1.元祖
1.元祖的定义
元组的数据结构跟列表相似
特征:有序、
- 有序:有(索引/下标/index) 正序、反序
- 标识符: ( ) 里面的元素是用英文格式的逗号分割开来
- 关键字:tuple
-
列表和元组有什么区别?
元组是不可变的:程序在运行的时候,无法对其进行改变 -- 没有提供关键字、方法去操作它,没有增删改的操作
-
既然无法对其进行变化,那么为什么要有元组的存在?
安全性考虑 -- 国内的省份(省、市) 变量,常量
但凡是可以进行操作的数据,都存在安全隐患
示例:
tp = () # 定义一个空元组
print(type(tp)) # <class 'tuple'>
tp1 = (1, 2, 3, 4, 5) # 定义一个有值的元组
print(tp1)2.问题res是由tp1 和 tp2 拼接在一起的,还是额外生成的? -- 额外生成的一个新元组
tp1 = (1, 2, 3, 4)
tp2 = (100, 3.14)
res = tp1 + tp2
print(res)
print(type(res))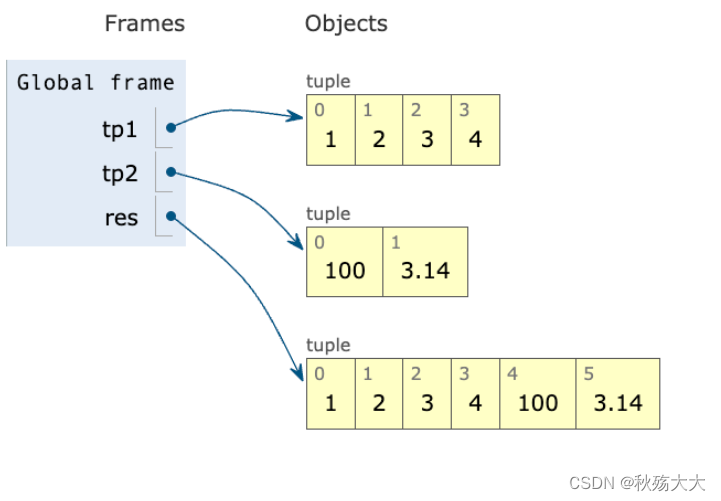
元组乘以int类型的数字的res1是打印两次tp1,还是额外生成一个新的元组?
tp1 = (1, 2, 3, 4)
tp2 = (100, 3.14)
res1 = tp1 * 2
print(res1)
print(type(res1))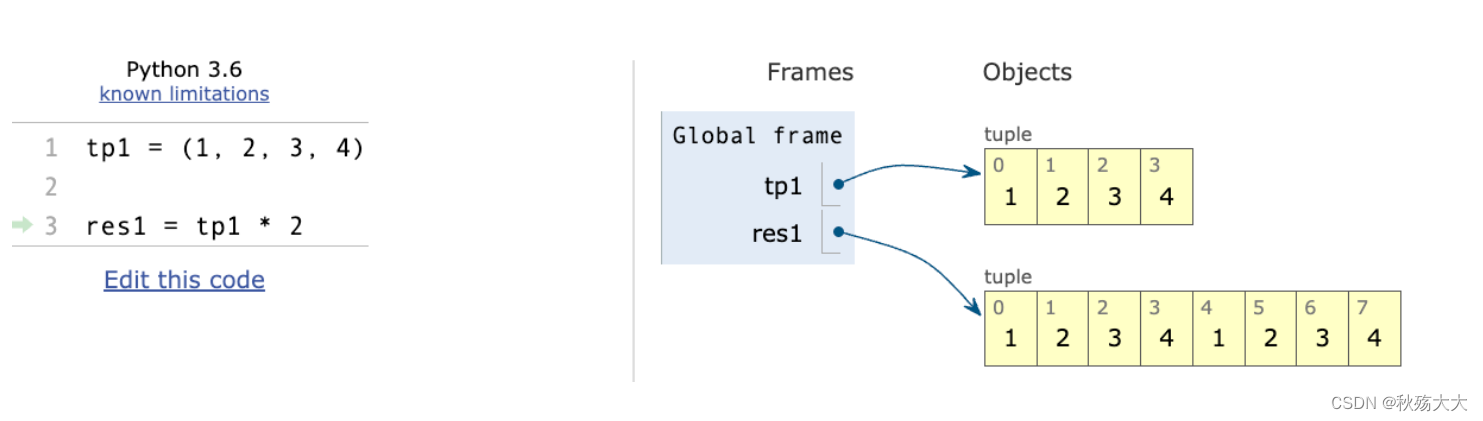
怎么修改元祖?
