概述
在自然语言处理(NLP)领域,大型语言模型的发展一直是研究的热点。这些模型通过增加参数数量和训练数据量来提升性能,但这种增长趋势是否会有一个极限?实际上,研究者们已经注意到,为了有效地训练这些拥有海量参数的语言模型,所需的训练数据量也同样庞大。
以Gopher模型为例,它拥有2800亿个参数,而Chinchilla模型虽然只有700亿个参数,但由于其训练数据量是Gopher的四倍,因此在性能上更胜一筹。这表明,单纯的参数数量增长并不一定能够带来性能上的提升,除非我们能够提供相应增长的、高质量的训练数据。
这种现象可以通过“缩放规则”(Scaling Laws)来解释,它描述了模型规模和性能之间的关系。缩放规则指出,为了实现性能上的提升,我们需要按照特定的比例增加模型的参数数量和训练数据量。然而,这种增长模式在实际应用中可能会遇到瓶颈,因为可用的高质量数据是有限的,而且模型规模的增加也会带来计算资源和效率上的挑战。
例如,MT-NLG 是一个拥有 580 亿个参数的大型语言模型,在应用于龙猫缩放定律时,可能需要在 30 TB 的文本上进行训练。换句话说,要想通过增加模型参数数量来获得无限好的性能,所需的数据量可能远远超过互联网上现有的可训练文本数据集。
这里介绍的论文基于这些可能性,提出了语言模型在训练数据数量有限时的数据约束扩展法则。此外,本文还提出了一种在数据有限的情况下提高语言模型性能的方法。
源码地址:https://github.com/huggingface/datablations
论文地址:https://arxiv.org/pdf/2305.16264.pdf
分配和回报
在考虑语言模型的缩放法则时,分配和回报是重要的概念。扩展法则是这样一条法则:"语言模型中可以增加哪些内容来提高语言模型的性能?其背景是希望通过优化有限计算资源的分配(Allocation)来最大化投资回报(Return),从而提高语言模型的性能。
举个形象的例子,子弹头列车的速度需要提高。换句话说,如果将越来越多的资金用于改进新干线的车体和发动机,速度就会提高。然而,预算是有限的。他们不确定应该投入多少资金来改进新干线车身(减少空气阻力)或改进新干线电机(提高电机输出功率)。因此,他们希望了解新干线速度、新干线车体改进和新干线电机改进之间的关系,并做出最佳预算分配,以便在当前预算有限的情况下获得最大的速度改进效果。
子弹头列车速度的提高→语言模型性能(预测准确性)的提高",“金钱→计算资源”,如果再联想到 "车身空气阻力→模型参数数量 "和 “电机输出功率→训练数据数量”,那么这就是语言模型的缩放定律。
问题是:随着计算资源的增加,语言模型的性能能提高多少?在给定计算资源的限制下,模型参数数量和训练数据数量的最佳分配是什么?问题是
因此,如果计算资源的预算越多,基本模型和语言模型的预测准确率就会越高,但对于每种预算,模型参数和训练数据数量的最佳值是多少?这就是缩放法则。因此,在缩放法则的背后,存在着这样一个优化问题。
缩放规则
以往的研究假设数据取之不尽,用之不竭。
因此,在背景优化问题(等式 1)中,对训练数据的数量没有限制。
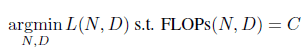
等式 1.传统缩放定律背后的最小化问题。
在公式 1 中,预测误差 L(L 越小,语言模型的性能越好)是需要最小化的函数,它取决于模型参数 N 的数量和训练标记 D 的数量。在计算资源为 C 的约束条件下,多少个模型参数 N 和多少个训练数据 D 能使 L 最小化?这就是最小化问题。
计算资源数量的计量单位是 “FLOPs”。FLOPs "是衡量计算机计算速度的单位。FLOPs 值越高的计算机运算速度越快。对于需要高级计算的任务(如游戏或科学模拟)来说,这是一个重要的性能指标,因为 FLOPs 似乎更像是计算速度的衡量标准,而不是计算资源的衡量标准,这似乎有点不妥。
就目前的情况而言,当只有一台速度较慢的计算机时,过多的模型参数和过多的训练数据将无法实际完成学习过程。那么,在只有一台慢速计算机的情况下,模型参数数量和训练数据数量的合适设定值是多少,才能在实际计算时间内达到最大预测精度呢?这或许值得考虑。
以往的研究预测,语言模型因计算资源输入而产生的性能提升效应(Return)与训练语言模型所用计算资源的平方成正比。根据这一假设,为了与实际实验数据相匹配,它与多少平方成正比?比例系数是多少?
