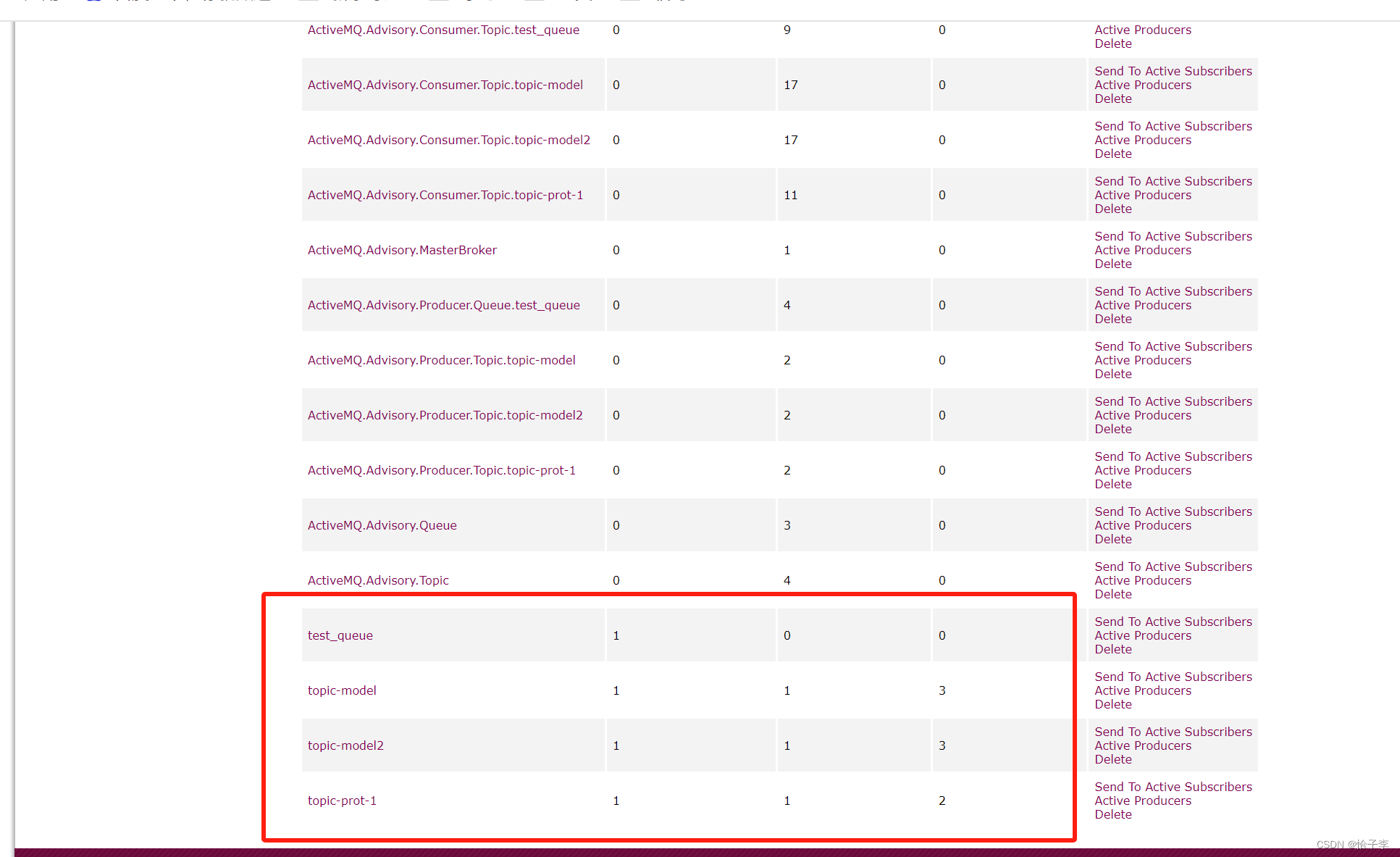
1 最终项目实现的代码
仙剑
#!/usr/bin/env python
import logging
import requests
import re
from urllib.parse import urljoin
import pymongo
import multiprocessing
mongo_client = pymongo.MongoClient("mongodb://192.168.135.131:27017/")
db = mongo_client["wy_movies"]
collection = db["movies"]
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')
BASE_URL = 'https://ssr1.scrape.center'
TOTAL_PAGE = 10
#抓取某一页面的内容
def scrape_index(page):
index_url = f'{BASE_URL}/page/{page}'
return scrape_page(index_url)
#定义一个函数抓取网页的内容
def scrape_page(url):
logging.info("正在抓取 %s.....",url)
#发起get请求
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
logging.error("抓取 %s 时返回无效的状态码 %s",url,response.status_code)
except requests.RequestException :
#如果发生异常,就报错
logging.error("抓取%s时发生异常",url,exc_info=True)
#解析内容,并提取出详情页面的url
def parse_index(html):
#用正则把连接给提取出来
# print(type(html))
pattern = re.compile('<a.*href="(.*?)".*?class="name">')
items = re.findall(pattern,html)
# print(items)
if not items:
return []
for item in items:
#把相对链接转为绝对链接
detail_url = urljoin(BASE_URL,item)
# print(detail_url)
logging.info('找到详情页面了,链接%s',detail_url)
yield detail_url
def scrape_detail(url):
return scrape_page(url)
def parse_detail(html):
cover_pattern = re.compile(
