Kafka 3.x.x 入门到精通(06)——对标尚硅谷Kafka教程
- 3. Kafka进阶
- 3.1 Controller选举
- 3.2 Broker上线下线
- 3.3 数据偏移量定位
- 3.4 Topic删除
- 3.5 日志清理和压缩
- 3.7 页缓存
- 3.8 零拷贝
- 3.9 顺写日志
- 3.10 Linux集群部署
- 3.10.1 集群规划
- 3.10.2 安装虚拟机(略)
- 3.10.3 安装JDK1.8(略)
- 3.10.4 安装ZooKeeper
- 3.10.4.1 上传ZooKeeper压缩包
- 3.10.4.2 解压ZooKeeper压缩包
- 3.10.4.3 配置服务器编号
- 3.10.4.4 修改配置文件
- 3.10.4.5 启动ZooKeeper
- 3.10.4.6 关闭ZooKeeper
- 3.10.4.7 查看ZooKeeper状态
- 3.10.4.8 分发软件
- 3.10.4.9 启停脚本
- 3.10.5 安装Kafka(略)
- 3.10.6 测试集群
- 3.10.6.1 启动Kafka集群
- 3.10.6.2 查看Kafka状态
- 3.10.6.3关闭Kafka集群
- 3.11 Kafka-Eagle监控
- 3.11.1 MySQL环境准备
- 3.11.1.1 安装包准备
- 3.11.1.2 执行mysql安装
- 3.11.1.3 mysql的基本配置
- 3.11.2 修改Kafka集群配置
- 3.11.3 Kafka-Eagle安装
- 3.11.3.1 安装包准备
- 3.11.3.2 修改配置文件
- 3.11.3.3 添加环境变量
- 3.11.3.4 启动集群
- 3.11.3.5 登录页面查看监控数据
- 3.12 KRaft模式
- 3.12.1 kraft模式的优势
- 3.12.2 Kafka-KRaft集群部署
- 3.12.2.1 在三个节点解压kafka压缩包
- 3.12.2.2 修改config/kraft/server.properties配置文件
- 3.12.2.3 修改不同节点的配置
- 3.12.2.4 初始化集群数据目录
- 3.12.2.5 启停Kafka集群
- 3.12.2.6 启停脚本封装


本文档参看的视频是:
- 尚硅谷Kafka教程,2024新版kafka视频,零基础入门到实战
- 黑马程序员Kafka视频教程,大数据企业级消息队列kafka入门到精通
- 小朋友也可以懂的Kafka入门教程,还不快来学
本文档参看的文档是:
- 尚硅谷官方文档,并在基础上修改 完善!非常感谢尚硅谷团队!!!!
在这之前大家可以看我以下几篇文章,循序渐进:
❤️Kafka 3.x.x 入门到精通(01)——对标尚硅谷Kafka教程
❤️Kafka 3.x.x 入门到精通(02)——对标尚硅谷Kafka教程
❤️Kafka 3.x.x 入门到精通(03)——对标尚硅谷Kafka教程
❤️Kafka 3.x.x 入门到精通(04)——对标尚硅谷Kafka教程
❤️Kafka 3.x.x 入门到精通(05)——对标尚硅谷Kafka教程
3. Kafka进阶
3.1 Controller选举
Controller,是Apache Kafka的核心组件。它的主要作用是在Apache Zookeeper的帮助下管理和协调控制整个Kafka集群。
集群中的任意一台Broker都能充当Controller的角色,但是,在整个集群运行过程中,只能有一个Broker成为Controller。也就是说,每个正常运行的Kafka集群,在任何时刻都有且只有一个Controller。

最先在Zookeeper上创建临时节点/controller成功的Broker就是Controller。Controller重度依赖Zookeeper,依赖zookeepr保存元数据,依赖zookeeper进行服务发现。Controller大量使用Watch功能实现对集群的协调管理。如果此时,作为Controller的Broker节点宕掉了。那么zookeeper的临时节点/controller就会因为会话超时而自动删除。而监控这个节点的Broker就会收到通知而向ZooKeeper发出创建/controller节点的申请,一旦创建成功,那么创建成功的Broker节点就成为了新的Controller。

有一种特殊的情况,就是Controller节点并没有宕掉,而是因为网络的抖动,不稳定,导致和ZooKeeper之间的会话超时,那么此时,整个Kafka集群就会认为之前的Controller已经下线(退出)从而选举出新的Controller,而之前的Controller的网络又恢复了,以为自己还是Controller了,继续管理整个集群,那么此时,整个Kafka集群就有两个controller进行管理,那么其他的broker就懵了,不知道听谁的了.

