目录
理论预热
实践
构建卷积神经网络
卷积网络模块构建
实战:基于经典网络架构训练图像分类模型
数据预处理部分:
网络模块设置:
网络模型保存与测试
实践
制作好数据源:
图片
标签
展示下数据
加载models中提供的模型,并且直接用训练的好权重当做初始化参数
测试
测试数据预处理
看看预测的结果
理论预热
计算机视觉发展到今天,离不开卷积神经网络(大伙熟知的CNN)。卷积神经网络自身的应用就十分的广泛:诸如检测任务,分类,检索,超分辨率重构,医学任务,无人驾驶,人脸识别等。
对于传统网络,他的一个重要区别就是多了卷积层和池化层。

所以,我们的CNN的架构就是:输入层,卷积层,池化层和全连接层。重点看多出来的两个层:
卷积层通过卷积核对输入的图像数据进行卷积操作,以提取图像的特征。卷积核是一种小的、可学习的矩阵,它可以通过滑动和权重来学习图像的特征。
对输入图像进行通道分离,将其转换为多个通道。
对每个通道进行卷积操作,使用卷积核对输入图像数据进行卷积。
对卷积后的结果进行激活函数处理,如ReLU等。
滑动卷积核以覆盖整个输入图像,并将各个卷积结果拼接在一起形成新的图像。
对新的图像重复步骤2-4,直到所有卷积层的操作完成。
上面的概念中,我们发现卷积层一定涉及到这些参数:
滑动窗口步长(一次平移多少卷积?)
卷积核尺寸(这个卷积核多大,操作多大的矩阵进行卷积?)
边缘填充
卷积核的个数
池化层通过采样操作对卷积层的输出进行下采样,以减少参数数量和计算复杂度,同时保留重要的特征信息。池化层通常使用最大池化或平均池化作为采样方法。
对输入图像进行分割,将其划分为多个小块。
对每个小块进行采样,如选择最大值或平均值等。
对采样后的结果进行下采样,以减少图像的大小。
滑动池化窗口以覆盖整个输入图像,并将各个池化结果拼接在一起形成新的图像。
对新的图像重复步骤2-4,直到所有池化层的操作完成。
实践
构建卷积神经网络
-
卷积网络中的输入和层与传统神经网络有些区别,需重新设计,训练模块基本一致
import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F from torchvision import datasets,transforms import matplotlib.pyplot as plt import numpy as np %matplotlib inline
老规矩读数据:
# 定义超参数 input_size = 28 #图像的总尺寸28*28 num_classes = 10 #标签的种类数 num_epochs = 3 #训练的总循环周期 batch_size = 64 #一个撮(批次)的大小,64张图片 # 训练集 train_dataset = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) # 测试集 test_dataset = datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor()) # 构建batch数据 train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True)
卷积网络模块构建
-
一般卷积层,relu层,池化层可以写成一个套餐
-
注意卷积最后结果还是一个特征图,需要把图转换成向量才能做分类或者回归任务
class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28) nn.Conv2d( in_channels=1, # 灰度图 out_channels=16, # 要得到几多少个特征图 kernel_size=5, # 卷积核大小 stride=1, # 步长 padding=2, # 如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1 ), # 输出的特征图为 (16, 28, 28) nn.ReLU(), # relu层 nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 14, 14) ) self.conv2 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14) nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 14, 14) nn.ReLU(), # relu层 nn.MaxPool2d(2), # 输出 (32, 7, 7) ) self.out = nn.Linear(32 * 7 * 7, 10) # 全连接层得到的结果 def forward(self, x): x = self.conv1(x) x = self.conv2(x) x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 32 * 7 * 7) output = self.out(x) return output
我们的评估以准确率为准
def accuracy(predictions, labels): pred = torch.max(predictions.data, 1)[1] rights = pred.eq(labels.data.view_as(pred)).sum() return rights, len(labels)
训练:
# 实例化
net = CNN()
#损失函数
criterion = nn.CrossEntropyLoss()
#优化器
optimizer = optim.Adam(net.parameters(), lr=0.001) #定义优化器,普通的随机梯度下降算法
#开始训练循环
for epoch in range(num_epochs):
#当前epoch的结果保存下来
train_rights = []
for batch_idx, (data, target) in enumerate(train_loader): #针对容器中的每一个批进行循环
net.train()
output = net(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
right = accuracy(output, target)
train_rights.append(right)
if batch_idx % 100 == 0:
net.eval()
val_rights = []
for (data, target) in test_loader:
output = net(data)
right = accuracy(output, target)
val_rights.append(right)