'class="el-col.*?<img.*?src="(.*?)".*?class="cover">', re.S)
# cover_pattern = re.compile(
# '<img.*?src="(.*?)".*?class="cover">', re.S)
name_pattern = re.compile('<h2.*?>(.*?)</h2>')
categories_pattern = re.compile(
'<button.*?category.*?<span>(.*?)</span>.*?</button>', re.S)
published_at_pattern = re.compile('(\d{4}-\d{2}-\d{2})\s?上映')
drama_pattern = re.compile('<div.*?drama.*?>.*?<p.*?>(.*?)</p>', re.S)
score_pattern = re.compile('<p.*?score.*?>(.*?)</p>', re.S)
cover = re.search(cover_pattern, html).group(1).strip() if re.search(cover_pattern, html) else None
name = re.search(name_pattern, html).group(1).strip() if re.search(name_pattern, html) else None
categories = re.findall(categories_pattern, html) if re.findall(categories_pattern, html) else []
published_at = re.search(published_at_pattern, html).group(1) if re.search(published_at_pattern, html) else None
drama = re.search(drama_pattern, html).group(1).strip() if re.search(drama_pattern, html) else None
score = float(re.search(score_pattern, html).group(1).strip()) if re.search(score_pattern, html) else None
# print(type(cover))
return {
'cover': cover,
'name': name,
'categories': categories,
'published_at': published_at,
'drama': drama,
'score': score
}
def save_data(data):
collection.insert_one(data)
logging.info("数据保存到mongodb成功!!!!")
