本文首发于公众号:机器感知
ArtNeRF、Attention Control、Pixel is a Barrier、FilterPrompt

ArtNeRF: A Stylized Neural Field for 3D-Aware Cartoonized Face Synthesis

Recent advances in generative visual models and neural radiance fields have greatly boosted 3D-aware image synthesis and stylization tasks. However, previous NeRF-based work is limited to single scene stylization, training a model to generate 3D-aware cartoon faces with arbitrary styles remains unsolved. We propose ArtNeRF, a novel face stylization framework derived from 3D-aware GAN to tackle this problem. In this framework, we utilize an expressive generator to synthesize stylized faces and a triple-branch discriminator module to improve the visual quality and style consistency of the generated faces. Specifically, a style encoder based on contrastive learning is leveraged to extract robust low-dimensional embeddings of style images, empowering the generator with the knowledge of various styles. To smooth the training process of cross-domain transfer learning, we propose an adaptive style blending module which helps inject style information and allows users to freely tune t......
Rethink Arbitrary Style Transfer with Transformer and Contrastive Learning
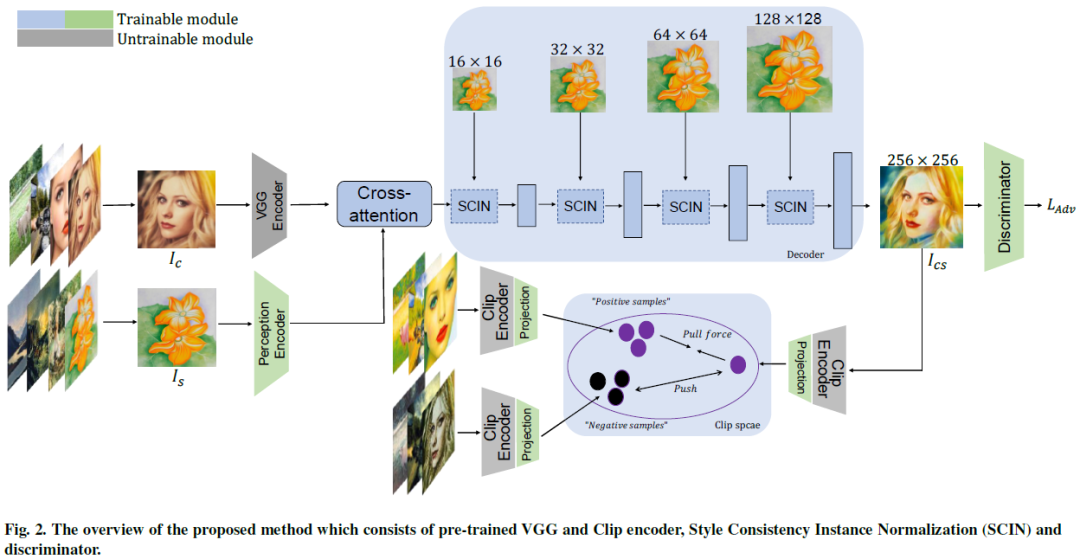
Arbitrary style transfer holds widespread attention in research and boasts numerous practical applications. The existing methods, which either employ cross-attention to incorporate deep style attributes into content attributes or use adaptive normalization to adjust content features, fail to generate high-quality stylized images. In this paper, we introduce an innovative technique to improve the quality of stylized images. Firstly, we propose Style Consistency Instance Normalization (SCIN), a method to refine the alignment between content and style features. In addition, we have developed an Instance-based Contrastive Learning (ICL) approach designed to understand the relationships among various styles, thereby enhancing the quality of the resulting stylized images. Recognizing that VGG networks are more adept at extracting classification features and need to be better suited for capturing style features, we have also introduced the Perception Encoder (PE) to capture style fe......