#准确率计算
train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))
print('当前epoch: {} [{}/{} ({:.0f}%)]\t损失: {:.6f}\t训练集准确率: {:.2f}%\t测试集正确率: {:.2f}%'.format(
epoch, batch_idx * batch_size, len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.data,
100. * train_r[0].numpy() / train_r[1],
100. * val_r[0].numpy() / val_r[1]))
当前epoch: 0 [0/60000 (0%)] 损失: 2.313235 训练集准确率: 7.81% 测试集正确率: 16.60% 当前epoch: 0 [6400/60000 (11%)] 损失: 0.286634 训练集准确率: 75.54% 测试集正确率: 91.12% 当前epoch: 0 [12800/60000 (21%)] 损失: 0.171127 训练集准确率: 84.37% 测试集正确率: 94.98% 当前epoch: 0 [19200/60000 (32%)] 损失: 0.140562 训练集准确率: 88.05% 测试集正确率: 95.41% 当前epoch: 0 [25600/60000 (43%)] 损失: 0.116371 训练集准确率: 90.04% 测试集正确率: 96.92% 当前epoch: 0 [32000/60000 (53%)] 损失: 0.079103 训练集准确率: 91.50% 测试集正确率: 97.56% 当前epoch: 0 [38400/60000 (64%)] 损失: 0.139781 训练集准确率: 92.45% 测试集正确率: 97.73% 当前epoch: 0 [44800/60000 (75%)] 损失: 0.029213 训练集准确率: 93.12% 测试集正确率: 97.96% 当前epoch: 0 [51200/60000 (85%)] 损失: 0.023761 训练集准确率: 93.71% 测试集正确率: 98.13% 当前epoch: 0 [57600/60000 (96%)] 损失: 0.073131 训练集准确率: 94.17% 测试集正确率: 98.01% 当前epoch: 1 [0/60000 (0%)] 损失: 0.024543 训练集准确率: 100.00% 测试集正确率: 98.26% 当前epoch: 1 [6400/60000 (11%)] 损失: 0.012003 训练集准确率: 97.83% 测试集正确率: 98.23% 当前epoch: 1 [12800/60000 (21%)] 损失: 0.037428 训练集准确率: 98.22% 测试集正确率: 97.90% 当前epoch: 1 [19200/60000 (32%)] 损失: 0.039895 训练集准确率: 98.25% 测试集正确率: 98.01% 当前epoch: 1 [25600/60000 (43%)] 损失: 0.080754 训练集准确率: 98.20% 测试集正确率: 98.10% 当前epoch: 1 [32000/60000 (53%)] 损失: 0.190979 训练集准确率: 98.26% 测试集正确率: 98.47% 当前epoch: 1 [38400/60000 (64%)] 损失: 0.060385 训练集准确率: 98.28% 测试集正确率: 98.62% 当前epoch: 1 [44800/60000 (75%)] 损失: 0.024711 训练集准确率: 98.32% 测试集正确率: 98.46% 当前epoch: 1 [51200/60000 (85%)] 损失: 0.092447 训练集准确率: 98.37% 测试集正确率: 98.57% 当前epoch: 1 [57600/60000 (96%)] 损失: 0.089807 训练集准确率: 98.37% 测试集正确率: 98.63% 当前epoch: 2 [0/60000 (0%)] 损失: 0.040822 训练集准确率: 98.44% 测试集正确率: 98.57% 当前epoch: 2 [6400/60000 (11%)] 损失: 0.005734 训练集准确率: 98.76% 测试集正确率: 98.46% 当前epoch: 2 [12800/60000 (21%)] 损失: 0.104445 训练集准确率: 98.85% 测试集正确率: 98.68% 当前epoch: 2 [19200/60000 (32%)] 损失: 0.015682 训练集准确率: 98.79% 测试集正确率: 98.88% 当前epoch: 2 [25600/60000 (43%)] 损失: 0.012045 训练集准确率: 98.78% 测试集正确率: 98.77% 当前epoch: 2 [32000/60000 (53%)] 损失: 0.015652 训练集准确率: 98.85% 测试集正确率: 98.45% 当前epoch: 2 [38400/60000 (64%)] 损失: 0.040139 训练集准确率: 98.82% 测试集正确率: 98.70% 当前epoch: 2 [44800/60000 (75%)] 损失: 0.088626 训练集准确率: 98.80% 测试集正确率: 98.81% 当前epoch: 2 [51200/60000 (85%)] 损失: 0.007847 训练集准确率: 98.80% 测试集正确率: 99.01% 当前epoch: 2 [57600/60000 (96%)] 损失: 0.015996 训练集准确率: 98.79% 测试集正确率: 98.85%
实战:基于经典网络架构训练图像分类模型
数据预处理部分:
-
数据增强:torchvision中transforms模块自带功能,比较实用
-
数据预处理:torchvision中transforms也帮我们实现好了,直接调用即可
-
DataLoader模块直接读取batch数据
网络模块设置:
-
加载预训练模型,torchvision中有很多经典网络架构,调用起来十分方便,并且可以用人家训练好的权重参数来继续训练,也就是所谓的迁移学习
-
需要注意的是别人训练好的任务跟咱们的可不是完全一样,需要把最后的head层改一改,一般也就是最后的全连接层,改成咱们自己的任务
-
训练时可以全部重头训练,也可以只训练最后咱们任务的层,因为前几层都是做特征提取的,本质任务目标是一致的
网络模型保存与测试
-
模型保存的时候可以带有选择性,例如在验证集中如果当前效果好则保存
-
读取模型进行实际测试

实践
第一步就是导入库:
import os import matplotlib.pyplot as plt %matplotlib inline import numpy as np import torch from torch import nn import torch.optim as optim import torchvision # pip install torchvision from torchvision import transforms, models, datasets # https://pytorch.org/docs/stable/torchvision/index.html import imageio import time import warnings import random import sys import copy import json from PIL import Image
下面就是加载数据集:假设我们的数据集地址在
data_dir = './flower_data/' train_dir = data_dir + '/train' # 训练集数据集 valid_dir = data_dir + '/valid' # 验证集数据集
以这个为例,自行更改地址:
制作好数据源:
图片
data_transforms中指定了所有图像预处理操作,ImageFolder假设所有的文件按文件夹保存好,每个文件夹下面存贮同一类别的图片,文件夹的名字为分类的名字。
预处理操作如下:
data_transforms = {
'train': transforms.Compose([transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
transforms.CenterCrop(224),#从中心开始裁剪
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差
]),
'valid': transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
下面就是使用ImageFolder批量加载导入
batch_size = 8
image_datasets = {
x: datasets.ImageFolder(
os.path.join(data_dir, x), data_transforms[x]
) for x in ['train', 'valid']
}
dataloaders = {
x: torch.utils.data.DataLoader(
image_datasets[x],
batch_size=batch_size, shuffle=True
) for x in ['train', 'valid']
}
dataset_sizes = {
x: len(image_datasets[x]) for x in ['train', 'valid']
}
class_names = image_datasets['train'].classes
来看看结果:
image_datasets
{'train': Dataset ImageFolder
Number of datapoints: 6552
Root location: ./flower_data/train
StandardTransform
Transform: Compose(
RandomRotation(degrees=[-45.0, 45.0], interpolation=nearest, expand=False, fill=0)
CenterCrop(size=(224, 224))
RandomHorizontalFlip(p=0.5)
RandomVerticalFlip(p=0.5)
ColorJitter(brightness=(0.8, 1.2), contrast=(0.9, 1.1), saturation=(0.9, 1.1), hue=(-0.1, 0.1))
RandomGrayscale(p=0.025)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
),
'valid': Dataset ImageFolder
Number of datapoints: 818
Root location: ./flower_data/valid
StandardTransform
Transform: Compose(
Resize(size=256, interpolation=bilinear, max_size=None, antialias=True)
CenterCrop(size=(224, 224))
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)}
dataloaders
{'train': <torch.utils.data.dataloader.DataLoader at 0x21f544caa30>,
'valid': <torch.utils.data.dataloader.DataLoader at 0x21f544cb9d0>}
dataset_sizes
{'train': 6552, 'valid': 818}
标签
导入我们的标签文件
with open('cat_to_name.json', 'r') as f:
cat_to_name = json.load(f)
{'21': 'fire lily',
'3': 'canterbury bells',
'45': 'bolero deep blue',
'1': 'pink primrose',
'34': 'mexican aster',
'27': 'prince of wales feathers',
'7': 'moon orchid',
'16': 'globe-flower',
'25': 'grape hyacinth',
'26': 'corn poppy',
'79': 'toad lily',
'39': 'siam tulip',
'24': 'red ginger',
'67': 'spring crocus',
'35': 'alpine sea holly',
'32': 'garden phlox',
'10': 'globe thistle',
'6': 'tiger lily',
'93': 'ball moss',
'33': 'love in the mist',
'9': 'monkshood',
'102': 'blackberry lily',
'14': 'spear thistle',
'19': 'balloon flower',
'100': 'blanket flower',
...