集群脑裂~
这种情况,我们称之为脑裂现象,为了解决这个问题,Kafka通过一个任期(epoch:纪元)的概念来解决,也就是说,每一个Broker当选Controller时,会告诉当前Broker是第几任Controller,一旦重新选举时,这个任期会自动增1,那么不同任期的Controller的epoch值是不同的,那么旧的controller一旦发现集群中有新任controller的时候,那么它就会完成退出操作(清空缓存,中断和broker的连接,并重新加载最新的缓存),让自己重新变成一个普通的Broker。

3.2 Broker上线下线
Controller 在初始化时,会利用 ZK 的 watch 机制注册很多不同类型的监听器,当监听的事件被触发时,Controller 就会触发相应的操作。Controller 在初始化时,会注册多种类型的监听器,主要有以下几种:
- 监听
/admin/reassign_partitions节点,用于分区副本迁移的监听 - 监听
/isr_change_notification节点,用于 Partition ISR 变动的监听 - 监听
/admin/preferred_replica_election节点,用于需要进行Partition最优leader选举的监听 - 监听
/brokers/topics节点,用于 Topic 新建的监听 - 监听
/brokers/topics/TOPIC_NAME节点,用于 Topic Partition 扩容的监听 - 监听
/admin/delete_topics节点,用于 Topic 删除的监听 - 监听
/brokers/ids节点,用于 Broker 上下线的监听。
每台 Broker 在上线时,都会与ZK建立一个建立一个session,并在 /brokers/ids下注册一个节点,节点名字就是broker id,这个节点是临时节点,该节点内部会有这个 Broker 的详细节点信息。Controller会监听/brokers/ids这个路径下的所有子节点,如果有新的节点出现,那么就代表有新的Broker上线,如果有节点消失,就代表有broker下线,Controller会进行相应的处理,Kafka就是利用ZK的这种watch机制及临时节点的特性来完成集群 Broker的上下线。无论Controller监听到的哪一种节点的变化,都会进行相应的处理,同步整个集群元数据
3.3 数据偏移量定位
分区是一个逻辑工作单元,其中记录被顺序附加分区上 (kafka只能保证分区消息的有序性,而不能保证消息的全局有序性)。但是分区不是存储单元,分区进一步划分为Segment (段),这些段是文件系统上的实际文件。为了获得更好的性能和可维护性,可以创建多个段,而不是从一个巨大的分区中读取,消费者现在可以更快地从较小的段文件中读取。创建具有分区名称的目录,并将该分区的所有段作为各种文件进行维护。在理想情况下,数据流量分摊到各个Parition中,实现了负载均衡的效果。在分区日志文件中,你会发现很多类型的文件,比如: .index、.timeindex、.log等
每个数据日志文件会对用一个LogSegment对象,并且都有一个基准偏移量,表示当前 LogSegment 中第一条消息的偏移量offset。

偏移量是一个 64 位的长整形数,固定是20位数字,长度未达到,用 0 进行填补,索引文件和日志文件都由该作为文件名命名规则:
-
00000000000000000000.index:索引文件,记录偏移量映射到 .log 文件的字节偏移量,此映射用于从任何特定偏移量读取记录
-
0000000000000000000.timeindex:时间戳索引文件,此文件包含时间戳到记录偏移量的映射,该映射使用.index文件在内部映射到记录的字节偏移量。这有助于从特定时间戳访问记录
-
00000000000000000000.log:此文件包含实际记录,并将记录保持到特定偏移量,文件名描述了添加到此文件的起始偏移量,如果日志文件名为 00000000000000000004.log ,则当前日志文件的第一条数据偏移量就是4(偏移量从 0 开始)

