本文首发于公众号:机器感知
FlashSpeech、ID-Animator、TalkingGaussian、FlowMap、CutDiffusion

Gradient Guidance for Diffusion Models: An Optimization Perspective

Diffusion models have demonstrated empirical successes in various applications and can be adapted to task-specific needs via guidance. This paper introduces a form of gradient guidance for adapting or fine-tuning diffusion models towards user-specified optimization objectives. We study the theoretic aspects of a guided score-based sampling process, linking the gradient-guided diffusion model to first-order optimization. We show that adding gradient guidance to the sampling process of a pre-trained diffusion model is essentially equivalent to solving a regularized optimization problem, where the regularization term acts as a prior determined by the pre-training data. Diffusion models are able to learn data's latent subspace, however, explicitly adding the gradient of an external objective function to the sample process would jeopardize the structure in generated samples. To remedy this issue, we consider a modified form of gradient guidance based on a forward prediction loss, ......
FlashSpeech: Efficient Zero-Shot Speech Synthesis

Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5\% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio qualit......
SMPLer: Taming Transformers for Monocular 3D Human Shape and Pose Estimation

Existing Transformers for monocular 3D human shape and pose estimation typically have a quadratic computation and memory complexity with respect to the feature length, which hinders the exploitation of fine-grained information in high-resolution features that is beneficial for accurate reconstruction. In this work, we propose an SMPL-based Transformer framework (SMPLer) to address this issue. SMPLer incorporates two key ingredients: a decoupled attention operation and an SMPL-based target representation, which allow effective utilization of high-resolution features in the Transformer. In addition, based on these two designs, we also introduce several novel modules including a multi-scale attention and a joint-aware attention to further boost the reconstruction performance. Extensive experiments demonstrate the effectiveness of SMPLer against existing 3D human shape and pose estimation methods both quantitatively and qualitatively. Notably, the proposed algorithm achieves an M......
ID-Animator: Zero-Shot Identity-Preserving Human Video Generation

Generating high fidelity human video with specified identities has attracted significant attention in the content generation community. However, existing techniques struggle to strike a balance between training efficiency and identity preservation, either requiring tedious case-by-case finetuning or usually missing the identity details in video generation process. In this study, we present ID-Animator, a zero-shot human-video generation approach that can perform personalized video generation given single reference facial image without further training. ID-Animator inherits existing diffusion-based video generation backbones with a face adapter to encode the ID-relevant embeddings from learnable facial latent queries. To facilitate the extraction of identity information in video generation, we introduce an ID-oriented dataset construction pipeline, which incorporates decoupled human attribute and action captioning technique from a constructed facial image pool. Based on this p......
From Parts to Whole: A Unified Reference Framework for Controllable Human Image Generation

