并(merge)过程,将C0树的一部分数据迁移到C1树。这个过程称为滚动合并(rolling merge)。
- 滚动合并过程:滚动合并是LSM树的核心机制,它通过一系列步骤将C0树的数据与C1树合并。在合并过程中,会创建新的C1树节点,并将这些节点写回磁盘。
- 内存与磁盘的优化:C1树虽然驻留在磁盘上,但频繁访问的节点会保留在内存缓冲区中,以提高性能。
- 查找操作:当执行查找操作时,LSM树会首先在C0树中搜索,如果不成功,则继续在C1树中搜索。
- C1树的结构:C1树具有类似B树的目录结构,但它针对顺序磁盘访问进行了优化。C1树的节点在磁盘上以多页块的形式打包,以提高磁盘臂的使用效率。

- 内存缓冲区的使用:在合并过程中,会使用内存缓冲区来暂存“空块”(正在被清空的C1树节点)和“满块”(正在填充的新C1树节点)。
- 恢复和并发控制:LSM树的恢复机制,包括使用日志记录来恢复未写入磁盘的C0树条目,以及处理系统崩溃后的恢复。
2.1 How a Two Component LSM-tree Grows
- C0树的初始化:LSM树从内存中的C0树开始,当有新的数据行生成时,首先会在C0树中插入相应的索引条目。
- C0树的增长:随着新的索引条目的不断插入,C0树会逐渐增长。C0树的结构不必像磁盘上的树那样遵循严格的节点大小限制,因此可以使用(2-3)树或AVL树等结构,以优化CPU效率。
- C1树的构建:当C0树达到预设的阈值大小时,会触发一个合并过程,将C0树的一部分数据迁移到磁盘上的C1树。这些迁移的数据会被组织成C1树的叶节点,并且这些叶节点会被打包成100%满的多页块,以优化磁盘空间使用。
- 多页块的写入:随着C0树中的数据不断迁移,C1树的叶节点会被顺序地写入磁盘上的多页块。这些块填满后会被写入磁盘,成为C1树的一部分。
- 目录节点的创建:随着叶节点的添加,C1树的目录节点结构也会在内存中创建和维护。目录节点包含分隔符,用于引导访问到单个页面节点,类似于B树。
- 单页节点和多页块的使用:C1树优化了单页节点的使用,以支持精确匹配查找,同时利用多页块I/O进行滚动合并或长范围检索。
- C1树的增长:随着C0树中的数据不断被合并到C1树,C1树会逐渐增长。当C0树的右端叶条目首次被写入C1树后,合并过程会在两棵树之间循环进行。
- 滚动合并的复杂性:一旦合并开始,滚动合并过程会变得更为复杂。滚动合并过程在C0树和C1树的每个级别上都有一个概念游标,这些游标会逐渐通过C0树和C1树的相等键值。
- 合并过程中的节点管理:在滚动合并过程中,C1树的多页块会被分为“空块”和“满块”,分别代表尚未处理和已经合并的数据。
- 并发访问和恢复:LSM树需要处理并发访问问题,确保在滚动合并过程中,查找操作不会干扰到合并过程。同时,需要有适当的恢复机制来处理系统崩溃等情况。
2.2 Finds in the LSM-tree Index
-
查找操作的顺序:当执行精确匹配查找或需要即时响应的范围查找时,LSM树首先搜索内存中的C0树,然后在磁盘上的C1树中继续搜索。
-
CPU和I/O开销:由于需要搜索两个目录结构,因此在LSM树中执行查找可能会带来轻微的CPU开销。在多于两个组件的LSM树中,还可能涉及额外的I/O开销。
-
多组件LSM树的查找:在多组件LSM树中,为了保证查找操作能够检视所有条目,通常需要通过每个组件Ci的索引结构进行搜索。然而,存在一些优化手段可以限制搜索到组件的一个初始子集。
-
优化查找操作:如果索引值的唯一性可以通过生成逻辑保证(例如,保证时间戳的唯一性),那么在早期的Ci组件中找到所需值后,匹配索引查找就完成了。
-
查找最近插入的值:可以限制搜索,当查找标准使用近期的时间戳值时,假定所寻找的条目还没有迁移到最大的组件中。
-
保留最近插入的条目:在滚动合并过程中,经常有理由保留Ci中最近插入的条目(在过去的τi秒内),只允许较旧的条目迁移到Ci+1。
-
C0树的缓冲功能:在许多查找操作中,如果最频繁的查找引用是最近插入的值,那么许多查找可以在C0树中完成,因此C0树履行了宝贵的内存缓冲功能。
-
事务日志的索引:对于事务日志的索引,这些日志在创建后的相对较短的时间跨度内会有大量访问,预计这些索引将保持在内存中。
