摘要:大模型席卷而来,通过大量算法模型训练推理,能根据人类输入指令产生图文,其背后是大量深度神经网络模型在做运算,这一过程称之为机器学习,本文从微软语言大模型出发,详解利用大型语言模型(Large Language Models, LLMs)解决实际机器学习(ML)任务的框架,以及存算一体的存内计算架构,从软硬件优化层面为机器学习提升提供参考。
机器学习定义:
机器学习(ML)是一种从数据中提取知识并应用于解决复杂问题的技术,这些问题往往没有现成的确定性算法解决方案,或者创建这样的算法成本过高或不现实。以垃圾邮件检测为例,设计一个基于固定规则的算法来识别所有垃圾邮件几乎是不可能的任务。因为垃圾邮件的特征不断演变,且可能包含不断增长甚至相互冲突的规则,这要求算法必须不断地更新和维护,这在实践中是不可行的。
在机器学习中,模型通过分析大量的数据来学习如何执行任务,而不是被直接编程来执行特定的规则。这种方法使得机器学习在处理那些规则不明确或难以定义的任务时特别有用。例如,在电子邮件服务中,机器学习模型可以学习如何区分垃圾邮件和非垃圾邮件,而无需明确列出所有可能的垃圾邮件特征。这种学习过程使得模型能够适应新的数据模式,并且随着时间的推移而自我改进。
机器学习过程主要分为两个阶段:训练和推理。在训练阶段,基于数据优化学习模型的参数。在预测阶段,部署训练好的模型对新数据进行预测。虽然在大多数情况下,训练和推理阶段是相互独立的,但在增量学习的情况下,它们是耦合在一起的。这些情况下的模型会持续进行训练并做出预测。
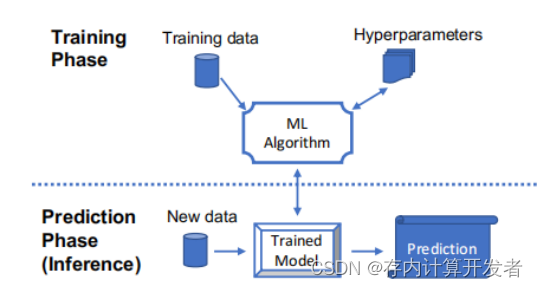
图1 可视化训练和推理阶段。
机器学习的主要目标是泛化,以便它能够很好地处理未见过的数据。然而,这一目标与其优化目标相矛盾,即机器学习试图最小化训练数据上的训练损失。因此,出现了众所周知的偏差-方差问题。如果一个机器学习模型对训练数据过拟合,即具有高方差,它对未见过的数据表现不佳。另一方面,如果模型欠拟合,即具有高偏差,它就无法学习数据中的重要模式或规律。过拟合通常发生在模型对底层问题来说太复杂的情况下。相反,欠拟合发生在模型太简单的情况下。
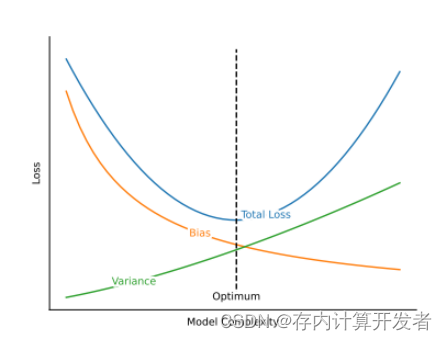
图2 描述偏差-方差权衡。
接下来,我们将介绍不同类型的机器学习任务。之后,我们将探讨机器学习可以解决的不同问题。然后,我们将回顾广泛使用的机器学习算法和方法。
在机器学习领域,任务可以根据其目标和所需的数据处理方式进行分类,包括但不限于:
- 监督学习:在这个任务中,模型从标记的训练数据中学习,并尝试对未见过的数据做出预测或决策。
- 无监督学习:无监督学习算法处理未标记的数据,尝试找出数据中的结构或模式。
- 半监督学习:这种学习介于监督学习和无监督学习之间,使用少量标记数据和大量未标记数据。
- 强化学习:在这种类型的学习中,智能体(agent)通过与环境的交互来学习,目标是最大化某种累积奖励。
- 迁移学习:这是一种学习技术,其中一个模型在一个任务上学习得到的知识被用来提高在另一个不同但相关任务上的学习效率。
机器学习可以解决的问题包括:
- 分类问题
- 回归问题
- 聚类问题
- 异常检测
- 推荐系统
- 自然语言处理任务等
广泛使用的机器学习算法和方法包括:
- 决策树
- 随机森林
- 支持向量机(SVM)
- 神经网络
- 梯度提升机(GBM)
- K-最近邻(KNN)
MLCopilot 解决机器学习任务框架
机器学习算法的分类可以根据它们所需的数据格式及反馈特征、它们旨在解决的问题类型,以及它们运用的技术方法。另外,根据学习模式的不同,机器学习还可以划分为在线学习和离线学习两种形式。在离线学习模式下,所有训练数据在训练开始前都已准备就绪,这是机器学习最普遍的应用形式。相对地,在在线学习模式中,可能是因为整个数据集无法预先获得,或者对整个数据集同时进行训练在计算上不可行。时间序列分析,如金融市场中的序列预测,就是一个典型的在线学习例子,因为它需要按时间顺序逐步处理数据。而面对无法一次性加载到内存中的庞大数据集时,也需要采用在线学习方法,因为这样的数据量使得整体训练变得不切实际。
