最近研究中学习使用python的ray.tune进行神经网络调参。在这里记录学习过程中的收获,希望能够帮助到有同样需求的人。学习过程主要参考ray官网文档,但由于笔者使用的ray为2.2.0版本,而官方文档为更高级版本,笔者代码和官方文档代码存在一定差异,具体以实际版本为准。
在学习笔记0中笔者归纳了tune调参的基本流程:(1)定义模型训练API;(2)设置超参数优化器并进行超参数搜索;(3)对结果进行分析。模型训练API的定义根据具体任务需求和采用框架定义即可,可以参考学习笔记0中的样例,就不额外撰文进行说明。本文对定义超参数优化器的各种设置进行介绍。
1 概述
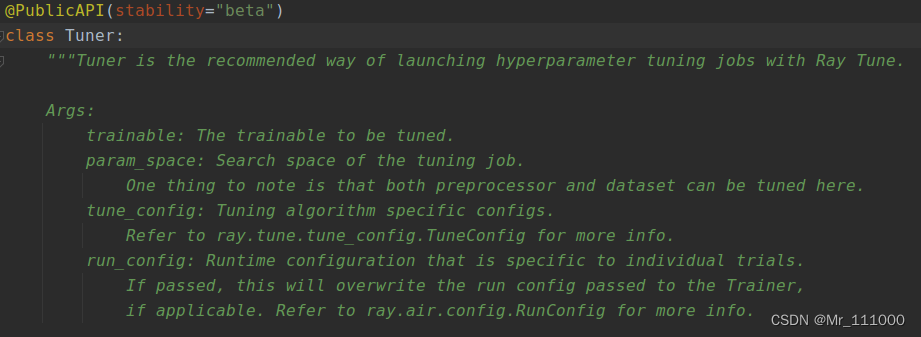
在使用tune调参时,通过创建Tuner对象实例可以灵活地配置调参过程,包括使用的搜索算法和调度器的设置等。如下图所示, 超参数优化器turner的参数包括模型训练函数trainable,超参数搜索空间parame_space,优化算法配置tune_config,及运行配置run_config。以下进行具体说明。
2 模型训练API trainable
trainable传递定义好的模型训练API即可。这里对模型训练函数的定义再做一些补充说明,如以下代码所示,模型训练函数可以使用report返回指标或通过return字典的方式返回指标,允许返回多个指标。使用report可以在每个epoch后进行报告,便于在训练过程中监控指标的变化趋势。而使用return通常是在整个训练过程结束后,将最终的指标作为函数的返回值返回,在无需监控指标变化趋势时可以使用。
def trainable(config):
train_data, test_data = load_data() # 读取训练及测试数据
model, optimizer = create_model(config) # 创建模型及优化器
while True:
train(model,optimizer, train_data) # 模型训练
metric1, metric2 = test(model, test_data) # 模型测试
tune.report(metric1=metric1, metric2=metric2) # 返回结果指标
# return({"metric1": metric1, "metric2": metric2})需要注意,tune调参时默认在CPU上进行,如果需要在GPU上训练,需要在给tuner传递trainable参数时通过tune.with_resources(trainable, resources_per_trial)的方式分配使用的GPU,否则将报错。其中resources_per_trial为给每个trial分配的最大计算资源,以字典形式传递,如以下代码。
resources_per_trial = {"cpu": 2, "gpu": 1} # 如不设置,默认为{"cpu": 1}
tuner = tune.Tuner(
trainable=tune.with_resources(trainable, resources=resources_per_trial),
...