计算资源分配的最佳平衡(Allocation)大致是指在不断增加的训练数据数量和模型参数数量之间平均分配。
拟议的数据约束缩放
为了研究如何充分利用有限的数据,本文提出了一种缩放规则,该规则施加了有限数据和计算资源的限制。
技术要点 1. 将训练代币总数分解为唯一训练代币数和迭代次数,并查看迭代次数的新投资回报率
在所提出的数据限制缩放规则中,栗鼠缩放规则中的训练数据数量 D 被重新定义为训练标记总数 D,以深化数据限制下的考虑。换句话说,该定义不再简单地看与所给训练数据数量的相关性,而是将多次训练的同一数据也算作训练标记数。
然后,训练标记总数 D 被分解为唯一训练标记数 U_D 和迭代次数 R(epoch 数 - 1)。迭代次数是一个数字,表示在深度学习的训练过程中使用了整个训练数据的多少次迭代。一旦全部训练数据用完,则算作一个epoch。一般来说,epoch 越多,给定训练数据的预测准确率就越高。另一方面,过多的epoch会导致对训练数据的过度训练和对未知数据的预测性能低下。以往研究中的缩放规则只考虑了迭代次数 R=0。本文的新颖之处在于研究了 R > 0 的情况,即 R 的投资回报率。
对于模型参数个数 N,为了表达的一致性,拟合一个唯一标记所需的基本模型参数个数为 U_N,该赋值的迭代次数为 R_N。
技术要点 2.设置唯一训练代币的数量上限
在传统的栗鼠缩放定律中,只有计算资源受到限制。在数据约束下的缩放定律中,唯一训练标记 U_C 有一个新的预算 D_C。因此,在公式 1 所示的最小化问题中增加了新的唯一训练标记数 U_D ≤ 唯一数据预算 D_C 约束。
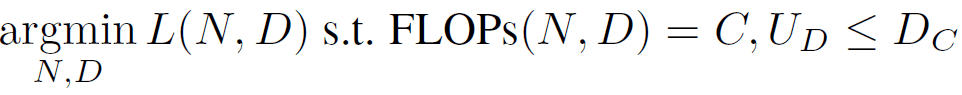
公式 2.数据受限缩放规则背后的最小化问题。
为了与实际实验数据相匹配,N 和 D 的幂的比例系数是多少?比例系数是多少?