Recent advancements in controllable human image generation have led to zero-shot generation using structural signals (e.g., pose, depth) or facial appearance. Yet, generating human images conditioned on multiple parts of human appearance remains challenging. Addressing this, we introduce Parts2Whole, a novel framework designed for generating customized portraits from multiple reference images, including pose images and various aspects of human appearance. To achieve this, we first develop a semantic-aware appearance encoder to retain details of different human parts, which processes each image based on its textual label to a series of multi-scale feature maps rather than one image token, preserving the image dimension. Second, our framework supports multi-image conditioned generation through a shared self-attention mechanism that operates across reference and target features during the diffusion process. We enhance the vanilla attention mechanism by incorporating mask informa......
TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting
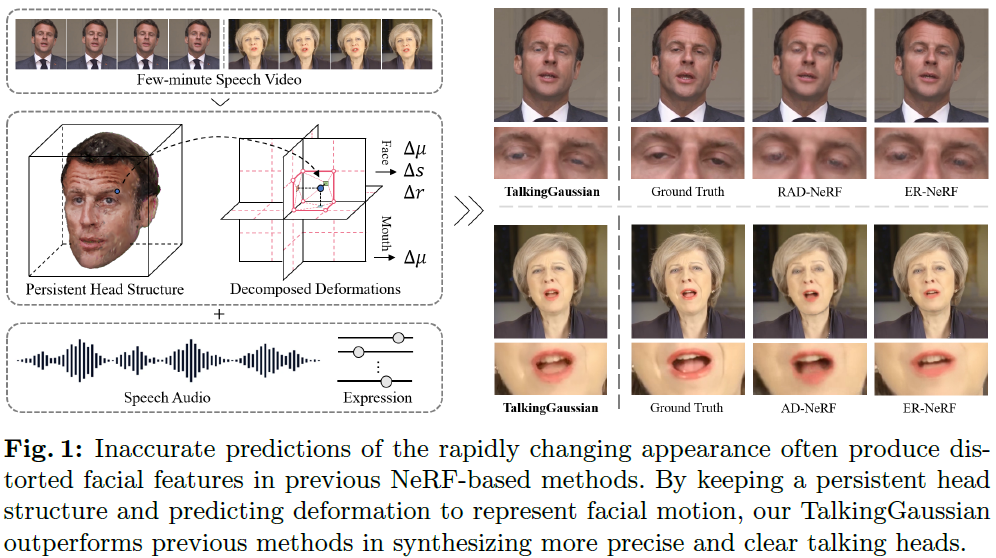
Radiance fields have demonstrated impressive performance in synthesizing lifelike 3D talking heads. However, due to the difficulty in fitting steep appearance changes, the prevailing paradigm that presents facial motions by directly modifying point appearance may lead to distortions in dynamic regions. To tackle this challenge, we introduce TalkingGaussian, a deformation-based radiance fields framework for high-fidelity talking head synthesis. Leveraging the point-based Gaussian Splatting, facial motions can be represented in our method by applying smooth and continuous deformations to persistent Gaussian primitives, without requiring to learn the difficult appearance change like previous methods. Due to this simplification, precise facial motions can be synthesized while keeping a highly intact facial feature. Under such a deformation paradigm, we further identify a face-mouth motion inconsistency that would affect the learning of detailed speaking motions. To address this c......
Multi-Session SLAM with Differentiable Wide-Baseline Pose Optimization
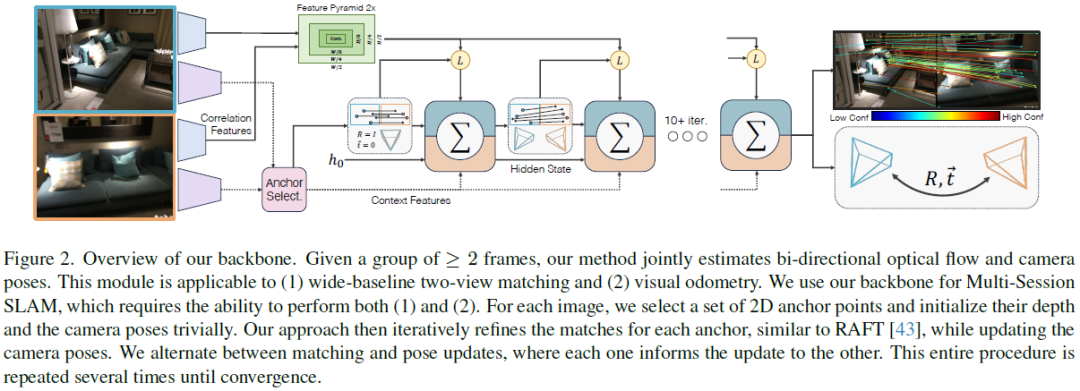
We introduce a new system for Multi-Session SLAM, which tracks camera motion across multiple disjoint videos under a single global reference. Our approach couples the prediction of optical flow with solver layers to estimate camera pose. The backbone is trained end-to-end using a novel differentiable solver for wide-baseline two-view pose. The full system can connect disjoint sequences, perform visual odometry, and global optimization. Compared to existing approaches, our design is accurate and robust to catastrophic failures. Code is available at github.com/princeton-vl/MultiSlam_DiffPose ......
