1.introduction

1.创建了一个 数据集,每个示例包括一个提示,两个生成的图像以及一个指向首选图像的标签,或者在没有一个图像明显优于另一个时标记为平局。由真实用户创建,包括50w个示例。
2.利用真实用户偏好,训练一个评分函数,使用人类偏好数据和类似于instructGPT奖励模型的目标,对clip-H进行微调。
2.Pick-a-Pic Dataset
超过50w个示例和35000个不同的提示,每个示例包含一个提示,两个生成的图像以及一个标签。数据集中的图像由多个文生图模型生成。
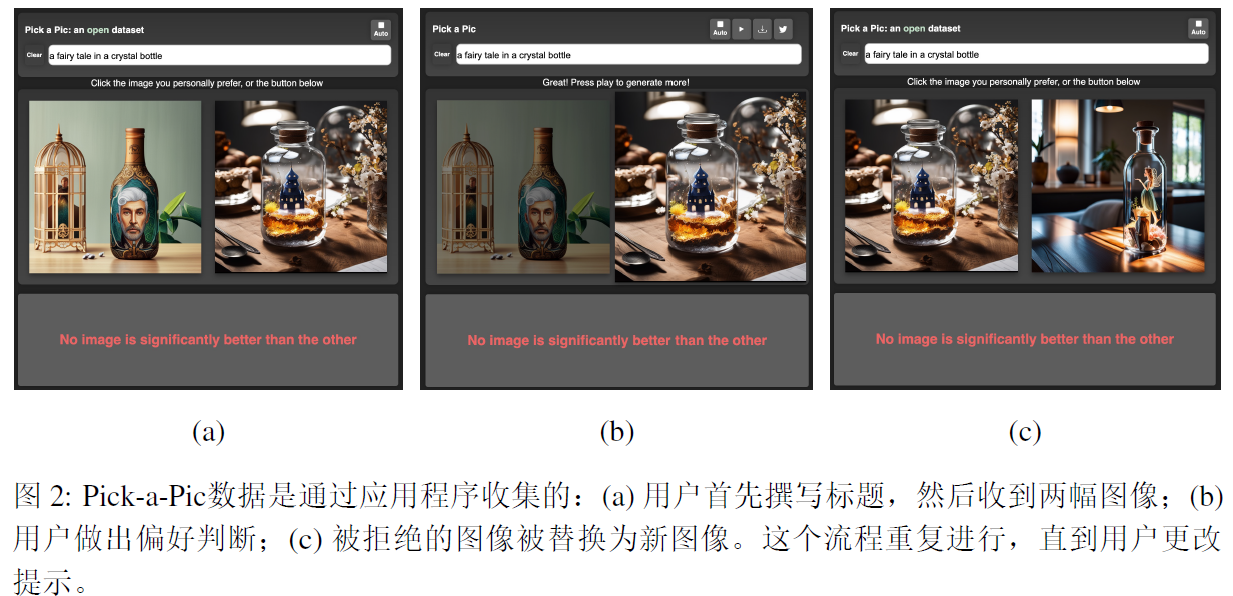
数据来源于真实用户,而非众包工作者。一共收集了968965个排名,这些排名源自66798个提示和6394个用户,Pick-a-Pic数据集包括583747个训练示例,以及500个验证和测试示例,训练集来自4375个不同用户的37523个提示。

3.Pic







![pwn--realloc [CISCN 2019东南]PWN5](https://img-blog.csdnimg.cn/direct/c63f2dba8fc7469ebc4ec33f46f57fa7.png)