前言
在 正则表达式 - 匹配开头、结尾、中间 - 某天气网站网页源代码分析 这篇文章里,我们介绍了如何用正则表达式匹配包含特定样式的Table标签,也就是同时匹配开头、结尾、以及中间。
当你能真正理解这个写法,就会觉得不过是柳暗花明罢了。是的,现实往往如此 —— 屡败屡战的过程最难将书,结果最易轻描淡写,只剩下予取予求的招数变化。
所以接下来,我们要做的就是复制这个成功经验,把之前那些“2步走方案”实现的匹配替换,全部改为“1步到位”方案 —— 性能且不说,我们先追求代码简洁度,开搞。
正文
限定范围 精准打击
regex101 网站有提供1个对理解正则表达式运作过程非常有用的工具:Regex Debugger。我简单录了个视频,有兴趣的同学可以自己去研究。
正则表达式运行过程
这里想表达的是,我们可能不需要理解正则的原理,就向开车没必要懂车构造一样。但有一点需要清楚的是:匹配就是寻找,在小范围内寻找一定比在大范围内寻找要快。
基于这个铁律,看下我们的代码逻辑,即使是在剔除“假Table”后,几乎每个正则也还是在做全文匹配,寻找 td,寻找 th 等等等等 —— 而我们的目标范围其实很明确,就是在剩余的这个 “真Table” 中,所以其实没有必要对 html 内 table 外 的其他任何内容去做任何匹配了。
我们用1个正则将“真Table” —— <table></table> 标签内的东西提取,保存,将后续所有的匹配限定在这个范围。(其实可以进一步缩小到 <tbody></tbody>,甚至贪婪匹配从第1个 <tr> 到最后1个 </tr>之间). 得到这样的代码。让 tbm_table 而不是 page_source, 成为我们的最新目标。
# limit match scope, table to be matched
regex_tbm_table = r"<tbody>([\s\S]*?)<\/tbody>"
tbm_table = re.findall(regex_tbm_table, page_source)[0]
###
# 中间是对这个 “真table” 的进一步处理
###
# 将处理好的 table 再填充回 html 代码
page_source = re.sub(regex_tbm_table, tbm_table, page_source)鸟枪换炮 重装出击
这篇 爬虫攻守道 - 2023最新 - Python Selenium 实现 - 数据去伪存真,正则表达式谁与争锋 - 爬取某天气网站历史数据 留下的第1条 Todo ,是我们的第1个目标。
之前为了替换掉包含4种隐藏样式的td,我们先是正则得到td,然后for 循环全部 td,再次正则找出匹配然后 replace 为空。忽略打印测试,我们用了21行代码来达到这个目标。
# 在保留的 table 中匹配出所有的 td
regex_td = r"<td.*?\/td>"
tds = re.findall(regex_td, page_source)
print('{}_{}: total {} tds been found'.format(city, month, len(tds)))
# 将包含 display:none 隐藏样式的 td 其实就是假数据,替换为空
# display:none 是最终效果,实际在代码里是随机字符串,而且好几个,所以先找到 css 定义中内容为 display:none 的样式名称
regex_td_css1 = r"(.*?)\s*{\n\s*display: none;"
class_ndisplays = re.findall(regex_td_css1, page_source)
# print('class_ndisplays', len(class_ndisplays))
# 将包含这些样式的 td 替换为空
for class_ndisplay in class_ndisplays:
class_ndisplay = class_ndisplay.replace('.', '').strip()
for td in tds:
if re.findall(class_ndisplay, td):
page_source = page_source.replace(td, '')
# 将包含明文 display:none 样式的 td 替换为空
regex_td_css2 = r"display:none"
for td in tds:
if re.findall(regex_td_css2, td):
page_source = page_source.replace(td, '')
# 将包含 hidden-lg 隐藏样式的 td 其实就是假数据,替换为空
regex_td_css3 = "hidden-lg"