Exploring AIGC Video Quality: A Focus on Visual Harmony, Video-Text Consistency and Domain Distribution Gap
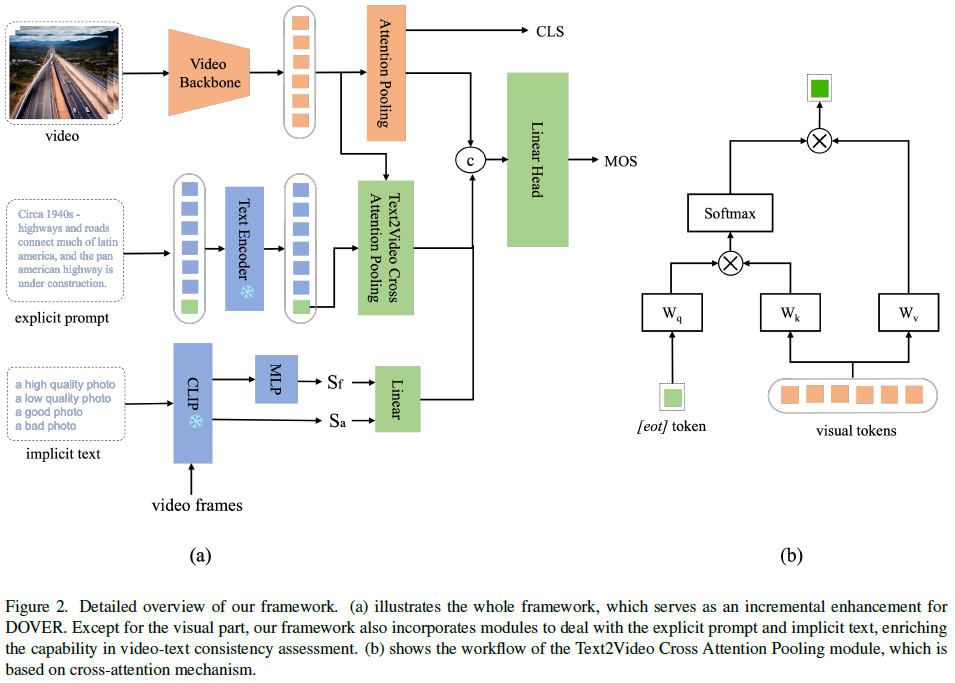
The recent advancements in Text-to-Video Artificial Intelligence Generated Content (AIGC) have been remarkable. Compared with traditional videos, the assessment of AIGC videos encounters various challenges: visual inconsistency that defy common sense, discrepancies between content and the textual prompt, and distribution gap between various generative models, etc. Target at these challenges, in this work, we categorize the assessment of AIGC video quality into three dimensions: visual harmony, video-text consistency, and domain distribution gap. For each dimension, we design specific modules to provide a comprehensive quality assessment of AIGC videos. Furthermore, our research identifies significant variations in visual quality, fluidity, and style among videos generated by different text-to-video models. Predicting the source generative model can make the AIGC video features more discriminative, which enhances the quality assessment performance. The proposed method was used......
LASER: Tuning-Free LLM-Driven Attention Control for Efficient Text-conditioned Image-to-Animation

Revolutionary advancements in text-to-image models have unlocked new dimensions for sophisticated content creation, e.g., text-conditioned image editing, allowing us to edit the diverse images that convey highly complex visual concepts according to the textual guidance. Despite being promising, existing methods focus on texture- or non-rigid-based visual manipulation, which struggles to produce the fine-grained animation of smooth text-conditioned image morphing without fine-tuning, i.e., due to their highly unstructured latent space. In this paper, we introduce a tuning-free LLM-driven attention control framework, encapsulated by the progressive process of LLM planning, prompt-Aware editing, StablE animation geneRation, abbreviated as LASER. LASER employs a large language model (LLM) to refine coarse descriptions into detailed prompts, guiding pre-trained text-to-image models for subsequent image generation. We manipulate the model's spatial features and self-attention mecha......