FlowMap: High-Quality Camera Poses, Intrinsics, and Depth via Gradient Descent
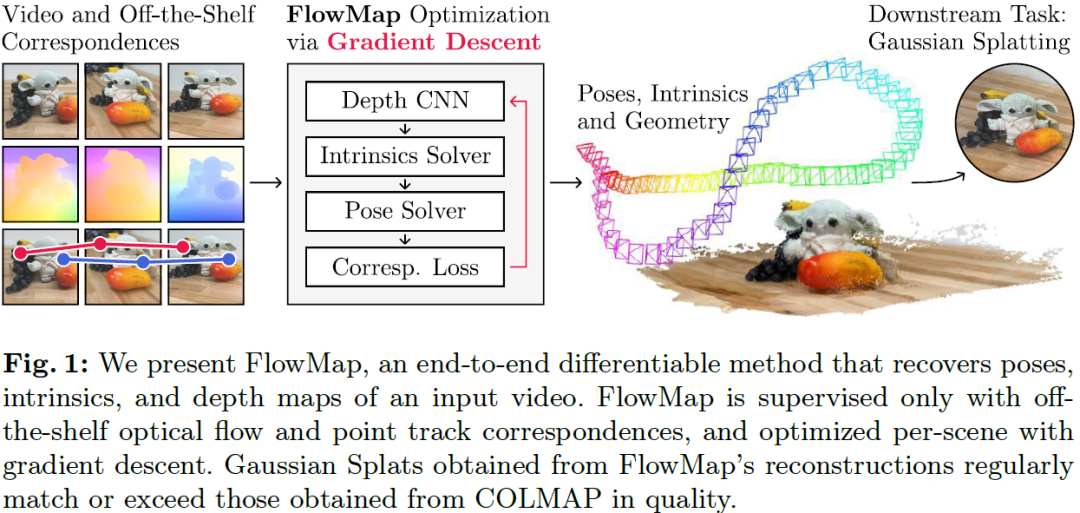
This paper introduces FlowMap, an end-to-end differentiable method that solves for precise camera poses, camera intrinsics, and per-frame dense depth of a video sequence. Our method performs per-video gradient-descent minimization of a simple least-squares objective that compares the optical flow induced by depth, intrinsics, and poses against correspondences obtained via off-the-shelf optical flow and point tracking. Alongside the use of point tracks to encourage long-term geometric consistency, we introduce differentiable re-parameterizations of depth, intrinsics, and pose that are amenable to first-order optimization. We empirically show that camera parameters and dense depth recovered by our method enable photo-realistic novel view synthesis on 360-degree trajectories using Gaussian Splatting. Our method not only far outperforms prior gradient-descent based bundle adjustment methods, but surprisingly performs on par with COLMAP, the state-of-the-art SfM method, on the dow......
Rethinking LLM Memorization through the Lens of Adversarial Compression
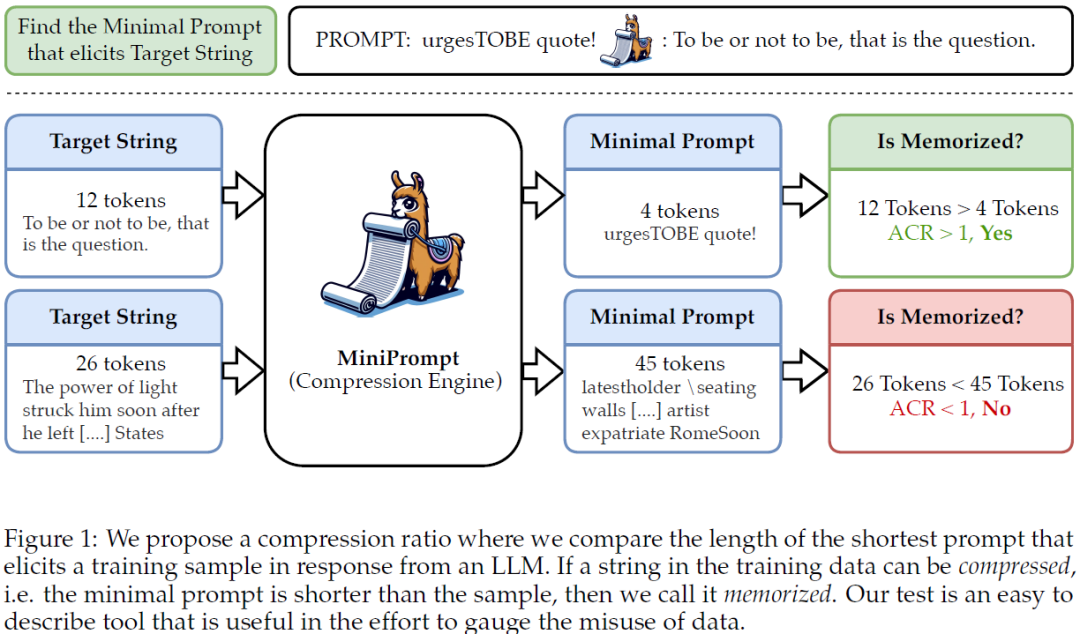
Large language models (LLMs) trained on web-scale datasets raise substantial concerns regarding permissible data usage. One major question is whether these models "memorize" all their training data or they integrate many data sources in some way more akin to how a human would learn and synthesize information. The answer hinges, to a large degree, on $\textit{how we define memorization}$. In this work, we propose the Adversarial Compression Ratio (ACR) as a metric for assessing memorization in LLMs -- a given string from the training data is considered memorized if it can be elicited by a prompt shorter than the string itself. In other words, these strings can be "compressed" with the model by computing adversarial prompts of fewer tokens. We outline the limitations of existing notions of memorization and show how the ACR overcomes these challenges by (i) offering an adversarial view to measuring memorization, especially for monitoring unlearning and compliance; and (ii) allow......
CutDiffusion: A Simple, Fast, Cheap, and Strong Diffusion Extrapolation Method