数据约束缩放规律
介绍了数据约束缩放定律与实际实验数据拟合的主要结果。
图 1 显示了对训练数据进行迭代训练(重复训练)时的计算资源投资回报。
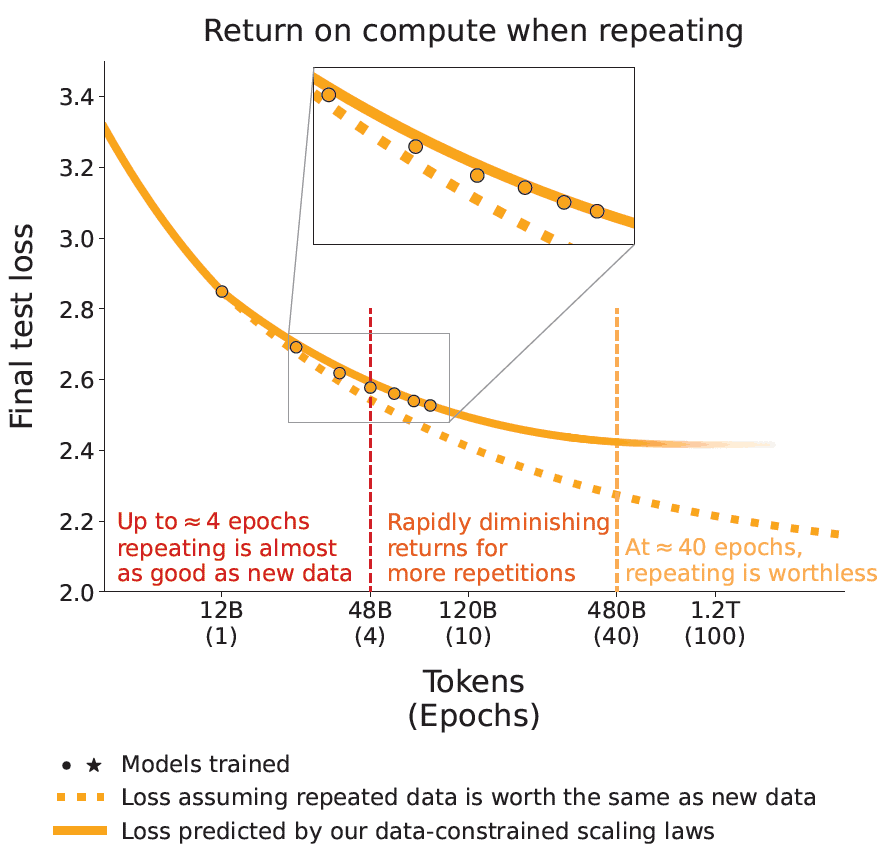
图 1:训练数据迭代训练期间计算资源的投资回报。
在图 1 中,横轴是标记数(历时),纵轴是语言模型的测试误差(越小性能越好)。橙色实线是根据数据约束缩放规则预测的语言模型测试误差。橙色虚线是假设标记数都是唯一标记(新数据)时的测试误差。
从图中可以看出,在 4 个 epochs 之前,对相同数据的重复训练与添加新数据具有相同的性能提升效果;从 4 个 epochs 到 40 个 epochs,性能提升效果迅速下降;40 个 epochs 之后,准确率提升效果消失。从 4 个 epoch 到 40 个 epoch,性能提升效果迅速下降;40 个 epoch 之后,准确度提升效果消失。
图 2 显示了训练数据迭代训练过程中计算资源的最佳分配值。

图 2.训练数据迭代训练过程中计算资源的最佳分配。
蓝色虚线是计算资源数量相同时的结果。黑线是代币数为所有唯一代币(新数据)时的最优分配预测,红线是根据数据约束缩放规律得出的最优分配预测。蓝色虚线与黑线的交点和蓝色虚线与红线的交点是在给定相同计算预算的情况下,有数据限制和无数据限制(迭代学习)的最优分配之间的差异。
从图中可以看出,在数据受限的情况下,作为计算资源的分配平衡,增加历元数比增加模型参数数更好。这是与传统的栗鼠缩放规则的不同之处。
数据补充
数据受限缩放规则表明,即使独特数据有限,增加历时次数也能在一定程度上提高性能。但同时也表明,增加历时次数对性能的提高是有限度的。因此,本文提出了一种补充独特数据不足的方法。

图 3:独特的数据完成方法。
如图 3 所示,除了目前所述的对唯一数据的迭代学习(重复)外,我们还提出了一种通过填充程序代码(填充代码)和对唯一数据进行排序(过滤)来进行迭代学习的方法。
顾名思义,"用代码填充 "就是在缺乏自然语言文本数据的情况下为程序提供代码。
从字面上理解,过滤也意味着对分类后的数据进行学习。在这种情况下,我们提出了两个过滤器:重复过滤器(Deduplicate)和复杂性过滤器(Perplexity):重复过滤器去除重复的文本,而复杂性过滤器只收集对语言模型的预测具有高置信度的文本。(Perplexity 是一个指标,perplexity 越小,语言模型预测的可信度就越高。例如,如果有两个句子,A:"The cat is curled up in the kotatsu "和 B:“The cat is curled up on the apple”,那么更有可能的句子是 “The cat is curled up in the kotatsu”。因此,句子 A 的 PERPLEXITY 要小于句子 B。)