多个数据日志文件在操作时,只有最新的日志文件处于活动状态,拥有文件写入和读取权限,其他的日志文件只有只读的权限。
偏移量索引文件用于记录消息偏移量与物理地址之间的映射关系。时间戳索引文件则根据时间戳查找对应的偏移量。Kafka 中的索引文件是以稀疏索引的方式构造消息的索引,并不保证每一个消息在索引文件中都有对应的索引项。每当写入一定量的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索引项。通过修改 log.index.interval.bytes的值,改变索引项的密度。
数据位置索引保存在index文件中,log日志默认每写入4K(log.index.interval.bytes设定的),会写入一条索引信息到index文件中,因此索引文件是稀疏索引,它不会为每条日志都建立索引信息,索引文件的数据结构则是由相对offset(4byte)+position(4byte)组成,由于保存的是相对第一个消息的相对offset,只需要4byte就可以,节省空间,实际查找后还需要计算回实际的offset,这对用户是不可见的。
如果消费者想要消费某一个偏移量的数据,那么Kafka会通过Kafka 中存在一个 ConcurrentSkipListMap(跳跃表)定位到00000000000000000000.index索引文件 ,通过二分法在偏移量索引文件中找到不大于指定偏移量的最大索引项,然后从日志分段文件中的物理位置开始顺序查找偏移量为指定值的消息。
3.4 Topic删除
kafka删除topic消息的三种方式:
- 方法一:快速配置删除法(确保topic数据不要了)
- kafka启动之前,在server.properties配置delete.topic.enable=true
- 执行命令bin/kafka-topics.sh --delete --topic test --zookeeper zk:2181或者使用kafka-manager集群管理工具删除
注意:如果kafka启动之前没有配置delete.topic.enable=true,topic只会标记为marked for deletion,加上配置,重启kafka,之前的topick就真正删除了。
- 方法二:设置删除策略(确保topic数据不要了)
- 请参考日志清理和压缩
- 方法三:手动删除法(不推荐)(确保topic数据不要了)
- 前提:不允许更改server.properties配置
- 删除zk下面topic(test)
- 启动bin/zkCli.sh
- ls /brokers/topics
- rmr /brokers/topics/test
- ls /brokers/topics
- 查topic是否删除:bin/kafka-topics.sh --list --zookeeper zk:2181
- 删除各broker下topic数据
3.5 日志清理和压缩
Kafka软件的目的本质是用于传输数据,而不是存储数据,但是为了均衡生产数据速率和消费者的消费速率,所以可以将数据保存到日志文件中进行存储。默认的数据日志保存时间为7天,可以通过调整如下参数修改保存时间:
- log.retention.hours:小时(默认:7天,最低优先级)
- log.retention.minutes,分钟
- log.retention.ms,毫秒(最高优先级)
- log.retention.check.interval.ms,负责设置检查周期,默认5分钟。
日志一旦超过了设置的时间,Kafka中提供了两种日志清理策略:delete和compact。
- delete:将过期数据删除
- log.cleanup.policy = delete(所有数据启用删除策略)
- 基于时间:默认打开。以segment中所有记录中的最大时间戳作为该文件时间戳。
- 基于大小:默认关闭。超过设置的所有日志总大小,删除最早的segment。
- log.retention.bytes,默认等于-1,表示无穷大。
- log.cleanup.policy = delete(所有数据启用删除策略)
思考:如果一个segment中有一部分数据过期,一部分没有过期,怎么处理?

- compact:日志压缩
- 基本思路就是将相同key的数据,只保留最后一个
- log.cleanup.policy = compact(所有数据启用压缩策略)

注意:因为数据会丢失,所以这种策略只适用保存数据最新状态的特殊场景。
3.7 页缓存
页缓存是操作系统实现的一种主要的磁盘缓存,以此用来减少对磁盘I/O的操作。具体来说,就是把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问。为了弥补性能上的差异 ,现代操作系统越来越多地将内存作为磁盘缓存,甚至会将所有可用的内存用于磁盘缓存,这样当内存回收时也几乎没有性能损失,所有对于磁盘的读写也将经由统一的缓存。
当一个进程准备读取磁盘上的文件内容时,操作系统会先查看待读取的数据所在的页(page)是否在页缓存(page cache)中,如果存在(命中)则直接返回数据,从而避免了对物理磁盘I/O操作;如果没有命中,则操作系统会向磁盘发起读取请示并将读取的数据页写入页缓存,之后再将数据返回进程。
同样,如果一个进程需要将数据写入磁盘,那么操作系统也会检测数据对应的页是否在页缓存中,如果不存在,则会先在页缓存中添加相应的页,最后将数据写入对应的页。被修改过后的页也就变成了脏页,操作系统会在合适的时间把脏页中的数据写入磁盘,以操作数据的一致性。
对一个进程页言,它会在进程内部缓存处理所需的数据,然而这些数据有可能还缓存在操作系统的页缓存中,因此同一份数据有可能被缓存了2次。并且,除非使用Direct I/O的方式,否则页缓存很难被禁止。
Kafka中大量使用了页缓存,这是Kafka实现高吞吐的重要因此之一。虽然消息都是先被写入页缓存,然后由操作系统负责具体的刷盘任务,但在Kafka中同样提供了同步刷盘及间断性强制刷盘(fsync)的功能,这些功能可以通过log.flush.interval.message、log.flush.interval.ms等参数来控制。
同步刷盘可以提高消息的可靠性,防止由于机器掉电等异常造成处于页缓存而没有及时写入磁盘的消息丢失。不过一般不建议这么做,刷盘任务就应交由操作系统去调配,消息的可靠性应该由多副本机制来保障,而不是由同步刷盘这种严重影响性能的行为来保障。
3.8 零拷贝

kafka的高性能是多方面协同的结果,包括宏观架构、分布式partition存储、ISR数据同步、以及“无所不用其极”的高效利用磁盘/操作系统特性。其中零拷贝并不是不需要拷贝,通常是说在IO读写过程中减少不必要的拷贝次数。
这里我们要说明是,内核在执行操作时同一时间点只会做一件事,比如Java写文件这个操作,为了提高效率,这个操作是分为3步:
- 第一步java将数据写入自己的缓冲区
- 第二步java需要写入数据的磁盘页可能就在当前的页缓存(Page Cache)中,所以
java需要将自己的缓冲区的数据写入操作系统的页缓存(Page Cache)中 - 第三步操作系统会在页缓存数据满了后,将数据实际刷写到磁盘文件中。

