Linux:进程创建 & 进程终止
- 进程创建
- fork
- 写时拷贝
- 进程终止
- 退出码
- strerror
- errno
- 异常信号
- exit
进程创建
fork
fork函数可以用于在程序内部创建子进程,其包含在头文件<unistd.h>中,直接调用fork()就可以创建子进程了。
示例代码:
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("before: ppid = %d,pid = %d\n", getppid(), getpid());
fork();
printf("after: ppid = %d,pid = %d\n", getppid(), getpid());
return 0;
}
以上代码中,我们在fork前输出了一个before以及进程的PID和PPID。在fork后,又输出了after以及进程的PID和PPID。
运行结果:

可以看到,我们的before输出了一次,也就是我们调用的进程./test.exe输出的,而after输出了两次,但是我们只有一个after语句,说明有两个不同的进程执行了这个语句,也就是fork成功创建了一个进程。
对于第一条语句before,毫无疑问这是进程./test.exe输出的,PID为22840。
第二条语句after,其PID和PPID都和./test.exe一致,说明这个语句也是原先的./test.exe输出的。
第三条语句after,其PID为22842,之前没有出现过,说明这个是通过fork创建出来的进程,其PPID为22840,也就是./test.exe,说明fork创建出来的进程,是原先进程的子进程。
以上示例可以总结为:
fork之后,会出现两个进程
- 一个是原先的进程
- 另外一个是通过
fork创建的进程
- 新创建的进程,是原先进程的子进程
fork函数也是有返回值的,其返回规则如下:
- 对于父进程,返回值为新的进程的
PID- 对于子进程,返回值为
0
此时我们就可以根据fork的返回值,来判断父子进程了:
代码示例:
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
printf("child: ppid = %d,pid = %d\n", getppid(), getpid());
}
else
{
printf("father: ppid = %d,pid = %d\n", getppid(), getpid());
}
return 0;
}
输出结果:

子进程输出了child:开头的语句,父进程输出了father:开头的语句。
我们确实通过这样的分支语句,利用父子进程的fork返回值不同的特性,完成了父子进程输出不同的代码。
其实fork创建子进程的时候,是以父进程为模板的,子进程会继承父进程的PCB,然后把PCB内部需要修改的地方改为自己的,比如PID,PPID是不同的。
子进程还和父进程共用代码段,因为两者的代码逻辑是一样的。比如说刚才的示例中,父子进程都要执行if-else的判断,两者都共用这一段代码。
但是两者的数据不一定相同,一开始父子进程共用一段数据,一旦父子进程有一方要对数据进行修改,那么就发生写时拷贝,此时数据就互不影响了。如果某个数据从头到尾都没有被修改,那么这个数据从头到尾都被父子进程共享,不会额外开辟内存。
现在就有一个问题了:为什么一个id既可以得到父进程的返回值,又可以得到子进程的返回值,难道fork函数可以一次返回两个值吗?
PCB内部有一个叫做内存指针的成员:
- 内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
其可以标识当前代码执行到了哪里,那么在父进程执行到fork的时候,此时就要开始创建子进程了,子进程会继承父进程的PCB。
由于父进程此时执行到fork,那么内存指针就指向fork这个语句。由于子进程继承父进程PCB,因此刚创建的子进程继承的内存指针也指向fork,所以子进程是从fork开始往后执行的。
那么下一个问题就是:fork函数是如何做到,一个函数返回两个值的呢?
回答这个问题之前,我先反问你一个问题,创建子进程是在什么时候创建的?
你也许会回答,就是fork的时候创建的,但是深究一下,你就会发现,一定是在fork函数内部创建的子进程。这个内部很关键,也就是说在fork函数还没有return返回的时候,就已经是两个进程了。
于是两个进程共用这个fork的代码,但是两个进程的数据不一样,所以其实pid_t id = fork();这个过程中,父子进程分别return了一次。所以本质上不是fork函数返回了两个值,而是同一段return代码,被父子进程分别调用了。
写时拷贝
通过fork创建子进程的时候,会继承父进程的代码,数据,页表,PCB等等,因此我们会发现fork之后,父子进程指向的代码是一样的。
比如以下代码:
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("process start!\n");
fork();
printf("hello world!\n");
printf("hello Linux!\n");
printf("hello process!\n");
return 0;
}
以上代码中,进程先输出了一句"process start!\n",随后在fork之后又输出了三条语句。
输出结果:

可以看到的是,fork前的语句只输出了一次,而fork后的语句都输出了两次,也就是被父子进程分别输出了一次,由此可证子进程会继承父进程的代码。
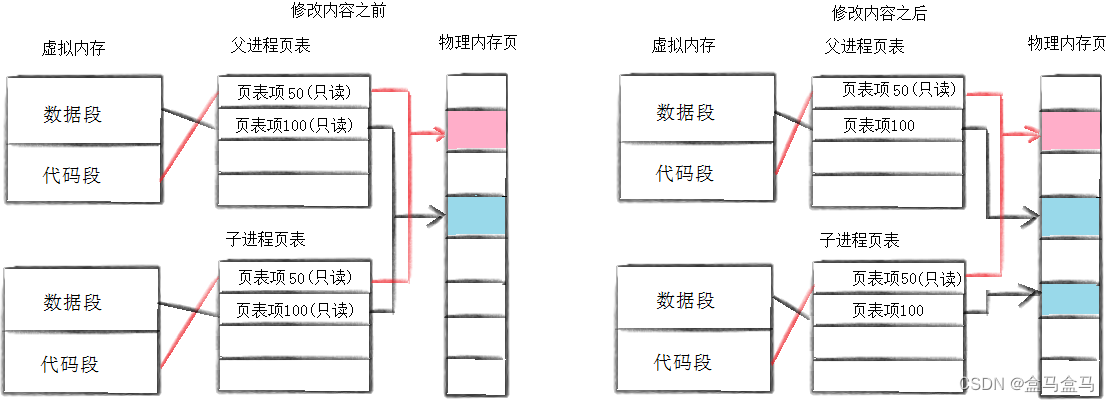
上图中,左侧是刚fork后的父子进程,子进程创建时页表几乎完全一致,最后导致不论是数据还是代码都指向了内存中的同一块区域。
但是页表中大部分的项权限都被改为了只读,当子进程想要修改数据,就会在页表中访问该虚拟地址,但是页表发现该地址是只读的,于是页表暂时终止进程访问内存的请求,这个过程叫做缺页中断。
接着向上层汇报,操作系统介入。操作系统再进而分析得知,子进程想要对这块内存写入,于是发生写时拷贝。操作系统重新开一块内存给子进程,然后修改页表中的数据,一是修改虚拟地址与物理地址的映射关系,二是修改该内存的权限,从只读变为读写。
右图中,蓝色区域被拷贝了一份到内存的其他区域,然后子进程的页表不再指向原先的区域,而是指向新开辟的区域。
那么借此机会,我再深入讲解一下C/C++中的const语法。
比如以下代码:
const char* str = "Hello World!";
*str = "Hello Linux";
毫无疑问这是一段错误的代码,因为str是const修饰的指针,不能通过该指针修改指向的值。但是从底层来说,其实本质上是在页表中,进程没有该地址的读写权限,只有只读权限。如果我们没有const这个语法,那么进程就有可能会向页表发出写入的申请,可是页表发现进程没有该地址的写入权限。因此页表会缺页中断,操作系统分析后发现这是非法访问,直接终止进程。
可见这是一个比较危险的过程,一旦访问没有权限的内存,很有可能就会直接终止程序。最典型的就是指针越界,访问野指针等等。而C/C++使用一个const修饰的语法,将问题提前暴露出来,对于一些已经确定不能写入的常量区地址,要求用const修饰,只要不用const修饰,在编译时就不允许通过,将问题提前暴露出来,从而提高程序的健壮性。
进程终止
讲解完进程的创建后,我们来看看进程是如何退出的,以及退出后会留下些什么。
退出码
在平常的C语言代码中,main函数最后的return其实返回的是退出码:
- 如果错误码为
0,表示程序正常退出- 如果错误码非
0,表示程序异常退出
因此大部分时候我们会return 0,表示程序正常返回。
环境变量?内部存储了上一个进程的退出码,我们可以在该进程执行完后,使用echo $?来输出上一个进程的退出码。
假设在test.exe中执行如下代码:
int main()
{
return 123;
}
那么该进程的退出码就是123,我们输出试试看:

通过main函数的return,我们确实可以控制进程的退出码,那么这个退出码有什么用呢?
其实每一个错误码都对应了一个进程的错误信息,可以通过strerror函数来输出错误码对应的错误信息。
strerror
strerror函数包含在头文件<string.h>中,传入一个错误码作为参数,返回指向错误信息的字符串。
我们用以下代码来输出前十条错误信息:
#include <stdio.h>
#include <string.h>
int main()
{
for(int i = 0; i < 10; i++)
{
printf("%d:%s\n", i, strerror(i));
}
return 0;
}
输出结果如下:
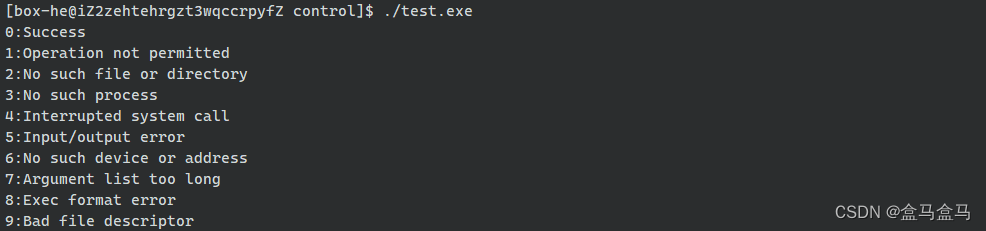
比如0表示Success即执行成功,1表示Operation not permitted即操作不被允许。
比如现在我们ls一个不存在的文件夹:

此时ls报错No such file or directory,即该文件或目录不存在,这条语句和错误码2完全一致,而我们再echo $?发现,上一个进程的退出码就是2。
那么现在又有一个问题:进程通过main函数的返回值来判断错误,那么对一般的函数,我们要如何得知函数的执行情况?
errno
函数的返回值是用于返回调用结果的,不适合用作返回错误码,全局变量errno包含在头文件<errno.h>中,其存储了上一次函数调用的错误码。
比如以下代码:
#include <stdio.h>
#include <string.h>
#include <errno.h>
void func()
{
errno = 10;
}
int main()
{
func();
printf("%d:%s\n", errno, strerror(errno));
return 0;
}
以上代码中func函数修改了全局变量errno,此时就可以在函数外部检测errno来判断函数的调用情况了,此处在func中令errno = 10,然后在函数调用结束后输出errno以及其对应的错误信息:

而在库函数中,也会使用errno的,比如fopen函数,当fopen发生错误时,就会修改errno来返回错误信息。
示例:
#include <stdio.h>
#include <string.h>
#include <errno.h>
void func()
{
errno = 10;
}
int main()
{
fopen("123.c", "r");
printf("%d:%s\n", errno, strerror(errno));
return 0;
}
在当前目录下,不存在一个叫做123.c的文件,我们用fopen以r形式打开,那么fopen是打不开文件的,于是就会向errno进行写入。
执行结果:

输出了错误码2,即没有对应的文件或目录。
异常信号
对于任意一个进程,都只有两种退出情况:
- 代码执行完毕,正常退出
- 进程发生了异常,被迫退出
比如说访问空指针,野指针,除零错误等等,这些都会导致进程直接终止。
除零错误:即把0当作除数,这是不允许的
比如在test.exe中执行:
double a = 5 / 0;
输出结果:

其报出一个错误Floating point exception说明可能存在 / 或者 % 的除数为 0 的情况,这就说明进程发生了异常。
进程发生异常的本质,是收到了异常信号
我们可以通过kill -l来查看异常信号:
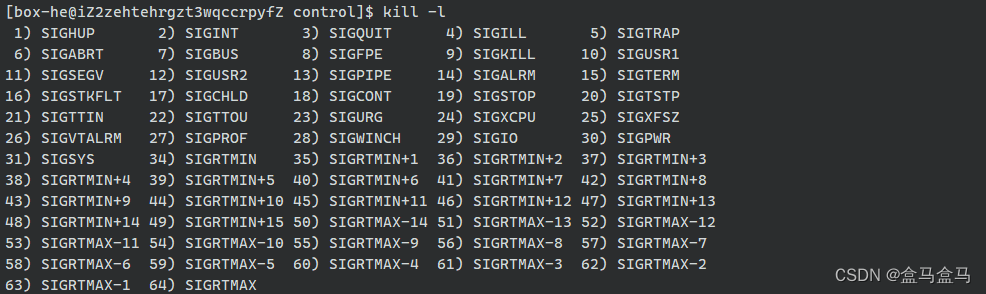
如果想要对一个进程发送异常信号,只需要kill -xxx ###即可向pid为###的进程发送xxx号信号。
比如8号信号SIGFPE,其中SIG表示signal信号,而FPE是Floating point exception的缩写,也就是刚刚的除零错误。刚刚除零错误异常退出,就是接收到了8号信号。
现在我们在test.exe中执行以下代码,来验证异常信号:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <errno.h>
int main()
{
while(1)
{
printf("pid = %d\n", getpid());
sleep(1);
}
return 0;
}
该程序会陷入死循环,然后每隔一秒输出自己的pid,得到pid是为了可以发送信号。当进程执行起来后我们在另外一个对其发送8信号:
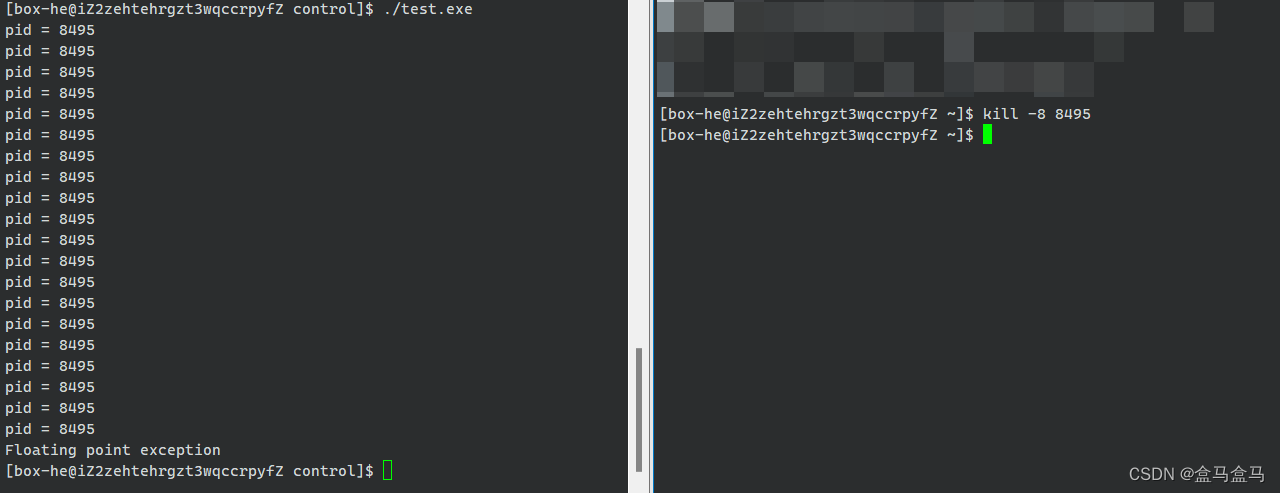
左侧窗口执行进程后,pid=8495,右侧窗口执行指令kill -8 8495,就向8495发送了8号信号,此时进程直接退出,并输出Floating point exception。可以看到,明明是一个死循环,我们可以通过发送异常信号直接终止,而代码中明明没有除零错误,我们也可以通过信号对其强行加上异常。
exit
exit函数可以用于在进程中直接退出,其包含在头文件<stdlib.h>中。
示例:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
void func()
{
exit(5);
}
int main()
{
func();
return 0;
}
在函数func中,调用了exit(5),此时整个进程都会直接退出,并且返回错误码5。
输出结果:

可以看到,进程的退出码是5,说明通过exit退出了。
那么exit和main的return有什么不同呢?其实以上案例已经很好地说明了:
exit不论在哪一个函数中执行,都是直接终止整个进程
但是exit其数有两个版本,一个是<unistd.h>中的_exit:
另外一个是<stdlib.h>中的exit:
可以看出,_exit在man的第二页,是系统调用接口,而exit在man的第三页,是用户操作接口。但是两者的函数几乎完全一致,都是void exit(int status),因此两者效果几乎完全一致。
除了操作系统层面不同,另外的区别就是:exit会刷新缓冲区,而_exit不会刷新缓冲区。
毫无疑问的是,_exit是系统调用接口,更接近底层,exit中一定封装了_exit+刷新缓冲区两个功能。而在其它的操作系统中,终止进程的接口不一定是_exit,因此exit在不同操作系统中封装的接口大概率是不一致的。