'89': 'watercress',
'73': 'water lily',
'46': 'wallflower',
'77': 'passion flower',
'51': 'petunia'}
可以在控制台上打印一下这个变量
展示下数据
注意tensor的数据需要转换成numpy的格式,而且还需要还原回标准化的结果
def im_convert(tensor):
""" 展示数据"""
image = tensor.to("cpu").clone().detach()
image = image.numpy().squeeze()
image = image.transpose(1,2,0)
image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))
image = image.clip(0, 1)
return image
fig=plt.figure(figsize=(20, 12)) columns = 4 rows = 2 dataiter = iter(dataloaders['valid']) inputs, classes = dataiter.__next__() for idx in range (columns*rows): ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[]) ax.set_title(cat_to_name[str(int(class_names[classes[idx]]))]) plt.imshow(im_convert(inputs[idx])) plt.show()

加载models中提供的模型,并且直接用训练的好权重当做初始化参数
model_name = 'resnet'
#可选的比较多 ['resnet', 'alexnet', 'vgg', 'squeezenet', 'densenet', 'inception']
#是否用人家训练好的特征来做
feature_extract = True
# 是否用GPU训练
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:
print('CUDA is not available. Training on CPU ...')
else:
print('CUDA is available! Training on GPU ...')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
这里检查一下自己的电脑支不支持GPU训练。(打印一下torch.cuda.is_available())
def set_parameter_requires_grad(model, feature_extracting): if feature_extracting: for param in model.parameters(): param.requires_grad = False model_ft = models.resnet152() # models是torchvision里的合集,标识已经调好系数的模型
>model_ft
ResNet( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): Bottleneck( (conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) ... ) ) (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (fc): Linear(in_features=2048, out_features=1000, bias=True) )
我们嫖一下Pytorch给的Demo:
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
# 选择合适的模型,不同模型的初始化方法稍微有点区别
model_ft = None
input_size = 0
if model_name == "resnet":
""" Resnet152
"""
model_ft = models.resnet152(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Sequential(nn.Linear(num_ftrs, 102),
nn.LogSoftmax(dim=1))
input_size = 224
elif model_name == "alexnet":
""" Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg16(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
# Handle the auxilary net
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# Handle the primary net
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model name, exiting...")
exit()
return model_ft, input_size
设置一下哪些层需要训练:
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True)
#GPU计算
model_ft = model_ft.to(device)
# 模型保存
filename='checkpoint.pth'
# 是否训练所有层
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:
params_to_update = []
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t",name)
else:
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t",name)
设置一下优化器:
# 优化器设置 optimizer_ft = optim.Adam(params_to_update, lr=1e-2) scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)#学习率每7个epoch衰减成原来的1/10 #最后一层已经LogSoftmax()了,所以不能nn.CrossEntropyLoss()来计算了,nn.CrossEntropyLoss()相当于logSoftmax()和nn.NLLLoss()整合 criterion = nn.NLLLoss()
这个函数是训练模块,直接拿去用
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False,filename=filename):
since = time.time()
best_acc = 0
"""
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
model.class_to_idx = checkpoint['mapping']
"""
model.to(device)
val_acc_history = []
train_acc_history = []
train_losses = []
valid_losses = []
LRs = [optimizer.param_groups[0]['lr']]
best_model_wts = copy.deepcopy(model.state_dict())
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 训练和验证
for phase in ['train', 'valid']:
if phase == 'train':
model.train() # 训练
else:
model.eval() # 验证
running_loss = 0.0
running_corrects = 0
# 把数据都取个遍
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 清零
optimizer.zero_grad()
# 只有训练的时候计算和更新梯度
with torch.set_grad_enabled(phase == 'train'):
if is_inception and phase == 'train':
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4*loss2