)此外需要注意tune调参时会根据分配的计算资源自动并行执行多个trial,例如设备有32个CPU,且给每个trial分配CPU数为4,则会并行执行8个trial,通过该方式可以控制并行的trial数量,避免过载。
3 搜索空间 param_space
搜索空间以字典{参数名:取值范围}的形式输入,用来定义模型中各参数的搜索范围,每个trial将从搜索空间中选取一组可行的参数并进行网络训练。tune中提供了一些接口用于指定参数的取值范围,下表列出了一些常用的取值形式。
| 类型 | 接口 | 说明 |
| 定值 | / | 字典值只给一个值的情况下该参数将为定值 |
| 网格搜索 | tune.grid_search([List]) | 通过多个Trial搜索List中的所有参数 |
| 随机选择 | tune.choice([List]) | 每个trial随机从List中选择一个参数 |
| 随机均匀采样 | tune.uniform(a,b) | 每个trial从[a,b]中按均匀分布随机采样一个参数 |
| 随机整数采样 | tune.randint(a,b) | 每个trial从[a,b]中按正态分布随机采样一个整数 |
| 随机增量采样 | tune.quniform(a,b,q) | 每个trial从[a,b]中从a开始且间隔为q的数中随机采样 |
| 随机整数 增量采样 | tune.qrandint(a,b,q) | 每个trial从[a,b]中从a开始且间隔为q的整数中随机采样 |
| 采样函数 | tune.sample_from(function) | 通过自定义的函数采样 |
需要注意除网格搜索外其他的参数形式并不会影响搜索次数(即trial的数量),当没有参数采用网格搜索时,trial次数等于优化设置tune_config中设置的num_samples(默认为1)。当有参数采用网格搜索时,网格搜索会尝试所有参数,因此会执行个trial,其中
为num_samples,
为第i个采用网格搜索的参数的所有取值数,即会重复
次网格搜索。
此外使用tune.sample_from(function)可以按照自定义的函数生成参数,具体使用方法可以参考官方文档。
4 优化设置 tune_config
优化设置tune_config以tune.TuneConfig类的对象作为输入,用来设置参数搜索及优化策略。TuneConfig的主要参数如下表。
| 参数 | 说明 | 作用及取值 |
| metric | 性能指标 | 和trainable返回的指标对应 |
| mode | 确定性能指标最大化/最小化 | min或max |
| num_samples | 搜索次数 | 默认为1;若为-1则重复搜索直至满足停止条件 |
| search_alg | 搜索算法 | 默认为随机搜索。可以通过实例化搜索算法对象从而基于BayesOpt,HyperOpt,Ax,Optuna等框架进行搜索,和这些框架配合搜索的方式可参考官方文档及官方示例。 |
| scheduler | 调度方式 | 执行实验的调度方式,用于提前终止不良试验、暂停试验、克隆试验和更改正在运行的试验的超参数。tune提供了 FIFO(默认),MedianStopping,AsyncHyperBand,HyperBand, PopulationBasedTrining等调度方法的API。不同调度方法主要决定了不同的搜索中止策略,具体方式可参考官方文档。 |
| time_budget_s | 时间预算 | 以秒为单位,超出时间预算的trial将终止 |
5 运行设置 run_config
运行设置run_config以ray.air.config.RunConfig类的对象作为输入,用来设置参数搜索及优化策略。RunConfig的主要参数如下表。
| 参数 | 说明 | 作用及取值 |
| name | 实验名称 | 默认和trainable同名,保存结果时按该名称生成相应文件夹 |
| local_dir | 存储地址 | 搜索结果的存储地址,默认为~/ray_results |
| stop | 终止条件 | trainable训练的终止条件。可以以字典形式作为输入,在5.1节给出示例;也可以通过自定义函数或实例化Stopper类定义更复杂的终止条件,具体方式可参考官方文档。 |
| checkpoint_config | 检查点配置 | 具体方式可参考官方文档。 |
5.1 字典形式训练终止条件
构建包含一或多个停止条件的字典作为stop参数输入。字典的键为trainable返回的metric时,将基于性能指标停止训练,如{"loss": 0.1}。字典的键为"training_iteration"时,如{"training_iteration": 100},当迭代次数超过设定值时停止训练。字典的键为time_total_s时,如{"time_total_s": 3600},当训练时间超过以秒为单位的指定值时停止训练。可以同时指定多个终止条件。以下给出示例代码:
stop_criteria = {
"loss": 0.1, # 损失小于0.1时停止训练
"training_iteration": 100, # 最多100次迭代
"time_total_s": 3600 # 最多运行3600秒
}
tuner = tune.Tuner(
...,
run_config=RunConfig(stop=stop_criteria)
)