在这个过程,Java Application数据的写入和页缓存的数据刷写对于操作系统来讲是不一样的,可以简单理解为,页缓存的数据刷写属于内核的内部操作,而是用于启动的应用程序的数据操作属于内核的外部操作,权限会受到一定的限制。所以内核在执行不同操作时,就需要将不同的操作环境加载到执行空间中,也就是说,当java想要将数据写入页缓存时,就需要调用用户应用程序的操作,这就是用户态操作。当需要将页缓存数据写入文件时,就需要中断用户用用程序操作,而重新加载内部操作的运行环境,这就是内核态操作。可以想象,如果存在大量的用户态和内核态的切换操作,IO性能就会急剧下降。所以就存在零拷贝操作,减少用户态和内核态的切换,提高效率。Kafka消费者消费数据以及Follower副本同步数据就采用的是零拷贝技术。



3.9 顺写日志
Kafka 中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向 topic的。在Kafka中,一个topic可以分为多个partition,一个partition分为多个segment,每个 segment对应三个文件:.index文件、.log文件、.timeindex文件。
topic 是逻辑上的概念,而patition是物理上的概念,每个patition对应一个log文件,而log文件中存储的就是producer生产的数据,patition生产的数据会被不断的添加到log文件的末端,且每条数据都有自己的offset。

Kafka底层采用的是FileChannel.wrtieTo进行数据的写入,写的时候并不是直接写入文件,而是写入ByteBuffer,然后当缓冲区满了,再将数据顺序写入文件,无需定位文件中的某一个位置进行写入,那么就减少了磁盘查询,数据定位的过程。所以性能要比随机写入,效率高得多。
官网有数据表明,同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。这与磁盘的机械结构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。

3.10 Linux集群部署
Kafka从早期的消息传输系统转型为开源分布式事件流处理平台系统,所以很多核心组件,核心操作都是基于分布式多节点的,所以我们这里把分布式软件环境安装一下。
3.10.1 集群规划
| 服务节点 | kafka-broker1 | kafka-broker2 | kafka-broker3 |
|---|---|---|---|
| 服务进程 | QuorumPeerMain | QuorumPeerMain | QuorumPeerMain |
| 服务进程 | Kafka | Kafka | Kafka |
3.10.2 安装虚拟机(略)
安装虚拟机(VMware)保姆级教程(附安装包)
3.10.3 安装JDK1.8(略)
3.10.4 安装ZooKeeper
3.10.4.1 上传ZooKeeper压缩包
将apache-zookeeper-3.7.1-bin.tar.gz文件上传到三台虚拟机的/opt/software目录中