2.3 Deletes, Updates and Long-Latency Finds in the LSM-tree
- 删除操作:LSM树中的删除操作可以通过在C0树中放置一个删除节点来实现,该节点标记了要删除的记录的键值(key value),但在实际的删除操作在滚动合并过程中进行之前,它并不会从C0树中移除。
- 删除节点的迁移:在滚动合并过程中,删除节点会像其他节点一样迁移到更大的组件中。当遇到特定的键值时,删除节点会与相应的索引条目配对,并在合并过程中将该条目删除。
- 查找操作中的删除过滤:在执行查找操作时,系统需要通过删除节点进行过滤,以避免返回已删除记录的引用。
- 更新操作:对于记录的更新,LSM树可以将其视为先进行删除操作,然后是插入操作。这意味着更新会导致原有的索引条目被标记为删除,并插入一个新的索引条目。
- 长延迟查找:LSM树支持所谓的长延迟查找操作,这种操作允许查询结果等待,直到最慢的滚动合并游标完成其循环周期。这种查找操作通过在C0树中插入一个查找笔记条目来启动,然后在数据迁移到后续组件时进行实际查找。
3. Multi-Component LSM-trees

- 多组件LSM树的引入:在二组件LSM树中,内存组件C0与磁盘组件C1之间的大小比例对性能和成本有显著影响。如果C0组件相对于C1组件过大,会导致内存使用成本增加;如果C0组件过小,则会导致每次合并操作处理的数据量较少,降低了合并操作的批处理效率。通过引入更多的磁盘组件,可以更精细地调整这些组件的大小,以达到成本和性能的更佳平衡。这样可以减少对昂贵内存资源的依赖,同时利用成本较低的磁盘存储。
- 优化I/O性能:通过在多个磁盘组件之间进行滚动合并,可以更有效地利用磁盘I/O资源。较小的C0组件可以更快地与C1组件合并,减少了单个合并操作的I/O开销。
- 更好的批量效率:多组件LSM树通过在组件之间进行更多的滚动合并,提高了批量处理效率。这意味着在合并过程中,更多的数据可以被一次性处理,从而减少了对磁盘的访问次数。
- 灵活性和可扩展性:多组件设计提供了更大的灵活性,可以根据不同的工作负载和性能要求调整组件的数量和大小。
- 减少对内存缓冲区的需求:在多组件LSM树中,由于C0组件可以设计得更小,因此减少了对内存缓冲区的需求,这对于内存资源有限的系统尤其有益。
- 提高写入性能:多组件LSM树特别适合于写入密集型的应用场景,因为它可以更有效地处理大量的数据插入,而不会显著增加I/O成本。
- 减少恢复时间:在系统崩溃后,多组件LSM树可以利用其结构更快速地恢复到崩溃前的状态,因为有更多的组件参与数据的持久化。
- 适应不同的工作负载:多组件LSM树可以根据工作负载的特点(如写入与读取操作的比例)动态调整组件的大小和数量,以适应不同的操作模式。
- 提高数据温度的适应性:通过多组件设计,LSM树可以更有效地处理不同“温度”的数据,即可以根据数据的访问频率来调整其在LSM树中的位置。
4. Concurrency and Recovery in the LSM-tree
4.1 Concurrency in the LSM-tree
- 并发控制需求:LSM树设计用于高并发的环境,需要处理多种类型的并发操作,包括查找、插入和删除。LSM树的并发访问必须解决以下三种物理冲突:
- 当硬盘中的相邻部件进行滚动合并的时候,当前参与合并的结点不能被查找;
- 当C0和C1进行滚动合并的时候,当前参与合并的C0的结点周边不能被查找和插入;
- 在Ci-1和Ci与Ci和Ci+1同时进行滚动合并时,Ci-1与Ci滚动合并的游标有时会超过Ci和Ci+1滚动合并的游标。
- 锁机制:为了控制对磁盘上组件的并发访问,LSM树使用节点级别的锁定机制。这意味着在进行修改操作(如滚动合并)时,相关的节点会被锁定,以防止其他进程同时访问。
- 节点锁定:LSM树通常在节点级别实施锁定。当一个节点被选中进行读取或写入操作时,会对其进行锁定,以防止其他事务同时修改该节点。
- 读写锁:
- 读锁(Shared Lock):在读操作期间,节点会被加上读锁,允许多个读操作并发进行,但写操作会被阻塞,直到读锁被释放。