def main(page):
# for page in range(1,TOTAL_PAGE+1):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
for detail_url in detail_urls:
detail_html = scrape_detail(detail_url)
data = parse_detail(detail_html)
logging.info('get detail data %s', data)
save_data(data=data)
logging.info('data saved successfully')
def run_main(page):
main(page)
if __name__ == '__main__':
#获取CPU的核心数量
num_process = multiprocessing.cpu_count()
#创建进程池
pool = multiprocessing.Pool(num_process)
#要抓取的页面数量
page_to_scrape = list(range(1,TOTAL_PAGE+1))
#使用进程池运行
pool.map(run_main,page_to_scrape)
#关闭进程池
pool.close()
结果

2 xpath
2.1 xpath介绍
XPath是一种在XML或HTML文档中查找信息的强大语言,通过简洁的路径表达式和丰富的内置函数,能够精确定位并提取文档中的特定节点或内容。而HTML解析器的原理则在于将HTML文档转化为易于程序操作的DOM树形结构,通过词法分析和语法分析将文档分解为标记并组合成节点,最终构建出完整的DOM树,从而实现对HTML内容的解析和提取。在Python中,我们常结合如BeautifulSoup和lxml等库来使用XPath,这些库不仅内置了对XPath的支持,还提供了高效的解析和查询机制,使得处理HTML文档变得简单而高效。
2.2 xpath案例
案例1
#! /usr/bin/env python
# 导入html模块,用于处理HTML实体编码
import html
# 导入lxml库的etree模块,用于解析HTML和XML
from lxml import etree
# 定义一段HTML文本
text = """
<div>
<ul>
<li class="item-0"><a href="link1.html">1-item</a></li>
<li class="item-1"><a href="link2.html">2-item</a></li>
<li class="item-0"><a href="link3.html">3-item</a></li>
<li class="item-1"><a href="link4.html">4-item</a></li>
<li class="item-1"><a href="link5.html">5-item</a></li>
<li class="item-0"><a href="link6.html">6-item</a></li>
</ul>
</div>
"""
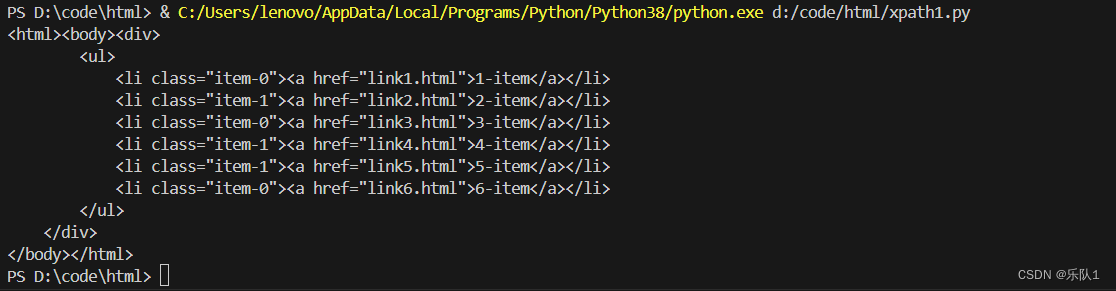
# 1. 使用etree.HTML方法将HTML文本解析成一个Element对象
# 这个Element对象代表整个HTML文档结构,可以进一步查询和操作
html = etree.HTML(text)
# 2. 使用etree.tostring()方法将Element对象再次转换为HTML文本
# 这个方法返回的是字节串,所以需要使用decode('utf-8')来解码为字符串
result = etree.tostring(html)
# 打印转换后的HTML文本
print(result.decode('utf-8'))
# 打开一个名为'a.html'的文件,以写入模式打开
with open('a.html', 'w') as file:
file.write(text)
结果
案例2
#!/usr/bin/env python
# 导入html模块,用于处理HTML实体编码,但在这个示例中并未实际使用
import html
# 导入lxml库的etree模块,用于解析HTML和XML
from lxml import etree
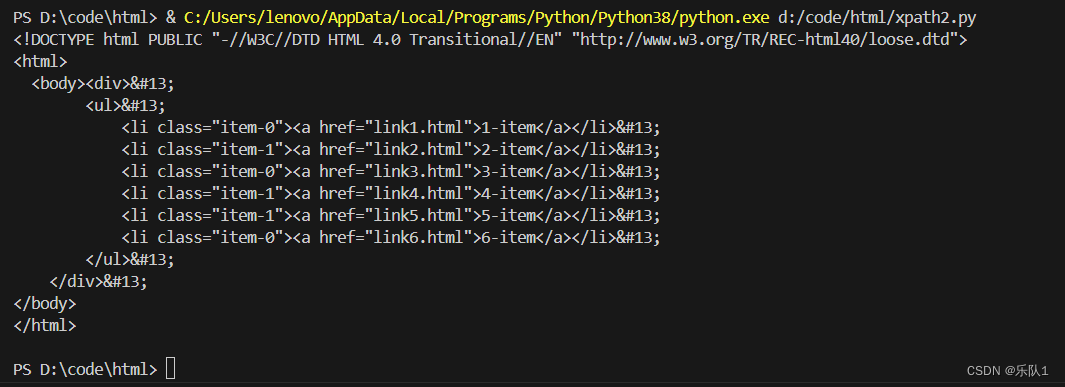
# 使用etree.parse方法和etree.HTMLParser()解析器来解析名为'a.html'的文件
# etree.parse方法返回一个ElementTree对象,它代表整个HTML文档的结构
html = etree.parse('a.html', etree.HTMLParser())
# 使用etree.tostring方法将ElementTree对象转换为字节串形式的HTML文本
# 这个方法返回的是字节串,所以需要使用decode('utf-8')来解码为字符串
result = etree.tostring(html, pretty_print=True) # 添加pretty_print=True可以美化输出格式
# 打印转换后的HTML文本
print(result.decode('utf-8'))
结果
案例3
#!/usr/bin/env python
# 导入lxml库,虽然这里直接导入了lxml,但实际上只需要使用etree模块
import lxml
# 从lxml库中导入etree模块,用于解析HTML和XML
from lxml import etree