3.10.4.2 解压ZooKeeper压缩包
# 进入到/opt/software目录中
cd /opt/software/
# 解压缩文件到指定目录
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module/
# 进入/opt/module目录
cd /opt/module
# 文件目录改名
mv apache-zookeeper-3.7.1-bin/ zookeeper
3.10.4.3 配置服务器编号
(1) 在/opt/module/zookeeper/目录下创建zkData
# 进入/opt/module/zookeeper目录
cd /opt/module/zookeeper
# 创建zkData文件目录
mkdir zkData
(2) 创建myid文件
# 进入/opt/module/zookeeper/zkData目录
cd /opt/module/zookeeper/zkData
# 创建myid文件
vim myid
3.10.4.4 修改配置文件
(1) 重命名/opt/module/zookeeper/conf目录下的zoo_sample.cfg文件为zoo.cfg文件
# 进入cd /opt/module/zookeeper/conf文件目录
cd /opt/module/zookeeper/conf
# 修改文件名称
mv zoo_sample.cfg zoo.cfg
# 修改文件内容
vim zoo.cfg
(2) 修改zoo.cfg文件
# 以下内容为修改内容
dataDir=/opt/module/zookeeper/zkData
# 以下内容为新增内容
####################### cluster ##########################
# server.A=B:C:D
#
# A是一个数字,表示这个是第几号服务器
# B是A服务器的主机名
# C是A服务器与集群中的主服务器(Leader)交换信息的端口
# D是A服务器用于主服务器(Leader)选举的端口
#########################################################
server.1=kafka-broker1:2888:3888
server.2=kafka-broker2:2888:3888
server.3=kafka-broker3:2888:3888
3.10.4.5 启动ZooKeeper
# 在每个节点下执行如下操作
# 进入zookeeper目录
cd /opt/module/zookeeper
# 启动ZK服务
bin/zkServer.sh start
3.10.4.6 关闭ZooKeeper
# 在每个节点下执行如下操作
# 进入zookeeper目录
cd /opt/module/zookeeper
# 关闭ZK服务
bin/zkServer.sh stop
3.10.4.7 查看ZooKeeper状态
# 在每个节点下执行如下操作
# 进入zookeeper目录
cd /opt/module/zookeeper
# 查看ZK服务状态
bin/zkServer.sh status
3.10.4.8 分发软件
# 进入/opt/module路径
cd /opt/module
# 调用分发脚本将本机得ZooKeeper安装包分发到其他两台机器
xsync zookeeper
# 分别将不同虚拟机/opt/module/zookeeper/zkData目录下myid文件进行修改
vim /opt/module/zookeeper/zkData/myid
# kafka-broker1:1
# kafka-broker2:2
# kafka-broker3:3
3.10.4.9 启停脚本
ZooKeeper软件的启动和停止比较简单,但是每一次如果都在不同服务器节点执行相应指令,也会有点麻烦,所以我们这里将指令封装成脚本文件,方便我们的调用。
(5) 在虚拟机kafka-broker1的/root/bin目录下创建zk.sh脚本文件
在/root/bin这个目录下存放的脚本,root用户可以在系统任何地方直接执行
# 进入/root/bin目录
cd /root/bin
# 创建zk.sh脚本文件
vim zk.sh
在脚本中增加内容:
#!/bin/bash
case $1 in
"start"){
for i in kafka-broker1 kafka-broker2 kafka-broker3
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper/bin/zkServer.sh start"
done
};;
"stop"){
for i in kafka-broker1 kafka-broker2 kafka-broker3
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper/bin/zkServer.sh stop"
done
};;
"status"){
for i in kafka-broker1 kafka-broker2 kafka-broker3
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper/bin/zkServer.sh status"
done
};;
esac
(6) 增加脚本文件权限
# 给zk.sh文件授权
chmod 777 zk.sh
(7) 脚本调用方式
# 启动ZK服务
zk.sh start
# 查看ZK服务状态
zk.sh status
# 停止ZK服务
zk.sh stop
3.10.5 安装Kafka(略)
3.10.6 测试集群
3.10.6.1 启动Kafka集群
因为已经将ZooKeeper和Kafka的启动封装为脚本,所以可以分别调用脚本启动或调用集群脚本启动
# 启动集群
cluster.sh start
```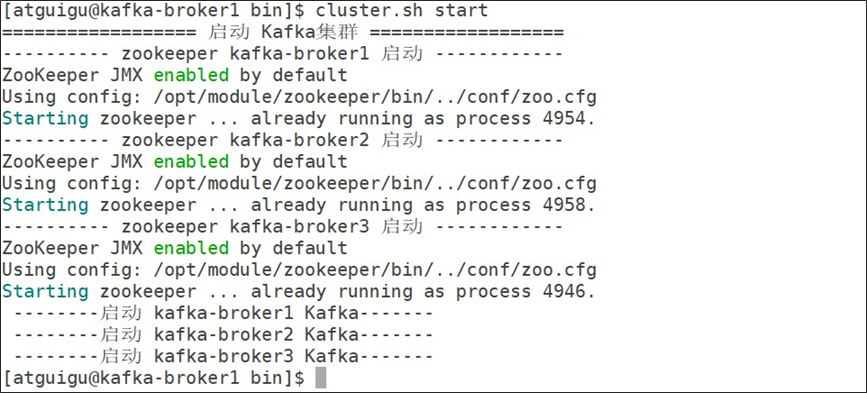
输入指令查看进程
```java
# xcall 后面跟着linux指令操作,可以同时对多个服务器节点同时执行相同指令
xcall jps