Generalizable Novel-View Synthesis using a Stereo Camera

In this paper, we propose the first generalizable view synthesis approach that specifically targets multi-view stereo-camera images. Since recent stereo matching has demonstrated accurate geometry prediction, we introduce stereo matching into novel-view synthesis for high-quality geometry reconstruction. To this end, this paper proposes a novel framework, dubbed StereoNeRF, which integrates stereo matching into a NeRF-based generalizable view synthesis approach. StereoNeRF is equipped with three key components to effectively exploit stereo matching in novel-view synthesis: a stereo feature extractor, a depth-guided plane-sweeping, and a stereo depth loss. Moreover, we propose the StereoNVS dataset, the first multi-view dataset of stereo-camera images, encompassing a wide variety of both real and synthetic scenes. Our experimental results demonstrate that StereoNeRF surpasses previous approaches in generalizable view synthesis. ......
Motion-aware Latent Diffusion Models for Video Frame Interpolation
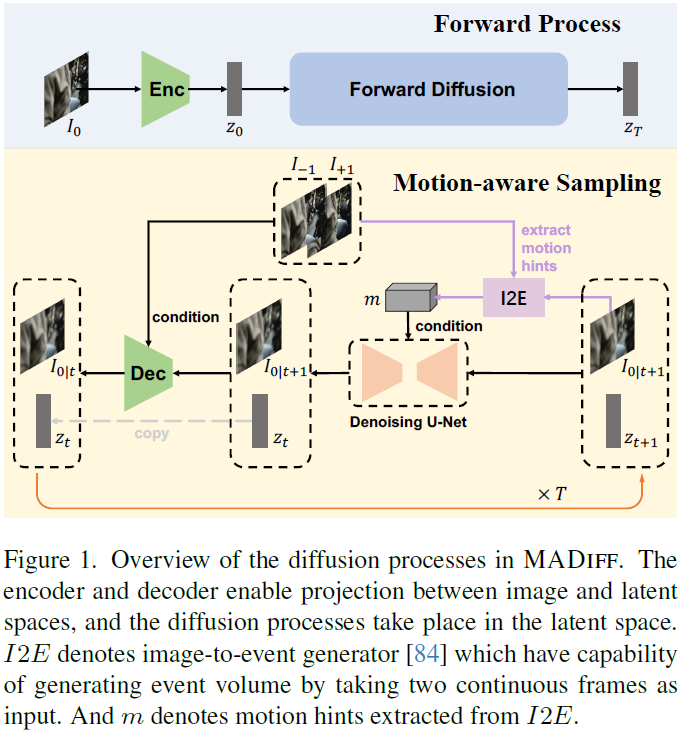
With the advancement of AIGC, video frame interpolation (VFI) has become a crucial component in existing video generation frameworks, attracting widespread research interest. For the VFI task, the motion estimation between neighboring frames plays a crucial role in avoiding motion ambiguity. However, existing VFI methods always struggle to accurately predict the motion information between consecutive frames, and this imprecise estimation leads to blurred and visually incoherent interpolated frames. In this paper, we propose a novel diffusion framework, motion-aware latent diffusion models (MADiff), which is specifically designed for the VFI task. By incorporating motion priors between the conditional neighboring frames with the target interpolated frame predicted throughout the diffusion sampling procedure, MADiff progressively refines the intermediate outcomes, culminating in generating both visually smooth and realistic results. Extensive experiments conducted on benchmark ......