常用的机器学习算法有随机梯度下降(Stochastic Gradient Descent, SGD),它根据模型参数的输出损失函数,在梯度的相反方向上进行优化;支持向量机(Support Vector Machines, SVMs),通常用于原始空间中输入数据不能线性分离的情况;人工神经网络(Artificial Neural Networks, ANNs),ANN在图像分类、目标检测和自然语言处理等任务中取得了巨大成功。除此之外,提出MLCopilot,这是一个利用大型语言模型(Large Language Models, LLMs)解决实际机器学习(ML)任务的框架。
MLCopilot展示了大型语言模型的多功能性,它不仅能处理与文本相关的任务,还能处理涉及异构输入和复杂推理的任务。
MLCopilot的核心思想是知识驱动的推理,即利用LLMs基于从历史经验中分析和提炼出的先验知识进行推理和任务解决。为此,MLCopilot分为两个阶段:离线和在线,这两个阶段在图1中都有清晰的图示说明。在离线阶段,LLM被用于分析规范化的历史经验数据并提炼出有用的知识。在线阶段,用户将向基于LLM构建的MLCopilot发起查询,以获取针对新任务的合适机器学习解决方案。

图3:MLCopilot 框架
离线阶段:创建经验以及知识池
在离线阶段,MLCopilot的主要任务是创建经验和知识的池(pools)。这涉及收集、规范化和分析历史数据,以便于提取有价值的信息和模式。
这一阶段可能包括数据清洗、特征提取、知识表示和知识库的构建等步骤。
通过使用大型语言模型(LLMs),MLCopilot能够从历史经验中学习和提炼出有用的知识,这些知识随后可以用于推理和解决新的问题。

图4:离线阶段
在线阶段:交互与解决
MLCopilot的在线阶段旨在根据离线阶段获得的现成信息进行推理和任务解决。具体来说,面对用户提出的带有任务描述的查询,MLCopilot将通过以下步骤在一个回合中响应相应的合理机器学习(ML)解决方案:
1.理解用户查询:首先,MLCopilot需要理解用户提出的任务描述,这通常涉及到自然语言处理技术来解析和理解用户的查询内容。
2.检索相关信息:接着,MLCopilot将在离线阶段创建的经验和知识池中检索与用户任务描述相关的信息。这可能包括先前解决类似任务的策略、模型架构、参数设置等。
3.利用大型语言模型(LLM):MLCopilot将与LLM交互,通过一个精心设计的提示(prompt)来引导LLM进行推理和任务解决。这个提示将基于检索到的相关信息,并明确用户的需求。
4.生成解决方案:LLM将根据提供的提示和知识库中的信息,生成一个或多个可能的ML解决方案。这些解决方案将尽可能地满足用户的任务需求。
5.返回结果:最后,MLCopilot将评估LLM生成的解决方案,并选择最合适的方案返回给用户。这个过程可能涉及到额外的推理步骤,以确保所选方案的合理性和有效性。
6.用户交互:在整个过程中,MLCopilot可能还需要与用户进行交互,以获取更多的上下文信息或澄清用户的具体需求。
通过这种方式,MLCopilot的在线阶段能够快速地为用户提供基于历史经验和知识库的定制化机器学习解决方案,极大地提高了解决复杂任务的效率和准确性。
在机器学习自动化(AutoML)和元学习(meta learning)领域,有多种传统方法被提出和使用,包括:
随机搜索(Random):随机搜索超参数。
- ASKL(Feurer et al., 2015):一种基于序列模型的超参数优化方法。
- Constant(Bardenet et al., 2013; Kotthoff et al., 2019):一种在超参数空间中进行均匀采样的方法。
- TST-M(Wistuba et al., 2016):基于贝叶斯优化的超参数调整方法。
- HyperSTAR(Mittal et al., 2020):一种使用神经网络来预测超参数性能的方法。
- HyperFD(Yan et al., 2022):一种高效的超参数优化方法。
- FLAML-Zero(Wang et al., 2021a):一种零样本超参数优化方法。
MLCopilot在这些传统方法的基础上,利用大型语言模型(LLM)进行知识驱动的推理,以解决机器学习任务。MLCopilot的在线阶段通过以下两种方式与LLM交互:
LLM-ZS(Zero-Shot):直接提示LLM生成一个零样本解决方案,仅基于任务描述。这类似于使用GitHub Copilot或Amazon CodeWhisperer等工具。