3.10.6.2 查看Kafka状态
使用客户端工具访问kafka


3.10.6.3关闭Kafka集群
# 关闭集群
cluster.sh stop
# 查看进程
xcall jps


3.11 Kafka-Eagle监控
Kafka-Eagle框架可以监控Kafka集群的整体运行情况,在生产环境中经常使用。
3.11.1 MySQL环境准备
Kafka-Eagle的安装依赖于MySQL,MySQL主要用来存储可视化展示的数据。如果集群中之前安装过MySQL可以跳过该步骤。
3.11.1.1 安装包准备
将资料里mysql文件夹及里面所有内容上传到虚拟机/opt/software/mysql目录下
# 文件清单
install_mysql.sh
mysql-community-client-8.0.31-1.el7.x86_64.rpm
mysql-community-client-plugins-8.0.31-1.el7.x86_64.rpm
mysql-community-common-8.0.31-1.el7.x86_64.rpm
mysql-community-icu-data-files-8.0.31-1.el7.x86_64.rpm
mysql-community-libs-8.0.31-1.el7.x86_64.rpm
mysql-community-libs-compat-8.0.31-1.el7.x86_64.rpm
mysql-community-server-8.0.31-1.el7.x86_64.rpm
mysql-connector-j-8.0.31.jar
3.11.1.2 执行mysql安装
# 进入/opt/software/mysql目录
cd /opt/software/mysql
# 执行install_mysql.sh
sh install_mysql.sh
# 安装得过程略慢,请耐心等候
3.11.1.3 mysql的基本配置
#!/bin/bash
set -x
[ "$(whoami)" = "root" ] || exit 1
[ "$(ls *.rpm | wc -l)" = "7" ] || exit 1
test -f mysql-community-client-8.0.31-1.el7.x86_64.rpm && \
test -f mysql-community-client-plugins-8.0.31-1.el7.x86_64.rpm && \
test -f mysql-community-common-8.0.31-1.el7.x86_64.rpm && \
test -f mysql-community-icu-data-files-8.0.31-1.el7.x86_64.rpm && \
test -f mysql-community-libs-8.0.31-1.el7.x86_64.rpm && \
test -f mysql-community-libs-compat-8.0.31-1.el7.x86_64.rpm && \
test -f mysql-community-server-8.0.31-1.el7.x86_64.rpm || exit 1
# 卸载MySQL
systemctl stop mysql mysqld 2>/dev/null
rpm -qa | grep -i 'mysql\|mariadb' | xargs -n1 rpm -e --nodeps 2>/dev/null
rm -rf /var/lib/mysql /var/log/mysqld.log /usr/lib64/mysql /etc/my.cnf /usr/my.cnf
set -e
# 安装并启动MySQL
yum install -y *.rpm >/dev/null 2>&1
systemctl start mysqld
#更改密码级别并重启MySQL
sed -i '/\[mysqld\]/avalidate_password.length=4\nvalidate_password.policy=0' /etc/my.cnf
systemctl restart mysqld
# 更改MySQL配置
tpass=$(cat /var/log/mysqld.log | grep "temporary password" | awk '{print $NF}')
cat << EOF | mysql -uroot -p"${tpass}" --connect-expired-password >/dev/null 2>&1
set password='000000';
update mysql.user set host='%' where user='root';
alter user 'root'@'%' identified with mysql_native_password by '000000';
flush privileges;
EOF
安装成功后,Mysql的root用户的密码被修改为000000,请连接mysql客户端后,确认root用户的密码插件为下图所示内容。
select user,host,plugin from mysql.user;
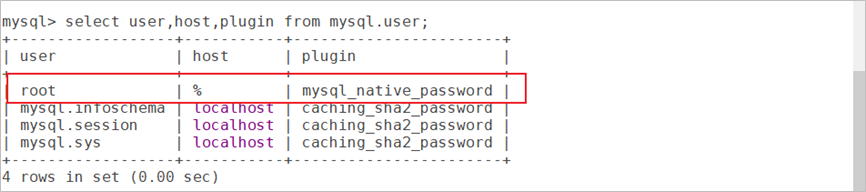
如果插件与截图不同,请登录MySQL客户端后重试下列SQL,否则无法远程登录
update mysql.user set host='%' where user='root';
alter user 'root'@'%' identified with mysql_native_password by '000000';
flush privileges;
exit;
# 退出后,请重新登录后进行确认
3.11.2 修改Kafka集群配置
修改/opt/module/kafka/bin/kafka-server-start.sh脚本文件中的内容
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
注意:每个节点都要进行修改。
# 分发修改后得文件
xsync /opt/module/kafka/bin/kafka-server-start.sh
3.11.3 Kafka-Eagle安装
3.11.3.1 安装包准备
将kafka-eagle-bin-3.0.1.tar.gz上传到虚拟机/opt/software目录下,并解压缩
# 进入到software文件目录
cd /opt/software
# 解压缩文件
tar -zxvf kafka-eagle-bin-3.0.1.tar.gz
# 进入解压缩目录,目录中包含efak-web-3.0.1-bin.tar.gz
cd /opt/software/kafka-eagle-bin-3.0.1
# 解压缩efal压缩文件
tar -zxvf efak-web-3.0.1-bin.tar.gz -C /opt/module/
# 修改名称
cd /opt/module
mv efak-web-3.0.1 efak
3.11.3.2 修改配置文件
修改/opt/module/efak/conf/system-config.properties文件
######################################
# multi zookeeper & kafka cluster list
# Settings prefixed with 'kafka.eagle.' will be deprecated, use 'efak.' instead
######################################
efak.zk.cluster.alias=cluster1
cluster1.zk.list=kafka-broker1:2181,kafka-broker2:2181,kafka-broker3:2181/kafka
######################################
# zookeeper enable acl
######################################
cluster1.zk.acl.enable=false
cluster1.zk.acl.schema=digest
cluster1.zk.acl.username=test
cluster1.zk.acl.password=test
######################################