# 创建一个自定义的HTML解析器
# remove_comments=True: 解析时移除HTML中的注释
# recover=True: 尝试修复不规范的HTML代码
# remove_blank_text=True: 移除空白文本节点
parser = etree.HTMLParser(remove_comments=True, recover=True, remove_blank_text=True)
# 使用etree.parse方法和自定义的解析器来解析名为'a.html'的文件
# 解析后返回一个ElementTree对象,它代表整个HTML文档的结构
html = etree.parse('a.html', parser)
# 使用etree.tostring方法将ElementTree对象转换为字节串形式的HTML文本
# 注意:这里应该添加pretty_print=True以美化输出格式
result = etree.tostring(html, pretty_print=True)
# 打印转换后的HTML文本
# 使用decode('utf-8')将字节串解码为字符串
print(result.decode('utf-8'))
案例4 使用xpath进行查询
#!/usr/bin/env python
# 导入html模块,虽然在这个脚本中并未使用到,可能是为了演示或其他部分使用的。
import html
# 导入lxml库中的etree模块,用于解析HTML或XML文档。
from lxml import etree
# 使用etree.parse函数和etree.HTMLParser()来解析名为'a.html'的文件。
# 这里'a.html'应该是一个包含HTML内容的文件。
html = etree.parse('a.html', etree.HTMLParser())
# 使用XPath查询语言,'//*'是一个XPath表达式,表示选取文档中所有的节点。
# 无论节点的类型(比如元素、属性、文本等)或名称是什么,都会被选取。
result = html.xpath('//*')
# 打印查询结果,result将是一个列表,包含文档中所有的节点。
print(result)
结果

案例5
#!/usr/bin/env python
import html
from lxml import etree
html = etree.parse('a.html',etree.HTMLParser())
result = html.xpath('//li')
print(result)
案例6
#!/usr/bin/env python
import html
from lxml import etree
html = etree.parse('a.html',etree.HTMLParser())
#使用xpath语法选取所有位于li标签内的a标签
result = html.xpath('//li//a')
print(result)
案例7
#!/usr/bin/env python
import html
from lxml import etree
html = etree.parse('a.html',etree.HTMLParser())
# 使用XPath查询语言查询文档中所有class属性值为'item-0'的li元素。
result = html.xpath("//li[@class='item-0']")
print(result)
案例8
#!/usr/bin/env python
import html
from lxml import etree
html = etree.parse('a.html',etree.HTMLParser())
# XPath表达式'//a[@href="link6.html"]/parent::*/@class'的作用是:
# 1. '//a[@href="link6.html"]':查找所有href属性值为"link6.html"的<a>标签。
# 2. '/parent::*':选取这些<a>标签的父元素,'*'表示任意类型的父元素。
# 3. '/@class':从选取的父元素中获取class属性的值。
result = html.xpath('//a[@href="link6.html"]/parent::*/@class')
print(result)
案例9
#!/usr/bin/env python
import html
from lxml import etree
html = etree.parse('a.html',etree.HTMLParser())
# XPath表达式"//li[@class='item-1']/a/text()"的作用是:
# 1. "//li[@class='item-1']":查找所有class属性值为'item-1'的<li>标签。
# 2. "/a":从这些<li>标签中选择直接子元素<a>。
# 3. "/text()":从这些<a>标签中提取文本内容。
result = html.xpath("//li[@class='item-1']/a/text()")
print(result)
案例10
#!/usr/bin/env python
import html
from lxml import etree
html = etree.parse('a.html',etree.HTMLParser())
result = html.xpath('//li/a/@href')
print(result)
案例11