Transforming large pre-trained low-resolution diffusion models to cater to higher-resolution demands, i.e., diffusion extrapolation, significantly improves diffusion adaptability. We propose tuning-free CutDiffusion, aimed at simplifying and accelerating the diffusion extrapolation process, making it more affordable and improving performance. CutDiffusion abides by the existing patch-wise extrapolation but cuts a standard patch diffusion process into an initial phase focused on comprehensive structure denoising and a subsequent phase dedicated to specific detail refinement. Comprehensive experiments highlight the numerous almighty advantages of CutDiffusion: (1) simple method construction that enables a concise higher-resolution diffusion process without third-party engagement; (2) fast inference speed achieved through a single-step higher-resolution diffusion process, and fewer inference patches required; (3) cheap GPU cost resulting from patch-wise inference and fewer patch......
Taming Diffusion Probabilistic Models for Character Control

We present a novel character control framework that effectively utilizes motion diffusion probabilistic models to generate high-quality and diverse character animations, responding in real-time to a variety of dynamic user-supplied control signals. At the heart of our method lies a transformer-based Conditional Autoregressive Motion Diffusion Model (CAMDM), which takes as input the character's historical motion and can generate a range of diverse potential future motions conditioned on high-level, coarse user control. To meet the demands for diversity, controllability, and computational efficiency required by a real-time controller, we incorporate several key algorithmic designs. These include separate condition tokenization, classifier-free guidance on past motion, and heuristic future trajectory extension, all designed to address the challenges associated with taming motion diffusion probabilistic models for character control. As a result, our work represents the first mode......