# broker size online list
######################################
cluster1.efak.broker.size=20
######################################
# zk client thread limit
######################################
kafka.zk.limit.size=32
######################################
# EFAK webui port
######################################
efak.webui.port=8048
######################################
# kafka jmx acl and ssl authenticate
######################################
cluster1.efak.jmx.acl=false
cluster1.efak.jmx.user=keadmin
cluster1.efak.jmx.password=keadmin123
cluster1.efak.jmx.ssl=false
cluster1.efak.jmx.truststore.location=/data/ssl/certificates/kafka.truststore
cluster1.efak.jmx.truststore.password=ke123456
######################################
# kafka offset storage
######################################
cluster1.efak.offset.storage=kafka
######################################
# kafka jmx uri
######################################
cluster1.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi
######################################
# kafka metrics, 15 days by default
######################################
efak.metrics.charts=true
efak.metrics.retain=15
######################################
# kafka sql topic records max
######################################
efak.sql.topic.records.max=5000
efak.sql.topic.preview.records.max=10
######################################
# delete kafka topic token
######################################
efak.topic.token=keadmin
######################################
# kafka sasl authenticate
######################################
cluster1.efak.sasl.enable=false
cluster1.efak.sasl.protocol=SASL_PLAINTEXT
cluster1.efak.sasl.mechanism=SCRAM-SHA-256
cluster1.efak.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka" password="kafka-eagle";
cluster1.efak.sasl.client.id=
cluster1.efak.blacklist.topics=
cluster1.efak.sasl.cgroup.enable=false
cluster1.efak.sasl.cgroup.topics=
cluster2.efak.sasl.enable=false
cluster2.efak.sasl.protocol=SASL_PLAINTEXT
cluster2.efak.sasl.mechanism=PLAIN
cluster2.efak.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="kafka" password="kafka-eagle";
cluster2.efak.sasl.client.id=
cluster2.efak.blacklist.topics=
cluster2.efak.sasl.cgroup.enable=false
cluster2.efak.sasl.cgroup.topics=
######################################
# kafka ssl authenticate
######################################
cluster3.efak.ssl.enable=false
cluster3.efak.ssl.protocol=SSL
cluster3.efak.ssl.truststore.location=
cluster3.efak.ssl.truststore.password=
cluster3.efak.ssl.keystore.location=
cluster3.efak.ssl.keystore.password=
cluster3.efak.ssl.key.password=
cluster3.efak.ssl.endpoint.identification.algorithm=https
cluster3.efak.blacklist.topics=
cluster3.efak.ssl.cgroup.enable=false
cluster3.efak.ssl.cgroup.topics=
######################################
# kafka sqlite jdbc driver address
######################################
# 配置mysql连接
efak.driver=com.mysql.jdbc.Driver
efak.url=jdbc:mysql://kafka-broker1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=000000
######################################
# kafka mysql jdbc driver address
######################################
#efak.driver=com.mysql.cj.jdbc.Driver
#efak.url=jdbc:mysql://kafka-broker1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
#efak.username=root
#efak.password=123456
3.11.3.3 添加环境变量
创建/etc/profile.d/my_env.sh脚本文件
#创建脚本文件
vim /etc/profile.d/my_env.sh
# 增加如下内容
# kafkaEFAK
export KE_HOME=/opt/module/efak
export PATH=$PATH:$KE_HOME/bin
# 刷新环境变量
source /etc/profile.d/my_env.sh
3.11.3.4 启动集群
- 启动ZooKeeper,Kafka集群
# 启动集群
cluster.sh start
- 启动efak
# 进入efak文件目录
cd /opt/module/efak
# 启动efak
bin/ke.sh start
# 停止efak
bin/ke.sh stop