- 写锁(Exclusive Lock):在写操作(包括插入、更新和删除)期间,节点会被加上写锁,这会阻塞其他所有读写操作,直到写操作完成。
- 锁定范围:锁定可以应用于单个节点,也可以扩展到整个树或树的一部分,具体取决于操作的类型和范围。
- 查找操作与合并操作的并发:在LSM树中,查找操作可能需要同时访问C0和C1树,而滚动合并操作可能在后台进行。需要确保查找操作不会干扰合并过程,反之亦然。
- 滚动合并的并发问题:滚动合并操作在将数据从C0树迁移到C1树时,需要特别考虑并发问题。特别是,当多个滚动合并操作同时进行时,需要确保它们的合并游标不会相互干扰。
- 独立的CPU核心:为了最大限度地减少对其他操作的干扰,通常会将滚动合并任务分配给一个独立的CPU核心来专门处理。
- 合并游标:LSM树使用合并游标(Merge Cursor)来跟踪滚动合并的进度。这个游标在C0树和C1树中都有对应的位置,指示下一步要合并的数据。
- 缓冲区管理:滚动合并过程中,会使用内存缓冲区来暂存即将写入磁盘的数据。这些缓冲区在合并期间可能会被锁定,以防止其他操作干扰。
- 并发写入:如果有多个滚动合并操作同时进行,每个操作都会有自己的合并游标和缓冲区,以避免相互干扰。
- 内存与磁盘组件的并发:C0作为内存中的组件,其并发控制策略可能与磁盘上的C1和其他组件不同。C0的并发控制可能依赖于其底层数据结构的特性。
4.2 Recovery in the LSM-tree
- 崩溃恢复的必要性:LSM树在内存中进行数据的插入和合并操作,这些操作在写入磁盘之前是不持久的。因此,系统崩溃后需要恢复这些未持久化的数据。
- 日志记录:LSM树使用日志记录来确保崩溃后可以恢复未写入磁盘的数据。每个插入操作都会生成一个日志记录,这些记录在系统恢复时被重放。
- 检查点:LSM树通过周期性地创建检查点来减少恢复时间。在创建检查点时,会生成一个特殊的检查点日志,检查点包括当前时刻最后一个插入的已索引的行的日志序列号如LSN0、C0树的内容、所有磁盘组件的根节点地址、合并游标的位置以及多页块分配的信息。
- 当需要在时刻T0设置检查点时:
- 完成所有部件的当前合并,这样结点上的锁就会被释放;
- 将所有新条目的插入操作以及滚动合并推迟至检查点设置完成之后;
- 将C0写入硬盘中的一个已知的位置;此后对C0的插入操作可以开始,但是合并操作还要继续等待;
- 将硬盘中的所有部件(C1~CK)在内存中缓存的结点写入硬盘;
- 向日志中写入一条特殊的检查点日志。
- 当需要在时刻T0设置检查点时:
- 恢复过程:在系统崩溃后,LSM树通过加载检查点日志中保存的C0树到内存中,并从检查点后的第一个LSN开始重放日志记录,将新的索引条目插入到C0树中。
- 当系统崩溃后重启进行恢复时,需要进行如下操作:
- 在日志中定位一个检查点;
- 将之前写入硬盘的C0和其它部件在内存中缓存的多页块加载到内存中;
- 将日志中在LSN0之后的部分读入内存,执行其中索引条目的插入操作;
- 读取检查点日志中硬盘部件(C1~CK)的根的位置和合并游标,启动滚动合并,覆盖检查点之后的多页块;
- 当检查点之后的所有新索引条目都已插入至LSM-tree且被索引后,恢复即完成。
- 当系统崩溃后重启进行恢复时,需要进行如下操作:
- 合并操作的恢复:在恢复过程中,滚动合并操作会被重新启动,并且会覆盖检查点后写入的任何多页块,直到所有最近插入的行都被索引。
- 目录信息的恢复:在恢复过程中,需要更新目录信息,以反映合并过程中对节点结构的更改。
- 磁盘空间的管理:LSM树需要在恢复过程中管理磁盘空间的使用,确保可以重用旧的多页块,并且不会与合并过程中新写的块冲突。
- 并发恢复:LSM树的恢复过程可能需要处理并发问题,特别是如果有多个合并操作在崩溃时正在进行。
- 恢复时间:LSM树的设计旨在最小化恢复时间,通过减少需要重放的日志记录数量和优化检查点的创建。
- 一致性保证:LSM树的恢复机制确保了系统崩溃后数据的一致性,即使在写入操作未完全完成的情况下。
- 性能影响:虽然检查点和恢复过程可能会引入一些性能开销,但LSM树的设计使得这些开销在可接受的范围内。