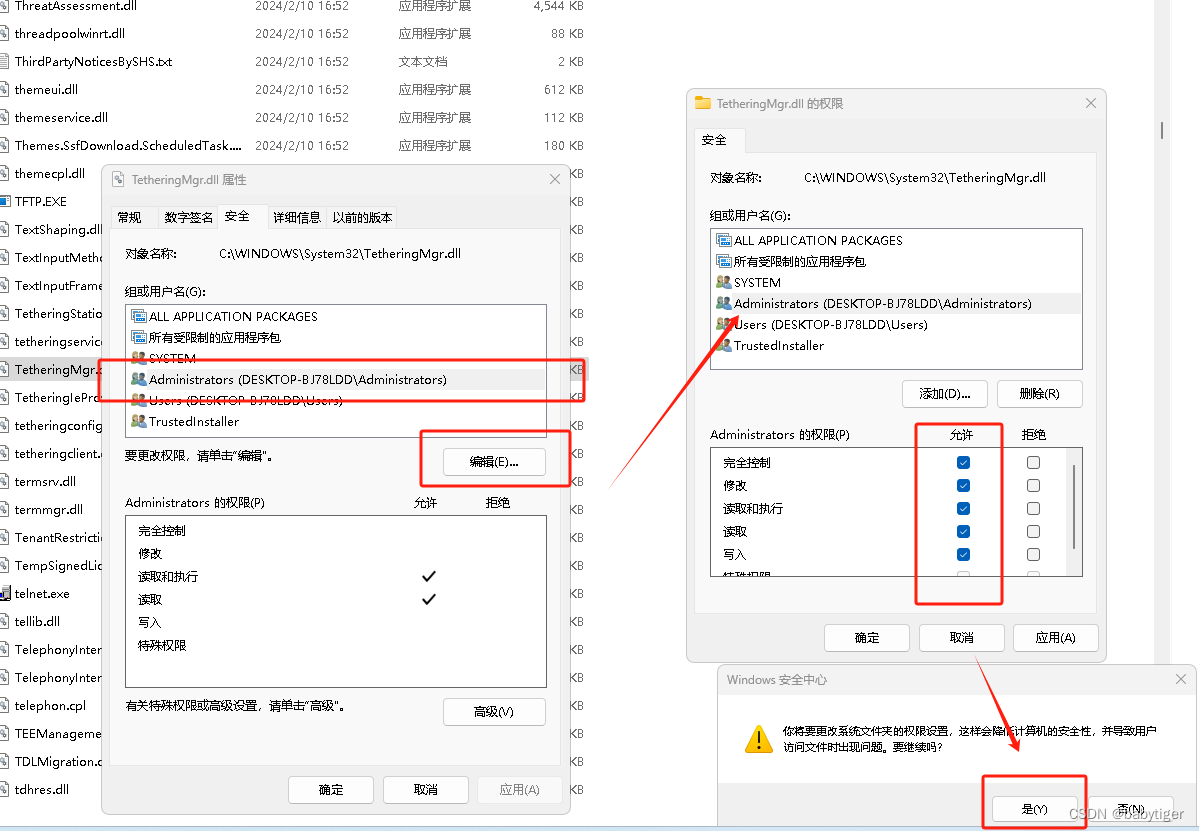
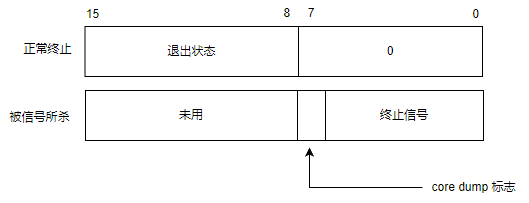
该日报由AI生成,制作方法联系 【微信:wenhaofree】
⏩昆仑万维23年收入49亿净利润13亿,研发费用增长40%,坚定All in AGI与AIGC
昆仑万维发布2023年年度业绩报告,实现营业收入49.2亿元,净利润12.6亿元,同比增长9.15%。公司坚定践行“All in AGI与AIGC”发展战略,加大研发投入,研发费用同比增长40.2%。公司构建了多元AI业务矩阵,位列国内人工智能企业第一梯队。公司发布了“天工”大模型的多个版本,包括双千亿模型架构“天工1.0”和4,000亿参数MOE架构“天工3.0”。公司在人工智能应用层取得多项进展,包括AI搜索、AI音乐、AI游戏等领域。此外,公司与阿里云、华为云达成战略合作,通过控股AI算力芯片企业完成了全产业链布局。公司旗下海外信息分发与元宇宙平台Opera保持增长,实现营业收入3.97亿美元,同比增长20%。公司以实现通用人工智能为使命,致力于成为用户首选的人工智能内容创作平台。

⏩Llama3后,Meta又开放自家头显操作系统,打造元宇宙时代新安卓
Meta开放自家头显操作系统Meta Horizon OS,向第三方硬件制造商开放,展示对元宇宙开放的新愿景。Meta Horizon OS是Meta十年来努力打造下一代计算平台的显著成果,结合了MR体验的核心技术和社交存在的功能。华硕、联想和微软等已经在开发基于Meta Horizon OS的新设备。Meta还在开发一个新的空间应用程序框架,帮助移动开发人员创建应用程序。

⏩这就是OpenAI神秘的Q*?斯坦福:语言模型就是Q函数
这篇文章介绍了斯坦福大学团队的一项新研究,他们声称语言模型不是一个奖励函数,而是一个Q函数。他们通过使用二元偏好反馈的常见形式推导了DPO,并证明DPO可以将语言模型与隐式的人类奖励对齐。他们的研究表明DPO训练可以隐含地学习到一个token层面的奖励函数,并且可以拟合任何在轨迹上的反馈奖励。实验结果显示DPO模型可以执行credit assignment,并具备组合泛化的能力。此外,研究还发现对DPO模型进行似然搜索类似于在解码期间搜索奖励函数,而初始策略和参考分布的选择对于确定训练期间隐性奖励的轨迹非常重要。


![BUUCTF---misc---[ACTF新生赛2020]outguess](https://img-blog.csdnimg.cn/direct/8599a9d4d90a426bbe2a49607fda6d4c.png)