for td in tds:
if re.findall(regex_td_css3, td):
page_source = page_source.replace(td, '')
regex_td_css4 = r"\"hidden\""
for td in tds:
if re.findall(regex_td_css4, td):
page_source = page_source.replace(td, '')让我们看看 21行最终能简化到几行。
第1步:先打出头鸟。
比其他3个样式都复杂的 regex_td_css1,原先的处理逻辑是先根据 css定义的形式 —— {}包裹,以及内容为 display: none 的 —— 反向提取得到名称。然后再到td 范围内匹配 css引用名称,进而替换。
以我目前极为有限的前端知识 —— 提取名称这步是绕不开的,但是css 引用都是定义在 <style></style> 标签内的。所以按照缩小范围精准打击的思路,我们先得到<style></style> 标签内的东西,代号为 tbm_style,然后在这个小范围内得到被引用的 css样式名称,依然是1个随机字符串列表。
再下来,我们用1次 for 循环,在 tbm_table 范围内把这些名称全部替换为 和 regex_td_css2 一致的明文 display:none。 经过这样“合并”处理后,即使还需要 for 循环全部 td,我们也只需要3次 (针对 regex_td_css2,regex_td_css3,regex_td_css4)。于是得到这样的代码:
# 处理 regex_td_css1
# css 引用样式在 <style></style> 中定义
regex_tbm_style = r"<style([\s\S]*?)<\/style>"
tbm_style = re.findall(regex_tbm_style, page_source)[0]
regex_td_css1 = r"(.*?)\s*{\n\s*display: none;"
class_ndisplays = re.findall(regex_td_css1, tbm_style)
# print('class_ndisplays', len(class_ndisplays))
# 将 table 内对这些样式的引用。替换为明文 display:none
# 加1个 total_count 用作调试辅助,观察次数
total_count = 0
for class_ndisplay in class_ndisplays:
class_ndisplay = class_ndisplay.replace('.', '').strip()
tbm_table, count = re.subn(class_ndisplay, r'display:none', tbm_table)
total_count = total_count + count
print('{}_{}: total {} css quotations been replaced.'.format(city, month, total_count))第2步,鸟枪换炮。
此鸟非彼鸟。直接在全文种寻找满足条件的td,然后re.sub,干掉 for 循环。前提就是写出这种一般人没耐心真看不懂的正则表达式,当然还需要得心应手的测试和验证工具
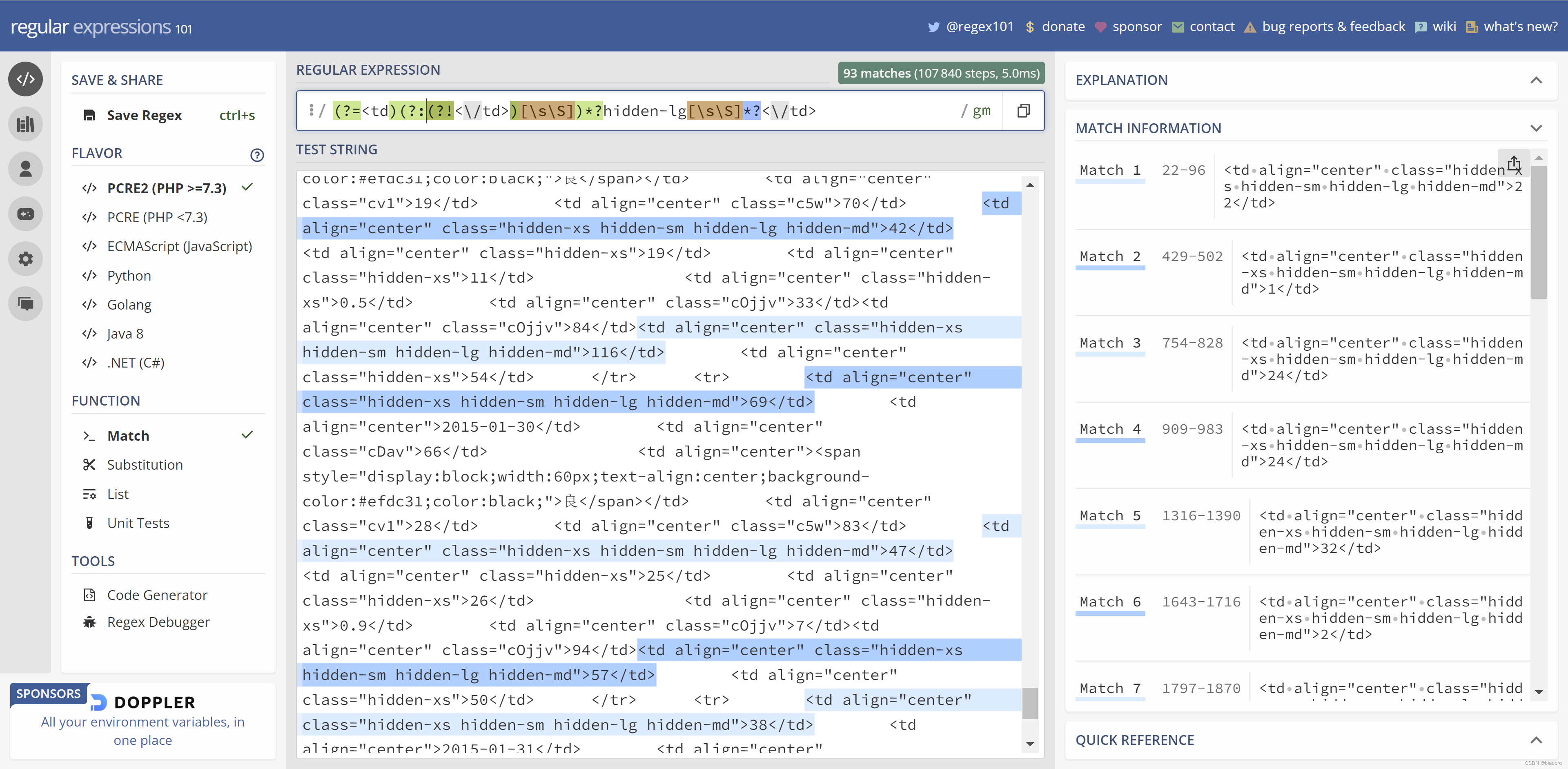
于是得到这样的代码。不算打印的话,原先每个样式4行代码,现在变成了2行。我们使用13行代码完成了原先21行代码才能完成的工作。
# 形式:class="display:none"
regex_css2_td = r"(?=<td)(?:(?!<\/td>)[\s\S])*?display:none[\s\S]*?<\/td>"
tbm_table, count_css2 = re.subn(regex_css2_td, '', tbm_table)
print('{}_{}: total {} css2:display:none been replaced. {} left.'.format(city, month, count_css2, len(tds)-count_css2))
# 形式:class="hidden-xs hidden-sm hidden-lg hidden-md" —— hidden-lg 是其中之一
regex_css3_td = r"(?=<td)(?:(?!<\/td>)[\s\S])*?hidden-lg[\s\S]*?<\/td>"