else:#resnet执行的是这里
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# 训练阶段更新权重
if phase == 'train':
loss.backward()
optimizer.step()
# 计算损失
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
time_elapsed = time.time() - since
print('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# 得到最好那次的模型
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
state = {
'state_dict': model.state_dict(),
'best_acc': best_acc,
'optimizer' : optimizer.state_dict(),
}
torch.save(state, filename)
if phase == 'valid':
val_acc_history.append(epoch_acc)
valid_losses.append(epoch_loss)
scheduler.step(epoch_loss)
if phase == 'train':
train_acc_history.append(epoch_acc)
train_losses.append(epoch_loss)
print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))
LRs.append(optimizer.param_groups[0]['lr'])
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# 训练完后用最好的一次当做模型最终的结果
model.load_state_dict(best_model_wts)
return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs
现在调用一下:
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=20, is_inception=(model_name=="inception"))
Epoch 0/19 ---------- Time elapsed 1m 47s train Loss: 10.4009 Acc: 0.3141 Time elapsed 1m 56s valid Loss: 8.2376 Acc: 0.4939 d:\Miniconda\envs\PyEnvTorch\lib\site-packages\torch\optim\lr_scheduler.py:156: UserWarning: The epoch parameter in `scheduler.step()` was not necessary and is being deprecated where possible. Please use `scheduler.step()` to step the scheduler. During the deprecation, if epoch is different from None, the closed form is used instead of the new chainable form, where available. Please open an issue if you are unable to replicate your use case: https://github.com/pytorch/pytorch/issues/new/choose. warnings.warn(EPOCH_DEPRECATION_WARNING, UserWarning) Optimizer learning rate : 0.0010000 Epoch 1/19 ---------- Time elapsed 3m 42s train Loss: 2.1648 Acc: 0.7053 Time elapsed 3m 51s valid Loss: 3.8922 Acc: 0.5733 Optimizer learning rate : 0.0100000 Epoch 2/19 ---------- Time elapsed 5m 41s train Loss: 9.7510 Acc: 0.4733 Time elapsed 5m 50s valid Loss: 11.1601 Acc: 0.5110 Optimizer learning rate : 0.0010000 Epoch 3/19 ---------- Time elapsed 7m 39s train Loss: 2.7650 Acc: 0.7486 Time elapsed 7m 49s valid Loss: 4.8973 Acc: 0.6443 Optimizer learning rate : 0.0100000 ... Optimizer learning rate : 0.0010000 Training complete in 39m 6s Best val Acc: 0.718826
再训练一下:
for param in model_ft.parameters(): param.requires_grad = True # 再继续训练所有的参数,学习率调小一点 optimizer = optim.Adam(params_to_update, lr=1e-4) scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1) # 损失函数 criterion = nn.NLLLoss()
将上一轮的结果取出来:
# Load the checkpoint checkpoint = torch.load(filename) best_acc = checkpoint['best_acc'] model_ft.load_state_dict(checkpoint['state_dict']) optimizer.load_state_dict(checkpoint['optimizer']) #model_ft.class_to_idx = checkpoint['mapping']
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer, num_epochs=10, is_inception=(model_name=="inception"))
Epoch 0/9
----------
Time elapsed 3m 16s
train Loss: 3.0328 Acc: 0.8211
Time elapsed 3m 25s
valid Loss: 7.1805 Acc: 0.7298
d:\Miniconda\envs\PyEnvTorch\lib\site-packages\torch\optim\lr_scheduler.py:143: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
warnings.warn("Detected call of `lr_scheduler.step()` before `optimizer.step()`. "
Optimizer learning rate : 0.0010000
Epoch 1/9
----------
Time elapsed 6m 45s
train Loss: 2.7197 Acc: 0.8295
Time elapsed 6m 56s
valid Loss: 5.8508 Acc: 0.7665
Optimizer learning rate : 0.0010000
Epoch 2/9
----------
Time elapsed 10m 16s
train Loss: 2.8115 Acc: 0.8239
Time elapsed 10m 26s
valid Loss: 8.6120 Acc: 0.6724
Optimizer learning rate : 0.0010000
Epoch 3/9
----------
Time elapsed 13m 44s
train Loss: 2.6436 Acc: 0.8321
Time elapsed 13m 55s
valid Loss: 8.3770 Acc: 0.6797
Optimizer learning rate : 0.0010000
...