先转换成列表,修改数据,然后在转化成元组
tp1 = (1, 2, 3, 4)
# 获取修改之前的内存地址
print(f"修改之前的内存地址: {id(tp1)}")
# 1.先转换成列表
lst1 = list(tp1)
# print(lst1)
# print(type(lst1))
# 2.修改数据
lst1.append(5)
# print(lst1)
# print(type(lst1))
# 3.然后在转化成元组
tp1 = tuple(lst1) # 变量的重定义 -- 对变量进行重新赋值
# print(tp1)
# print(type(tp1))
# 获取修改之后的内存地址
print(f"修改之后的内存地址: {id(tp1)}")
# 问题:修改之前的tp1的内存地址和修改之后的一样么? 不一样,是一个新的元组,只是引用的变量名称是一样的,但是存放的内存地址不一样2.集合
集合的定义
定义:由不同的元素组成的一个数据结构,无序排列的
标识符:{ }
关键字:set
特征:无序,元素不能重复,集合和集合之间可以做运算
特征:
无序排列 -- 存放在内存地址之前是无序的
集合里面的元素不能重复 -- 自动去重
集合的操作:
进行强制转换
set1 = {"欢迎", "来到", "秋殇", "老师", "的", "博客", "!"}
lst1 = list(set1)
print(type(lst1))
print(f"lst1中的第一个值:{lst1[0]}") # 不确定、随机的问题:如果转换完成后,连续打印,第一次的值和后面N次的值,是一样的么?
答:一样的,原理:存放内存地址之前,是随机的,但是一旦存放了,后续的内容都是固定的
集合的添加 -- add()
集合的删除 -- pop(随机删除,因为没有下标)、remove(删除指定的值).discard(提前准备好,想删除的值,删除多次,都不会报错)
# set1.pop() # 随机删除,因为没有下标
# print(set1)
# set1.remove("秋殇") # 删除指定的值,如果删除不存在的值,会报错
# set1.remove("秋殇")
# print(set1)
set1.discard("老师") # 提前准备好,想删除的值,删除多次,都不会报错
set1.discard("老师")
print(set1)集合的运算:
运算的方式:交集、并集、差集、交叉补集
交集:获取两个集合之间相同的部分 -- intersection
set1 = {"qs", "大大"}
set2 = {"qs", "dd"}
print(f"获取两个集合之间相同的部分: {set1.intersection(set2)}") # 获取两个集合之间相同的部分: {'七夜老师'}并集:合并两个集合,自动去重 -- union
差集:获取集合中,另一个集合没有的内容 -- difference
交叉补集
set3 = {"qsdd" "高", "富", "帅"}
set4 = {"qsdd", "矮", "矬", "穷"}
print(f"剔除公有的内容,留下双方独有的内容: {set3.symmetric_difference(set4)}")3.函数
1.函数的定义
定义:将一段公式/逻辑代码定义在一个特定的标题(函数名称)下,通过一块,或者一行代码来执行固定好的逻辑, 而这些代码只有函数被调动的时候才会执行
通俗点:封装一些代码
核心点:函数的定义、函数的调用
函数的定义:封装好的代码,只有在调用的时候,才会执行 -- 定义函数的时候,不会执行函数内部的代码
函数的调用:语法:函数的名称() -- 调用函数,执行函数内部的代码
语法规则:
def 自定义的函数名称():
封装的代码 ... ...函数的参数:
定义函数的时候,可以在小括号里面定义一些参数
定义的参数,可以不给值,然后在调用函数的位置,进行传参
def demo1(name, age, addr):
print(f"""
=====demo1函数里面的参数=====
name: {name}
age: {age}
addr: {addr}
""")
demo1(age=18, name="qsdd", addr="cndn")不定长传参
单个*号的参数:args是默认的名称,可以随意修改 -- 元组类型
# def demo3(*args):
# print(f"获取到的值:{args}")
# print(f"获取值的类型: {type(args)}")
# print(args[0])
#
#
# demo3(1, 2, 3, 4, 5)两个*号:kwargs是默认的名称,可以随意修改 -- 字典类型
# def demo4(**kwargs):
# print(f"获取到的值:{kwargs}")
# print(f"获取值的类型: {type(kwargs)}")
#
#
# demo4(name="七夜老师", age=18, addr="湖南长沙")函数的返回值
1.函数的内部可以写return返回值,或者不写
2.如果不写return,也可以执行,不会报错,但是接收到的值,还是 None
3.如果写了,可以把需要传递的值,传递给调用函数的地方,通过两种方式获取(print、变量)
4.写了return但是没有传值的情况下,获取到的值是 None
5.如果有return返回值的情况下,可以通过两种方式获取
# def add1(): # 函数的名称: add1
# # 需要封装的代码
# m = 1
# n = 2
# s = m + n
# print(f"m + n 的结果:{s}")
#
#
# add1()
# 想获取s的值,然后进行 + 100的操作?
# print(s + 100) # 函数的作用域问题 -- 后面的课程会讲,暂时不讲
# def add2():
# m = 1
# n = 2
# s = m + n
# # 不直接写print,因为无法传递数据
# # 通过函数的返回关键字return,把数据传递给调用函数的地方
# return s
# add2()
# 问题:此时调用函数,会不会打印s的值? -- 不会
# 因为:没有对获取到的s值,进行打印操作
# 方式一:直接通过print打印获取到函数返回值
# print(f"获取到函数内部的s:{add2()}")
# 方式二:通过变量接收函数的返回值,然后进行后续的操作
# res = add2()
# print(f"res + 100的值:{res + 100}")
# # 写了return但是没有传值的情况下,获取到的值是 None
# def add3():
# m = 1
# n = 2
# s = m + n
# return
# 如果不写return,也可以执行,不会报错,但是接收到的值,还是 None
# def add4():
# m = 1
# n = 2
# s = m + n
#
#
# # 方式一:
# print(add4())
#
# # 方式二:
# res = add4()
# print(res)
# lst1 = [1, 2, 3]
# print(lst1.extend("qsdd"))