近邻类模型:KNN算法在数据科学中的实践与探索
- 一、KNN算法的基本原理
- 二、KNN算法的变种与改进
- 三、KNN算法的Python实践
- 四、总结与展望
在数据科学领域,分类和回归是两大核心问题。随着大数据时代的到来,传统参数化模型在某些复杂场景中已难以满足需求。此时,非参数化的分类和回归方法逐渐崭露头角,其中近邻类模型(Near-Neighbor Models)以其简单直观、无需明确训练与测试集划分的特性受到了广泛关注。本文将以KNN(k-最近邻)算法为例,深入探讨其在数据科学中的应用,并结合Python的Scikit-learn库展示其实践操作。
一、KNN算法的基本原理
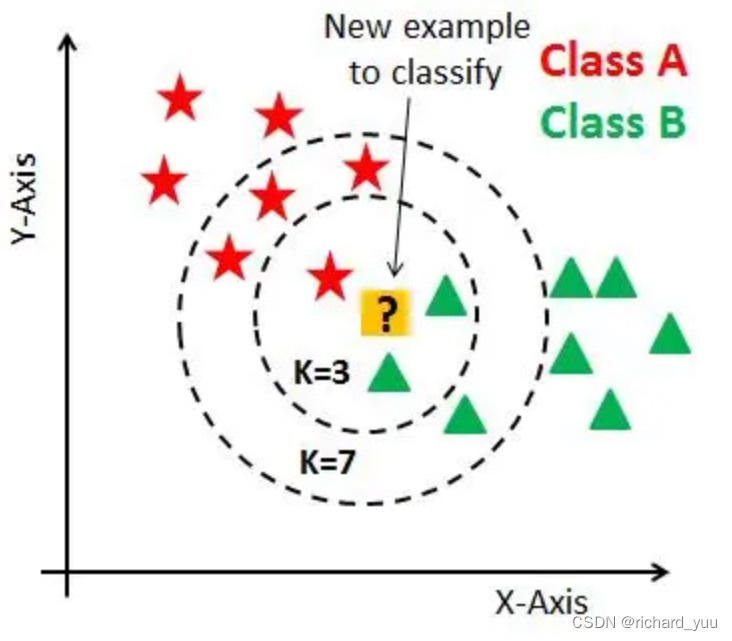
KNN算法是一种基于实例学习的分类方法,其核心思想是通过测量样本点之间的距离来评估样本之间的相似性。在分类过程中,对于待分类的样本,算法会计算其与所有已知样本的距离,并找出距离最近的k个样本。根据这k个最近邻样本的类别分布,多数原则决定待分类样本的归属。
KNN算法无需进行显式的模型训练,因此无需将数据集划分为训练集和测试集。然而,这并不意味着KNN没有参数需要调整。其中,k值的选取是影响算法性能的关键因素之一。过小的k值可能导致算法对噪声和异常值敏感,而过大的k值则可能使算法忽略掉样本间的局部结构。
二、KNN算法的变种与改进
除了基础的KNN算法外,研究者们还提出了一系列变种和改进方法,以适应不同的分类场景。例如,权重KNN在计算距离时考虑了不同近邻样本的权重,使得算法更加灵活;多级分类KNN则适用于多层次的分类问题,能够处理更加复杂的分类体系。
此外,近似最近邻算法(ANN)是处理大规模数据集的一种有效方法。它通过牺牲一定的精度来换取时间和空间效率的提升,使得在海量数据中快速找到最近邻成为可能。ANN算法在搜索引擎、推荐系统等领域有着广泛的应用。
三、KNN算法的Python实践
在Python中,我们可以使用Scikit-learn库来轻松实现KNN算法。下面是一个简单的示例代码,展示了如何使用Scikit-learn进行KNN分类:
python
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
from sklearn.metrics import classification_report, confusion_matrix
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 创建KNN分类器
knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train, y_train)
# 预测测试集
y_pred = knn.predict(X_test)
# 输出分类报告和混淆矩阵
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
在上面的代码中,我们首先加载了鸢尾花数据集,并将其划分为训练集和测试集。然后,我们对数据进行了标准化处理,以消除不同特征之间的量纲差异。接下来,我们创建了一个KNN分类器,并指定了k值为3。通过调用fit方法,我们训练了模型。最后,我们使用训练好的模型对测试集进行预测,并输出了分类报告和混淆矩阵来评估模型的性能。
四、总结与展望
KNN算法作为近邻类模型的代表,以其简单直观、无需显式训练的特性在数据科学领域得到了广泛应用。通过调整k值和结合其他技巧,KNN算法能够应对多种分类场景。随着大数据和机器学习技术的不断发展,未来我们有望看到更多基于近邻类模型的创新应用,为数据科学领域带来更多的突破和进步。