tbm_table, count_css3 = re.subn(regex_css3_td, '', tbm_table)
print('{}_{}: total {} css3:hidden-lg been replaced. {} left.'.format(city, month, count_css3, len(tds)-count_css2-count_css3))
# 形式:class="hidden" —— hidden 就1个,所以加上前后引号,否则和 css1 无法区分
regex_css4_td = r"(?=<td)(?:(?!<\/td>)[\s\S])*?\"hidden\"[\s\S]*?<\/td>"
tbm_table, count_css4 = re.subn(regex_css4_td, '', tbm_table)
print('{}_{}: total {} css4:hidden been replaced. {} left.'.format(city, month, count_css4, len(tds)-count_css2-count_css3-count_css4))
更进一步,还有1种更为牛逼、更为疯狂的写法,re.subn 的第1个参数支持多种不同的匹配规则,中间以 | 分隔,这样最终的有效代码行数来到了12行。
# 形式:class="display:none"
regex_css_rule2 = r"(?=<td)(?:(?!<\/td>)[\s\S])*?display:none[\s\S]*?<\/td>"
# 形式:class="hidden-xs hidden-sm hidden-lg hidden-md" —— hidden-lg 是其中之一
regex_css_rule3 = r"(?=<td)(?:(?!<\/td>)[\s\S])*?hidden-lg[\s\S]*?<\/td>"
# 形式:class="hidden" —— hidden 就1个,所以加上前后引号,否则和 css1 无法区分
regex_css_rule4 = r"(?=<td)(?:(?!<\/td>)[\s\S])*?\"hidden\"[\s\S]*?<\/td>"
regex_css_invincible = regex_css_rule2 + '|' + regex_css_rule3 + '|' + regex_css_rule4
tbm_table, total_count = re.subn(regex_css_invincible, '', tbm_table)
print('{}_{}: {} hidden css been replaced.'.format(city, month, total_count))其他诸如 th 替换成 td,span 替换的正常逻辑保留不变。
为了调试需要,我们还是保留了对 td 的匹配,但是现在只是为了统计处理前后的数量变化,不再参与替换。最终用于处理 table 的终极代码如下 —— 记忆力不好,写了很多注释,大家谅解。
start_time = time.time()
print("{}_{} html page source get successfully,process start".format(city, month))
# 为了便于对照,根据拿到 page_source 的时间,先保留1份原始文本,
response_time = time.strftime("%Y%m%d%H%M%S")
with open("{}_{}_{}_original.html".format(city, month, response_time), 'w', encoding='utf-8') as f:
f.write(page_source)
# 可以先移除Script 中的eval,否则太长了,移除后 size 会减少很多
# 正则匹配也是运算,应该尽可能减小匹配范围
regex_script = r"eval\(.*"
page_source = re.sub(regex_script, '', page_source)
# 样式中没有设置 position 的Table,就是包含真实数据的,保留
# 另外2个 替换为空,使用一步到位的正则表达式
re_one_step = r"(?=<table)(?:(?!>)[\s\S])*?position[\s\S]*?(?<=<\/table>)"
page_source, count = re.subn(re_one_step, '', page_source)
print('{}_{}: {} fake tables been removed.'.format(city, month, count))