3.11.3.5 登录页面查看监控数据
http://kafka-broker1:8048/

账号为admin,密码为123456



3.12 KRaft模式
Kafka作为一种高吞吐量的分布式发布订阅消息系统,在消息应用中广泛使用,尤其在需要实时数据处理和应用程序活动跟踪的场景,kafka已成为首选服务。在Kafka2.8之前,Kafka强依赖zookeeper来负责集群元数据的管理,这也导致当Zookeeper集群性能发生抖动时,Kafka的性能也会收到很大的影响。2.8版本之后,kafka开始提供KRaft(Kafka Raft,依赖Java 8+ )模式,开始去除对zookeeper的依赖。最新的3.6.1版本中,Kafka依然兼容zookeeper Controller,但Kafka Raft元数据模式,已经可以在不依赖zookeeper的情况下独立启动Kafka了。官方预计会在Kafka 4.0中移除ZooKeeper,让我们拭目以待。

3.12.1 kraft模式的优势
- 更简单的部署和管理——通过只安装和管理一个应用程序,无需安装更多的软件,简化软件的安装部署。这也使得在边缘的小型设备中更容易利用 Kafka。
- 提高可扩展性——KRaft 的恢复时间比 ZooKeeper 快一个数量级。这使我们能够有效地扩展到单个集群中的数百万个分区。ZooKeeper 的有效限制是数万
- 更有效的元数据传播——基于日志、事件驱动的元数据传播可以提高 Kafka 的许多核心功能的性能。另外它还支持元数据主题的快照。
- 由于不依赖zookeeper,集群扩展时不再受到zookeeper读写能力限制;
- controller不再动态选举,而是由配置文件规定。这样我们可以有针对性的加强controller节点的配置,而不是像以前一样对随机controller节点的高负载束手无策。
3.12.2 Kafka-KRaft集群部署
3.12.2.1 在三个节点解压kafka压缩包
# 进入software目录
cd /opt/software
# 解压缩文件
tar -zxvf kafka_2.12-3.6.1.tgz -C /opt/module/
# 修改名称
mv /opt/module/kafka_2.12-3.6.1/ /opt/module/kafka-kraft
3.12.2.2 修改config/kraft/server.properties配置文件
#kafka的角色(controller相当于主机、broker节点相当于从机,主机类似zk功能)
process.roles=broker, controller
#节点ID
node.id=1
#controller服务协议别名
controller.listener.names=CONTROLLER
#全Controller列表
controller.quorum.voters=1@kafka-broker1:9093,2@kafka-broker2:9093,3@kafka-broker3:9093
#不同服务器绑定的端口
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
#broker服务协议别名
inter.broker.listener.name=PLAINTEXT
#broker对外暴露的地址
advertised.listeners=PLAINTEXT://kafka-broker1:9092
#协议别名到安全协议的映射
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
#kafka数据存储目录
log.dirs=/opt/module/kafka-kraft/datas
3.12.2.3 修改不同节点的配置
# 分发软件
xsync /opt/module/kafka-kraft
# 不同节点需要对node.id相应改变,值需要和controller.quorum.voters对应
# 不同节点需要根据各自的主机名称,修改相应的advertised.listeners地址。
3.12.2.4 初始化集群数据目录
- 首先在每个部署节点生成存储目录唯一ID
# 进入kafka目录
cd /opt/module/kafka-kraft
# 生产存储ID
bin/kafka-storage.sh random-uuid
J7s9e8PPTKOO47PxzI39VA
- 用生成的ID格式化每一个kafka数据存储目录
bin/kafka-storage.sh format -t J7s9e8PPTKOO47PxzI39VA -c /opt/module/kafka-kraft/config/kraft/server.properties
3.12.2.5 启停Kafka集群
# 进入到/opt/module/kafka-kraft目录
cd /opt/module/kafka-kraft
# 执行启动脚本
bin/kafka-server-start.sh -daemon config/kraft/server.properties
# 执行停止命令
bin/kafka-server-stop.sh
3.12.2.6 启停脚本封装
- 在/root/bin目录下创建脚本文件kfk2.sh,并增加内容
#! /bin/bash
case $1 in
"start"){
for i in kafka-broker1 kafka-broker2 kafka-broker3
do
echo " --------启动 $i kafka-kraft -------"
ssh $i "/opt/module/kafka-kraft/bin/kafka-server-start.sh -daemon /opt/module/kafka-kraft/config/kraft/server.properties"
done
};;
"stop"){
for i in kafka-broker1 kafka-broker2 kafka-broker3
do
echo " --------停止 $i kafka-kraft -------"
ssh $i "/opt/module/kafka-kraft/bin/kafka-server-stop.sh "
done
};;
esac
- 添加执行权限
# 添加权限
chmod 777 kfk2.sh
- 启动和停止集群
# 启动集群
kfk2.sh start
# 停止集群
kfk2.sh stop






![[Linux][网络][网络基础][协议][网络传输基本流程][数据包封装和分用]详细讲解](https://img-blog.csdnimg.cn/direct/86599aa4326c4035964db029f7d254b4.png)