LLM-FS(Few-Shot):使用少量样本提示技术(Brown et al., 2020),通过在提示中添加一些示例来实现上下文学习。这些示例是从规范化的经验池中随机选择的。与MLCopilot不同,LLM-FS没有使用经验和知识检索等高级技术。
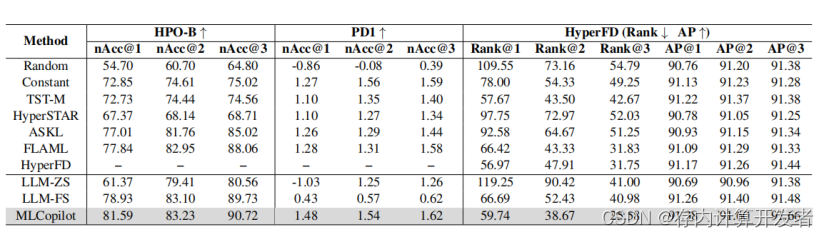
表1:HPO-B、PD1和HyperFD的关键指标
在进行的实验中,MLCopilot框架在三次独立试验中均实现了最高的归一化准确率(nAcc),特别是在初次尝试(nAcc@1)中表现出显著的提升。这一结果突显了LLM(大型语言模型)在处理机器学习任务时的巨大潜力。与传统的基线方法相比,即使是少量样本(LLM-FS)也展现出了超越性能,这进一步证实了LLM在机器学习领域的应用前景。
在针对PD1数据集的测试中,归一化准确率(nAcc)的评分范围被设定在[−2, 2]之间,遵循了Wang等人(2021b)的研究设定。在此设置下,MLCopilot相较于其他所有比较方法仍然保持最佳性能。特别是,“Constant”这一基线方法的表现几乎超过了所有其他基线,这引发了对其他基线在任务相似性度量上有效性的质疑。同时,LLM-ZS(零样本)和LLM-FS(少量样本)在PD1上未能取得成功,这表明PD1对LLM来说更具挑战性。
对于HyperFD基准测试,我们遵循了Yan等人(2022)的方法,采用平均精度(AP)和排名来评价模型性能,其中AP值越高越好,排名越低越好(范围在[1, 216]内)。与HPO-B中观察到的趋势相似,LLM-FS在给出一些示例后,能够达到与大多数基线方法相媲美的性能水平。预期随着MLCopilot技术的整合,LLM-FS的性能有望进一步提升。
存内计算架构大幅提升机器学习
机器学习算法的训练一般通过迭代计算完成,如反复执行包括矩阵乘法在内的运算,最终收敛到一个最优解。因此,基于阻变存储器阵列的矩阵-向量乘法也被用来加速机器学习。但是,迭代意味着计算缓慢,同时带来巨大能耗。存内计算架构实现一步训练线性回归、逻辑回归等机器学习算法,无需迭代,从而显著提升计算速度、降低能耗。
存内计算技术(Computing in Memory,CIM)是一种将计算逻辑直接嵌入到存储器中的新型计算范式。其核心原理是在存储器中实现简单的计算操作,以降低数据传输的功耗和延迟。存内计算技术通过将计算能力与存储器紧密集成,旨在克服冯·诺依曼瓶颈问题,提高计算性能和效率。
存内计算技术的原理可以分为以下几个方面:
- 存储器与计算单元的融合:存内计算技术将计算单元嵌入到存储器中,使得数据可以在存储器中直接进行计算操作,避免了数据在存储器和处理器之间的频繁传输,降低了功耗和延迟。
- 计算原语:存内计算技术中的计算原语是实现数据处理的基本操作。常见的计算原语包括逻辑门、乘积累加操作(MAC)等。这些操作可以直接在存储器中执行,从而减少了数据传输的次数和功耗。
- 存储器阵列:存内计算技术通常采用存储器阵列结构,将计算单元与存储单元相互连接。这样的结构使得数据可以在存储器阵列中进行高效地处理和访问。
- 硬件加速:存内计算技术通过硬件加速,可以大幅提高计算性能,满足大规模数据处理和人工智能应用场景对计算速度和效率的需求。
- 混合计算架构:存内计算技术可以与传统的计算架构相结合,形成混合计算架构,以实现更高的计算性能和能效。
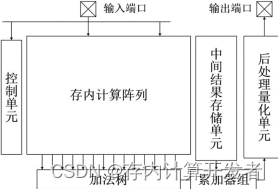
由于其高速计算的性能,存内计算在加速机器学习方面具有巨大潜力,有力地支撑其应用于边缘端的人工智能芯片。
总结:
MLCopilot和存内计算在支持机器学习方面相辅相成:MLCopilot通过知识驱动的推理,提供了一种软件层面的解决方案,而存内计算则从硬件层面提升了计算效率。MLCopilot利用历史数据和知识来优化任务解决过程,存内计算则通过减少数据搬运来提升数据处理速度。两者结合使用,可以在机器学习任务中实现更快速的模型训练和更高效的模型推理,尤其是在资源受限的边缘计算环境中。
随着技术的不断进步,MLCopilot架构和存内计算技术有望在未来的机器学习领域发挥更大的作用,解决更多复杂的任务,并推动人工智能技术的发展。





![[实验]Keil 4下仿真三星2440A芯片的汇编及CPIO控制实验](https://img-blog.csdnimg.cn/direct/6fb26f08458a45549b474330a7dbe241.png)