Music Consistency Models
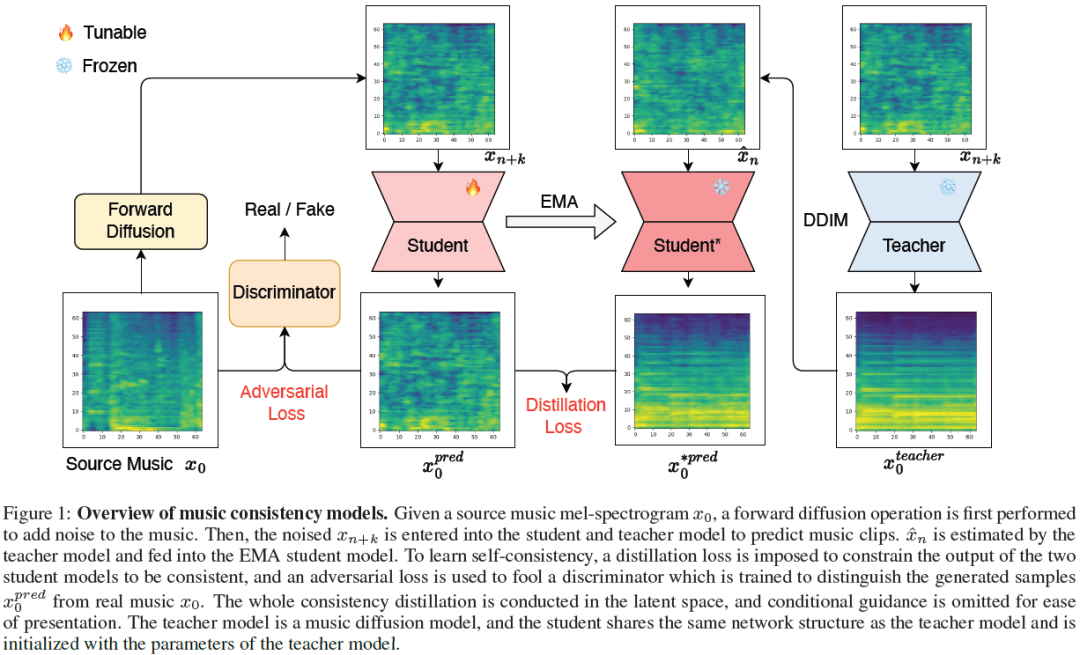
Consistency models have exhibited remarkable capabilities in facilitating efficient image/video generation, enabling synthesis with minimal sampling steps. It has proven to be advantageous in mitigating the computational burdens associated with diffusion models. Nevertheless, the application of consistency models in music generation remains largely unexplored. To address this gap, we present Music Consistency Models (\texttt{MusicCM}), which leverages the concept of consistency models to efficiently synthesize mel-spectrogram for music clips, maintaining high quality while minimizing the number of sampling steps. Building upon existing text-to-music diffusion models, the \texttt{MusicCM} model incorporates consistency distillation and adversarial discriminator training. Moreover, we find it beneficial to generate extended coherent music by incorporating multiple diffusion processes with shared constraints. Experimental results reveal the effectiveness of our model in terms of......
EC-SLAM: Real-time Dense Neural RGB-D SLAM System with Effectively Constrained Global Bundle Adjustment

We introduce EC-SLAM, a real-time dense RGB-D simultaneous localization and mapping (SLAM) system utilizing Neural Radiance Fields (NeRF). Although recent NeRF-based SLAM systems have demonstrated encouraging outcomes, they have yet to completely leverage NeRF's capability to constrain pose optimization. By employing an effectively constrained global bundle adjustment (BA) strategy, our system makes use of NeRF's implicit loop closure correction capability. This improves the tracking accuracy by reinforcing the constraints on the keyframes that are most pertinent to the optimized current frame. In addition, by implementing a feature-based and uniform sampling strategy that minimizes the number of ineffective constraint points for pose optimization, we mitigate the effects of random sampling in NeRF. EC-SLAM utilizes sparse parametric encodings and the truncated signed distance field (TSDF) to represent the map in order to facilitate efficient fusion, resulting in reduced mode......
Pixel is a Barrier: Diffusion Models Are More Adversarially Robust Than We Think

Adversarial examples for diffusion models are widely used as solutions for safety concerns. By adding adversarial perturbations to personal images, attackers can not edit or imitate them easily. However, it is essential to note that all these protections target the latent diffusion model (LDMs), the adversarial examples for diffusion models in the pixel space (PDMs) are largely overlooked. This may mislead us to think that the diffusion models are vulnerable to adversarial attacks like most deep models. In this paper, we show novel findings that: even though gradient-based white-box attacks can be used to attack the LDMs, they fail to attack PDMs. This finding is supported by extensive experiments of almost a wide range of attacking methods on various PDMs and LDMs with different model structures, which means diffusion models are indeed much more robust against adversarial attacks. We also find that PDMs can be used as an off-the-shelf purifier to effectively remove the adver......