with open("{}_{}_{}_removefaketable.html".format(city, month, response_time), 'w', encoding='utf-8') as f:
f.write(page_source)
# limit match scope, table to be matched
regex_tbm_table = r"<tbody>([\s\S]*?)<\/tbody>"
tbm_table = re.findall(regex_tbm_table, page_source)[0]
###
# 中间是对这个 “真table” 的进一步处理
###
# 表头也是包含了伪造数据的,也需要剔除 表头通过2种形式提供,
# 一种是放在 td 里的,可以和数据一起处理
# 另一种是放在 th 里,所以还需要增加 th 的匹配判断
# 保留下来的 Table 中, td 是一定有的,th 不一定有
# 最简单的方式就是把 th 替换为 td,这样就不用在 th 里依次判断4种隐藏样式
regex_th = r"<th(.*?)th>"
# 无论最终是否执行替换,正则匹配都会执行。所以可以直接执行 re.subn
# 正则匹配后得到match,如果其中有闭合的(),就会生成 group
# 正则将<thth>之间的内容匹配出来,得到分组,用\1表示
# 将匹配结果,保留分组内容,两端替换为td的开合标签
tbm_table, count = re.subn(regex_th, r"<td\1td>", tbm_table)
if count > 0:
print(
'{}_{}: field names been found in <th></th>, {} ths been replaced.'.format(city, month, count))
# 在保留的 table 中匹配出所有的 td
# 在经过终极优化的代码中,这部分已经没有必要了,这里保留为了调试观察
regex_td = r"<td.*?\/td>"
tds = re.findall(regex_td, tbm_table)
print('{}_{}: {} tds been found'.format(city, month, len(tds)))
# 处理 regex_td_css1
# css 引用样式在 <style></style> 中定义
regex_tbm_style = r"<style([\s\S]*?)<\/style>"
tbm_style = re.findall(regex_tbm_style, page_source)[0]
regex_css_rule1 = r"(.*?)\s*{\n\s*display: none;"
class_ndisplays = re.findall(regex_css_rule1, tbm_style)
# print('class_ndisplays', len(class_ndisplays))
# 将 table 内对这些样式的引用。替换为明文 display:none
total_count = 0
for class_ndisplay in class_ndisplays:
class_ndisplay = class_ndisplay.replace('.', '').strip()
tbm_table, count = re.subn(class_ndisplay, r'display:none', tbm_table)
total_count = total_count + count
print('{}_{}: {} css1:quotation been replaced to css2.'.format(city, month, total_count))
# 形式:class="display:none"
regex_css_rule2 = r"(?=<td)(?:(?!<\/td>)[\s\S])*?display:none[\s\S]*?<\/td>"
# tbm_table, count_css2 = re.subn(regex_css_rule2, '', tbm_table)
# print('{}_{}: {} css2:display:none been replaced to empty. {} left.'.format(city, month, count_css2, len(tds)-count_css2))
# 形式:class="hidden-xs hidden-sm hidden-lg hidden-md" —— hidden-lg 是其中之一
regex_css_rule3 = r"(?=<td)(?:(?!<\/td>)[\s\S])*?hidden-lg[\s\S]*?<\/td>"