Optimizer learning rate : 0.0010000
Training complete in 34m 39s
Best val Acc: 0.766504
测试
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True) # GPU模式 model_ft = model_ft.to(device) # 保存文件的名字 filename='./checkpoint.pth' # 加载模型 checkpoint = torch.load(filename) best_acc = checkpoint['best_acc'] model_ft.load_state_dict(checkpoint['state_dict'])
测试数据预处理
-
测试数据处理方法需要跟训练时一直才可以
-
crop操作的目的是保证输入的大小是一致的
-
标准化操作也是必须的,用跟训练数据相同的mean和std,但是需要注意一点训练数据是在0-1上进行标准化,所以测试数据也需要先归一化
-
最后一点,PyTorch中颜色通道是第一个维度,跟很多工具包都不一样,需要转换
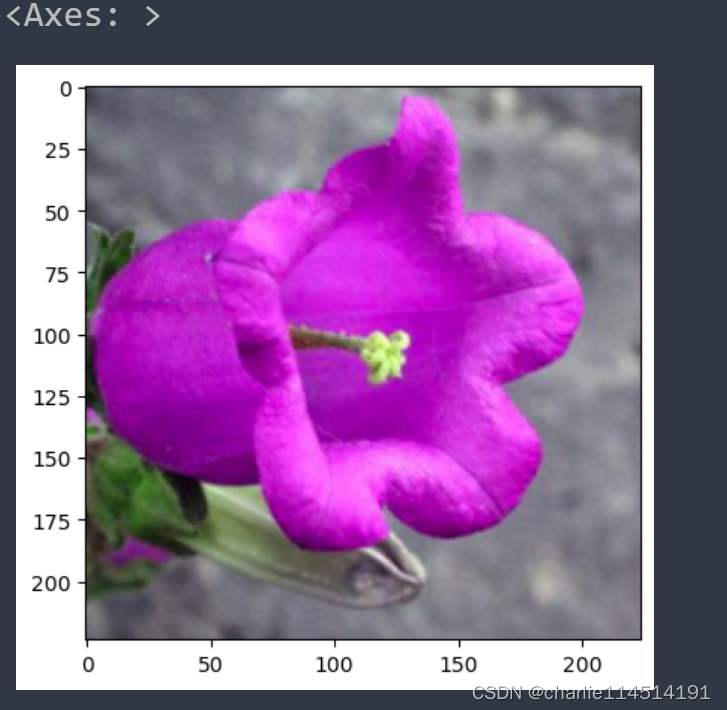
def process_image(image_path): # 读取测试数据 img = Image.open(image_path) # Resize,thumbnail方法只能进行缩小,所以进行了判断 if img.size[0] > img.size[1]: img.thumbnail((10000, 256)) else: img.thumbnail((256, 10000)) # Crop操作 left_margin = (img.width-224)/2 bottom_margin = (img.height-224)/2 right_margin = left_margin + 224 top_margin = bottom_margin + 224 img = img.crop((left_margin, bottom_margin, right_margin, top_margin)) # 相同的预处理方法 img = np.array(img)/255 mean = np.array([0.485, 0.456, 0.406]) #provided mean std = np.array([0.229, 0.224, 0.225]) #provided std img = (img - mean)/std # 注意颜色通道应该放在第一个位置 img = img.transpose((2, 0, 1)) return img
def imshow(image, ax=None, title=None): """展示数据""" if ax is None: fig, ax = plt.subplots() # 颜色通道还原 image = np.array(image).transpose((1, 2, 0)) # 预处理还原 mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) image = std * image + mean image = np.clip(image, 0, 1) ax.imshow(image) ax.set_title(title) return ax
image_path = 'image_06621.jpg' # 抓一张看看效果 img = process_image(image_path) imshow(img)
# 得到一个batch的测试数据 dataiter = iter(dataloaders['valid']) images, labels = dataiter.__next__() model_ft.eval() if train_on_gpu: output = model_ft(images.cuda()) else: output = model_ft(images)
output表示对一个batch中每一个数据得到其属于各个类别的可能性, 下一步看看结果如何
_, preds_tensor = torch.max(output, 1) preds = np.squeeze(preds_tensor.numpy()) if not train_on_gpu else np.squeeze(preds_tensor.cpu().numpy())
看看预测的结果
fig=plt.figure(figsize=(20, 20))
columns =4
rows = 2
for idx in range (columns*rows):
ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])
plt.imshow(im_convert(images[idx]))
ax.set_title("{} ({})".format(cat_to_name[str(preds[idx])], cat_to_name[str(labels[idx].item())]),
color=("green" if cat_to_name[str(preds[idx])]==cat_to_name[str(labels[idx].item())] else "red"))
plt.show()