FilterPrompt: Guiding Image Transfer in Diffusion Models

In controllable generation tasks, flexibly manipulating the generated images to attain a desired appearance or structure based on a single input image cue remains a critical and longstanding challenge. Achieving this requires the effective decoupling of key attributes within the input image data, aiming to get representations accurately. Previous research has predominantly concentrated on disentangling image attributes within feature space. However, the complex distribution present in real-world data often makes the application of such decoupling algorithms to other datasets challenging. Moreover, the granularity of control over feature encoding frequently fails to meet specific task requirements. Upon scrutinizing the characteristics of various generative models, we have observed that the input sensitivity and dynamic evolution properties of the diffusion model can be effectively fused with the explicit decomposition operation in pixel space. This integration enables the ima......
BACS: Background Aware Continual Semantic Segmentation
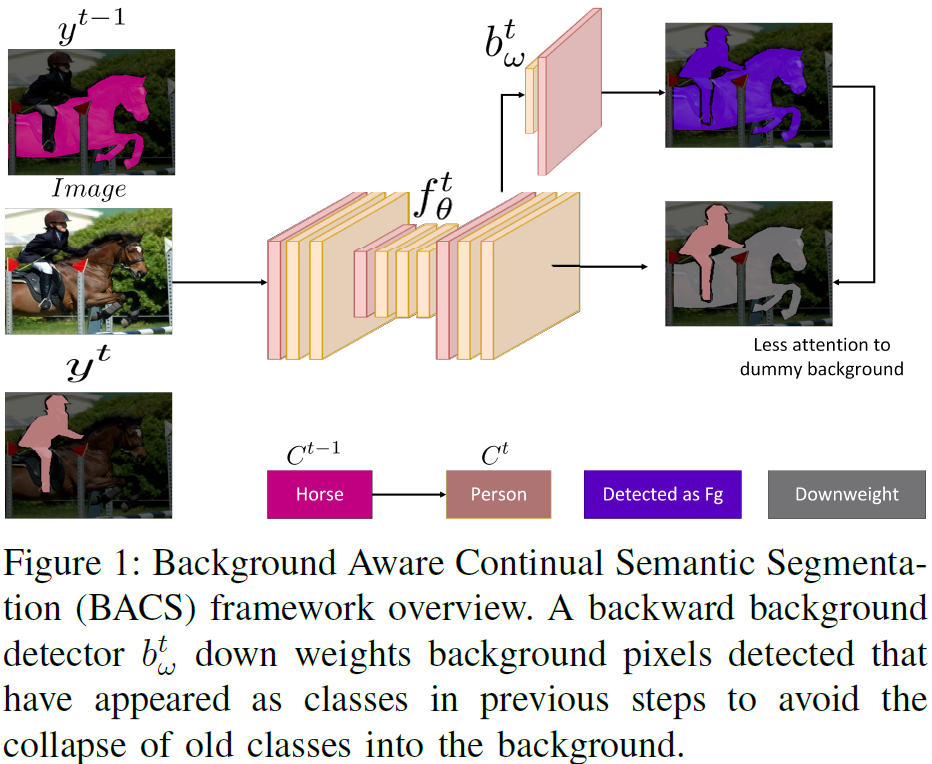
Semantic segmentation plays a crucial role in enabling comprehensive scene understanding for robotic systems. However, generating annotations is challenging, requiring labels for every pixel in an image. In scenarios like autonomous driving, there's a need to progressively incorporate new classes as the operating environment of the deployed agent becomes more complex. For enhanced annotation efficiency, ideally, only pixels belonging to new classes would be annotated. This approach is known as Continual Semantic Segmentation (CSS). Besides the common problem of classical catastrophic forgetting in the continual learning setting, CSS suffers from the inherent ambiguity of the background, a phenomenon we refer to as the "background shift'', since pixels labeled as background could correspond to future classes (forward background shift) or previous classes (backward background shift). As a result, continual learning approaches tend to fail. This paper proposes a Backward Backgro......