# tbm_table, count_css3 = re.subn(regex_css_rule3, '', tbm_table)
# print('{}_{}: {} css3:hidden-lg been replaced to empty. {} left.'.format(city, month, count_css3, len(tds)-count_css2-count_css3))
# 形式:class="hidden" —— hidden 就1个,所以加上前后引号,否则和 css1 无法区分
regex_css_rule4 = r"(?=<td)(?:(?!<\/td>)[\s\S])*?\"hidden\"[\s\S]*?<\/td>"
# tbm_table, count_css4 = re.subn(regex_css_rule4, '', tbm_table)
# print('{}_{}: {} css4:hidden been replaced to empty. {} left.'.format(city, month, count_css4, len(tds)-count_css2-count_css3-count_css4))
regex_css_invincible = regex_css_rule2 + '|' + regex_css_rule3 + '|' + regex_css_rule4
tbm_table, total_count = re.subn(regex_css_invincible, '', tbm_table)
print('{}_{}: {} hidden css been replaced.'.format(city, month, total_count))
# 质量等级 是在 td 内部又包了1层 span 标签,为了和其他数据统一逻辑,
# 我们把包含span 的 td 找出来,直接替换成 <td>质量等级</td>
# 正则会得到3个分组,质量等级文本是第3个分组
regex_span = r"(?=<td)((?!<\/td>)[\s\S])*(<span[\s\S]*?>(.*?)<\/span>)<\/td>"
tbm_table, count = re.subn(regex_span, r'<td>\3</td>', tbm_table)
print('{}_{}: {} spans been processed'.format(city, month, count))
# 可选,再次匹配得到的是包含真实数据的 td 数量
# 经过前面的处理,得到的有效td 数量应该固定为 (天数 + 表头)* 9列
# (31 + 1)*9 = 288 或者 (30+1)*9 = 279
regex_td = r"<td.*?\/td>"
tds_real = re.findall(regex_td, tbm_table)
print('{}_{}: {} tds which contain real data been left'.format(city, month, len(tds_real)))
# 将处理好的 table 再填充回 html 代码
page_source = re.sub(regex_tbm_table, tbm_table, page_source)
# 把 处理好后的 page_source 写入本地文件
with open("{}_{}_{}_purified.html".format(city, month, response_time), 'w', encoding='utf-8') as f:
f.write(page_source)
end_time = time.time()
print("{}_{}: html page source get successfully,process finished within {}s".format(city, month, end_time-start_time))
终章
现在代码和逻辑是简洁了,但效率和性能呢?片面地追求简洁,其实是外强中干臭美花瓶。还记得优化前的效果吗?在 Python Selenium 实现 这篇文章的末尾,我放了1个视频 —— 对,是剪辑掉中间50s文本处理时间之后的视频。
现在呢?话不多说,让代码跑起来。
看到了吗?哈哈哈哈哈哈,让我仰天长啸五分钟。优化后的代码,几乎是立刻就拿到了数据,爬取效果足以和 js逆向 + ajax请求 方案 媲美了。
最后的最后,还是再次感谢这个天气网站的程序员,硬生生把1个爬虫菜鸟逼成了爬虫票友。哈哈哈哈哈,我出门大笑去了。