评估结果
独特数据完成方法的评估结果如图 4 所示。
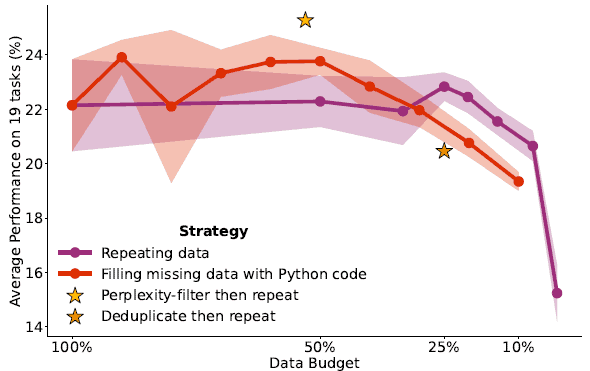
图 4:补充方法的评估结果。
纵轴为 19 项任务的平均性能,横轴为数据预算。模型参数数为 42 亿,唯一令牌总数为 840 亿。横轴上 100% 的数据预算指的是 840 亿个代币。图中每一点都是使用不同种子训练模型五次的平均值,标准偏差以阴影显示。
用代码填充的效果
图中紫线表示对训练数据进行迭代训练的结果,红线表示用 python 代码代替迭代训练的结果。在数据预算较低时,没有性能提升效果,导致性能下降。当数据预算较大时,给出 python 代码会有性能提升,但性能提升效果不稳定。至少似乎没有性能下降的副作用。
论文报告了添加 python 代码的效果,显示了在 WebNLG 和 bAbI 任务上性能的显著提高,其中 WebNLG 是将结构数据(如 Taro Nippon,生日,2000_01_01)转化为句子的生成任务,而 bAbI 是逻辑推理。我们假设,学习 python 代码可能提供了随时间跟踪状态的能力,而这正是这些任务所必需的。
论文指出,通过在 "代码填充 "中加入程序代码并进行 4 次历时迭代训练,将数据量增加一倍,使训练标记总数增加了 8 倍,而这一训练标记总数与唯一标记数量一样有效。
过滤的效果
图中的星星显示的是对数据进行分类后反复训练的结果。虽然看不清楚,但白色的星星是 Perplexity 过滤器的结果,橙色的星星是 Deduplicate 过滤器的结果。在这个基准测试中,Deduplicate 过滤器似乎没有任何改进。另一方面,Perplexity 筛选器显示出了一些改进。
该论文认为,使用重复数据过滤器(Deduplicate filter)后效果没有改善,可能是由于以前的研究曾报告过数据重复对语言模型产生负面影响的案例,而且以前研究中的基准可能是有效的。
从根本上说,过滤器的有效性背后的逻辑首先在于,它们通过排除这些异常高的数据或不可能的句子,解决了出现次数异常多的句子或一般不可能的句子的过度拟合问题,降低了一般句子的处理能力
论文指出,只有在噪声数据集中加入滤波器,才能提高性能。
总结
在本文所述的论文中,提出了一种使用有限训练数据的语言模型性能改进规则。结果表明,即使使用相同的训练数据,迭代训练也能将性能提高到大约四个历元,这与添加不同训练数据的效果类似。
关于模型参数数和训练代币总数的优化分配,结果表明,在计算资源相同的情况下,减少模型参数数和增加训练代币总数比传统的缩放法更好。
为了有效利用有限的文本数据集,还有人建议,不仅应在同一数据上反复训练程序代码,而且应将程序代码作为训练数据,并对数据进行排序。从这次实验的结果来看,建议只对有噪声的数据集进行数据排序,基本上,在同一数据上进行迭代学习,并将程序编码也作为训练数据,会更有效率。