广州大学学生实验报告
开课学院及实验室:
| 学院 | 年级、专业、班 | 姓名 | 学号 | |||||
| 实验课程名称 | 计算机网络实验 | 成绩 | ||||||
| 实验项目名称 | 网络程序设计 | 指导老师 | ||||||
(1)实验目的
通过程序模拟网桥的工作原理以及检验和的计算,或者编写数据包的监听与分析程序,使学生加深对网络知识的理解。
(2)实验环境
操作系统windows xp、以太网;
(3)实验内容
- 写一个程序来模拟网桥功能。
模拟实现网桥的转发功能,以从文件中读取帧模拟网桥从网络中收到一帧,即从两个文件中读入一系列帧,从第一个文件中读入一帧然后从第二个文件中再读入一帧,如此下去。对每一帧,显示网桥是否会转发,及显示转发表内容。
要求:Windows或Linux环境下运行,程序应在单机上运行。
分析:用程序模拟网桥功能,可以假定用两个文件分别代表两个网段上的网络帧数据。而两个文件中的数据应具有帧的特征,即有目的地址,源地址和帧内数据。程序交替读入帧的数据,就相当于网桥从网段中得到帧数据。
对于网桥来说,能否转发帧在于把接收到的帧与网桥中的转发表相比较。判断目的地址后才决定是否转发。由此可见转发的关键在于构造转发表。这里转发表可通过动态生成。
实现步骤:
- 先通过代码编写,随机生成两个文件,文件中包含随机生成的帧,其包括帧的目的地址、源地址、帧内数据;
- 通过代码编写,写出模拟网桥功能的程序。
模拟网桥需要具备的功能:
1、网桥转发表是动态的,初始时为空表;
2、通过读取待转发的帧中的源地址,判断转发表中是否已存在该地址,若不存在,则记录该地址及其对应的端口;
3、判断待转发的帧中的目的地址是否存在于转发表中,若不存在,则通过广播进行转发,转发后结束帧转发工作;
4、判断源地址和目的地址是否处于同一网段,若存在,则丢弃该帧,不进行转发操作;否则,在该表中查找该目的地址的端口并进行帧的转发。
程序流程图:

模拟的网络拓扑图:

程序部分运行结果:


| 程序代码1:该段代码用于生成需要用到的相关数据,即两个存储帧的文件。 |
| import random import pandas # 地址 addrlist = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N'] # 生成的第一个帧数据文件 frame_data1 = [] n = random.randint(10, 15) # 帧文件的数据行数为:5~10之间的随机数 for i in range(n): addr = random.sample(addrlist, 2) # 随机取两个样本,分别作为目的地址target和源地址source addr.append(random.randint(1, 200)) # 插入一个1~200的随机数作为帧内数据 frame_data1.append(addr) # 将数据插入到frame_data1中 frame_data1 = pandas.DataFrame(frame_data1, columns=['target', 'source', 'data']) # 创建一个表格数据结构,存储数据 frame_data1.to_csv('frame_data1.csv', index=False) # 将表格的数据结构做成一个表格文件 print(frame_data1) # 打印表格文件 # 生成第二个帧数据文件 frame_data2 = [] n = random.randint(10, 15) for i in range(n): addr = random.sample(addrlist, 2) addr.append(random.randint(1, 200)) frame_data2.append(addr) frame_data2 = pandas.DataFrame(frame_data2, columns=['target', 'source', 'data']) frame_data2.to_csv('frame_data2.csv', index=False) print(frame_data2) # 读取文件 file1 = pandas.read_csv('frame_data1.csv') file2 = pandas.read_csv('frame_data2.csv') |
| 程序代码2:该段代码实现了模拟网桥的功能。 |
| import pandas import numpy # 网桥自学习 更新转发表的信息(添加转发表中没有的信息) def updateForwardingTable(key, ForwardingTable=None): ForwardingTable.loc[ForwardingTable.shape[0]] = [key, port_dict[key]] # 开辟转发表中的新的一行,然后存储新的地址和其对应的端口号 print('更新后的转发表为') print(ForwardingTable) # 通过广播进行查找发送 def broadcastSearch(line): for key in port_dict: # 遍历所有的地址 if key == line[0]: # 地址匹配时 print('广播发送成功\n') return print('没有找到目标地址,发送失败\n') # 模拟网桥转发功能 def simulate_Bridge(line, ForwardingTable=None): # line为帧中的数据,第一、二、三个数据分别为目的地址、源地址、数据 print(f'网络接口{port_dict[line[1]]}收到数据帧') print(f'PC-{line[1]}向PC-{line[0]}发送数据{line[2]}') # 如果 源地址 不在转发表中, 则网桥需要将源地址记录在转发表中 if line[1] not in numpy.array(ForwardingTable.address): print(f'转发表登记PC-{line[1]}源地址') updateForwardingTable(line[1], forwardingTable) # 如果 目的地址 不在转发表中, 则通过广播进行发送 if line[0] not in numpy.array(ForwardingTable.address): print(f'PC-{line[0]}目的地址不在转发表中,通过广播进行发送') broadcastSearch(line) return # (源地址和目的地址均在转发表中时) 判断 源地址 和 目的地址 是否在同一个网段,即它们的端口号是否相等 if numpy.array(ForwardingTable[ForwardingTable['address'] == line[1]]['port']) == numpy.array( ForwardingTable[ForwardingTable['address'] == line[0]]['port']): print('源地址和目的地址在同一个网络接口,丢弃该帧\n') else: num = numpy.array(ForwardingTable[ForwardingTable['address'] == line[0]]['port']) print(f'通过网络接口{num[0]}进行转发\n') # 端口与地址的字典 port_dict = {'A': 1, 'B': 2, 'C': 2, 'D': 3, 'E': 2, 'F': 1, 'G': 1, 'H': 3, 'I': 2, 'J':2, 'K':2, 'L':3, 'M':1, 'N':1} # 网桥生成的转发表 forwardingTable = pandas.DataFrame(columns=['address', 'port']) # 读取初始化数据:帧文件的数据 frame_data1 = pandas.read_csv('frame_data1.csv') frame_data2 = pandas.read_csv('frame_data2.csv') print('第一个帧文件的数据为:') print(frame_data1) print('\n第二个帧文件的数据为:') print(frame_data2) # 从两个帧文件中交替读入帧数据 index1 = 0 index2 = 0 for i in range(max(len(frame_data1), len(frame_data2))): if index1 < len(frame_data1): # 获取文件1的一行数据,并转为列表:[targetAddr, sourceAddr, data] line1 = list(frame_data1.iloc[index1]) # 获取文件frame_data1中的第index1+1行数据 print(f'网桥从网段中得到帧数据为{line1}') simulate_Bridge(line1, forwardingTable) index1 += 1 if index2 < len(frame_data2): # 获取文件2的一行数据,并转为列表:[targetAddr, sourceAddr, data] line2 = list(frame_data2.iloc[index2]) print(f'网桥从网段中得到帧数据为{line2}') simulate_Bridge(line2, forwardingTable) index2 += 1 # 读完所有的帧后,打印当前的转发表 print(f'所有文件中的帧数据处理完成后,此时的转发表内容为\n{forwardingTable}') |
实验感想:
1、由于我平时比较少使用Python进行编程,用得比较多的是c语言和matlab。但是由于该实验需要进行文件的读写,C语言和MATLAB语言对于文件的读写都不是很方便;而且实验中预期还需要用到使用地址来匹配端口,要是使用C语言或者是MATLAB语言,需要用遍历才能完成匹配地址与端口进行匹配的操作,而Python中自带的字典恰恰非常适用且方便。
2、通过本次实验,我更加理解了一个知识点“网桥做简单的局域网连接,而路由器用于连接不同网络之间的数据传输”。
3、通过本实验的操作与编程,我对交换机自学习和转发帧的步骤更加熟悉,并能够用简化的步骤进行编程实现。
- 编写一个计算机程序用来计算一个文件的16位效验和。最快速的方法是用一个32位的整数来存放这个和。记住要处理进位(例如,超过16位的那些位),把它们加到效验和中。
要求:1)以命令行形式运行:check_sum infile
其中check_sum为程序名,infile为输入数据文件名。
2)输出:数据文件的效验和
附:效验和(checksum)
参见RFC1071 - Computing the Internet checksum
- 原理:把要发送的数据看成16比特的二进制整数序列,并计算他们的和。若数据字节长度为奇数,则在数据尾部补一个字节的0以凑成偶数。
- 例子:16位效验和计算,下图表明一个小的字符串的16位效验和的计算。
为了计算效验和,发送计算机把每对字符当成16位整数处理并计算效验和。如果效验和大于16位,那么把进位一起加到最后的效验和中。

计算机计算结果:
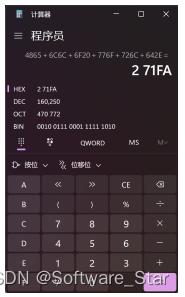
由此可知,若是直接将每个字符对应的十六进制数进行简单相加而不处理进位操作时,结果与正确的校验和结果不同。因此,需要需要将超过16位的那些数值加到低16位中去。
实现步骤:
1、先在设定好的路径下创建一个infile.txt的文件,文件中包含一个语句:Hello world.
2、编写check_sum程序,程序流程图如下所示:
程序流程图:

程序运行结果:

实验感想:
- 在pycharm终端中,需要注意路径是否正确。例如,我将该实验的程序文件check_sum和需要用到的文本文件infile都放置于目录 C:\Python_works\Python_learn\计算机网络 中。但是在pycharm终端中,默认的路径为 C:\Python_works 。所以,我在pycharm终端中输入指令:python check_sum.py后,一直提示未找到该文件名的文件。其实文件一直存在,只不过是路径没有匹配上。报错如下图所示:
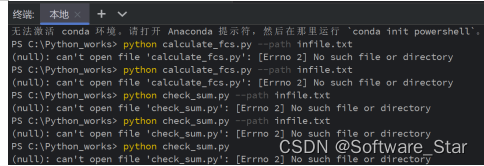
解决办法,将文件 check_sum.py和infile.txt从目录 C:\Python_works\Python_learn\ 转移至目录C:\Python_works。
- 实验过程中,我容易忘记自己定义的变量的数据类型,例如,我存储的十六进制数值列表就是使用str的。所以在进行一些操作时,使用+号表示的是两字符串的连接而非其十六进制数值形式的加法运算,这是容易出错的。
- 程序在处理进位的操作,我使用的方法是简单地将溢出的数值与十六进制最低位的数值进行相加,然后将相加结果转换为字符串1,然后再将十六进制非最低位的字符串1进行拼接,从而实现了处理进位,最终得到正确的校验和。
| 程序代码 |
| import argparse # 读取文件内容的函数 def readfile(path): with open(path, 'r', encoding='utf-8-sig') as f: content = f.read() f.close() return content # 通过命令行参数解析器创建一个解析器对象 parser = argparse.ArgumentParser(description='Calculate checksum for a file') # 添加一个命令行参数,表示文件路径,必须提供 parser.add_argument('--path', required=True, type=str) # 使用解析器解析命令行参数 args = parser.parse_args() # 从命令行参数中获取文件路径 file_path = args.path # 读取文件内容 file_content = readfile(path=file_path) print("文件内容为:", file_content) # 将字符串转为十六进制 注意 这里的数据类型为 字符串类型 hex_data_list = [hex(ord(char)).replace('0x', '') for char in file_content] # 对奇数长度字节的尾部补'00' if 1 == len(hex_data_list) % 2: hex_data_list.append('00') print("十六进制数据列表:", hex_data_list) # 相邻两项进行合并 num_list = ['0x' + hex_data_list[i] + hex_data_list[i + 1] for i in range(0, len(hex_data_list), 2)] print("合并后的十六进制数值列表:", num_list) # 相加 check_sum = hex(sum([int(num, 16) for num in num_list])) # 进行16进制的加法运算 check_sum = check_sum.replace('0x', '') # 去掉多的一个前缀'0x' print("未处理进位的相关问题时,结果为:", check_sum) # 打印结果为:271fa # 处理进位 if len(check_sum) > 4: check_sum_part1 = '0x' + check_sum[:len(check_sum) - 4] # 提取高位(高的第一位) print("提取高位:", check_sum_part1) check_sum_part2 = '0x' + check_sum[len(check_sum_part1) - 4:] # 提取低位(低的第一位) print("提取低位:", check_sum_part2) temp1 = hex(int(check_sum_part1, 16) + int(check_sum_part2, 16)) # 将高位和低位进行十六进制加法操作 print("高位和低位相加:", check_sum_part1, "+", check_sum_part2, "=", temp1) temp1 = temp1.replace('0x', '') index1 = len(check_sum_part1) - 2 index2 = len(check_sum) - (abs(len(check_sum_part2)) - 2) temp2 = check_sum[index1:index2] temp2 = '0x' + temp2 check_sum = temp2 + temp1 print("将高位和低位相加后的结果赋值到十六进制末尾:", check_sum) print("数据文件的校验和为:", check_sum) |