#!/usr/bin/env python
import html
from lxml import etree
text = '''
<li class="li item-0"><a href="link1.html">1-item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class,li)]/a/text()')
print(result)
案例12
#!/usr/bin/env python
# 导入html模块,虽然在这个脚本中并未使用到,但通常用于处理HTML字符串
import html
# 导入lxml库中的etree模块,用于解析HTML字符串
from lxml import etree
# 定义一个包含HTML内容的字符串
text = '''
<li class="li item-0" name="wuyue"><a href="link1.html">1-item</a></li>
<li class="li item-0"><a href="link1.html">2-item</a></li>
'''
# 使用etree.HTML()函数将字符串解析为HTML对象
html = etree.HTML(text)
# 使用XPath查询语言来查找匹配的元素
# XPath表达式'//li[contains(@class,li) and @name="wuyue"]/a/text()'的意思是:
# 1. //li:选择所有<li>标签
# 2. [contains(@class,li) and @name="wuyue"]:条件筛选,只选取class属性中包含"li"且name属性值为"wuyue"的<li>标签
# 3. /a:选择这些<li>标签下的直接子元素<a>
# 4. /text():提取这些<a>标签内的文本内容
result = html.xpath('//li[contains(@class, "li") and @name="wuyue"]/a/text()')
# 打印查询结果,result是一个包含匹配到的<a>标签内文本内容的列表
print(result)
案例13
#!/usr/bin/env python
import html
from lxml import etree
html = etree.parse('a.html',etree.HTMLParser())
#只要第一个li节点里面的a元素的文本
result = html.xpath('//li[1]/a/text()')
# print(result)
#只要第最后一个li节点里面的a元素的文本
result = html.xpath('//li[last()]/a/text()')
# print(result)
#查询前两元素下的a标签的文本内容
result = html.xpath('//li[position()<3]/a/text()')
# print(result)
#查询倒数第三个呢
result = html.xpath('//li[last()-2]/a/text()')
print(result)
2.3 xpath综合性练习小项目
#!/usr/bin/env python # 导入html模块,但在这个脚本中实际上并未使用到html模块的功能 import html # 从lxml库中导入etree模块,用于解析HTML字符串 from lxml import etree # 定义一个包含HTML内容的字符串 html = ''' <html> <body> <div class="item" id="item1">item 1</div> <div class="item" id="item2">item 2</div> <div class="item" id="item3">item 3</div> <div class="price">price:$50</div> </body> </html> ''' # 使用etree.HTML()函数将字符串解析为HTML对象 tree = etree.HTML(html) # 此处注释了几个XPath查询示例,它们演示了如何使用XPath查询不同的内容 # 查询价格大于40的div内容(此查询无法正常工作,因为XPath无法直接对文本进行数值比较) # xpth_exp = '//div[contains(text(),"$") and number(substring-after(text(),"$")) > 40]/text()' # result = tree.xpath(xpth_exp) # print(result) # 查询第二个div元素的内容 # xpth_exp = '//div[position()=2]/text()' # result = tree.xpath(xpth_exp) # print(result) # 查询第一个div元素的内容和最后一个div的内容 # 使用'|'操作符可以同时查询多个XPath表达式,并将结果合并 xpth_exp = '//div[position()=1]/text() | //div[position()=last()]/text()' # 执行XPath查询 result = tree.xpath(xpth_exp) # 打印查询结果,result是一个包含匹配到的div元素内文本内容的列表 print(result)
3 xpath项目:
3.1 需求:
1.抓图片and名称 2.抓到图片and名称后 3.保存到本地 4.从本地发送到远程文件服务器 (是一个中项目)
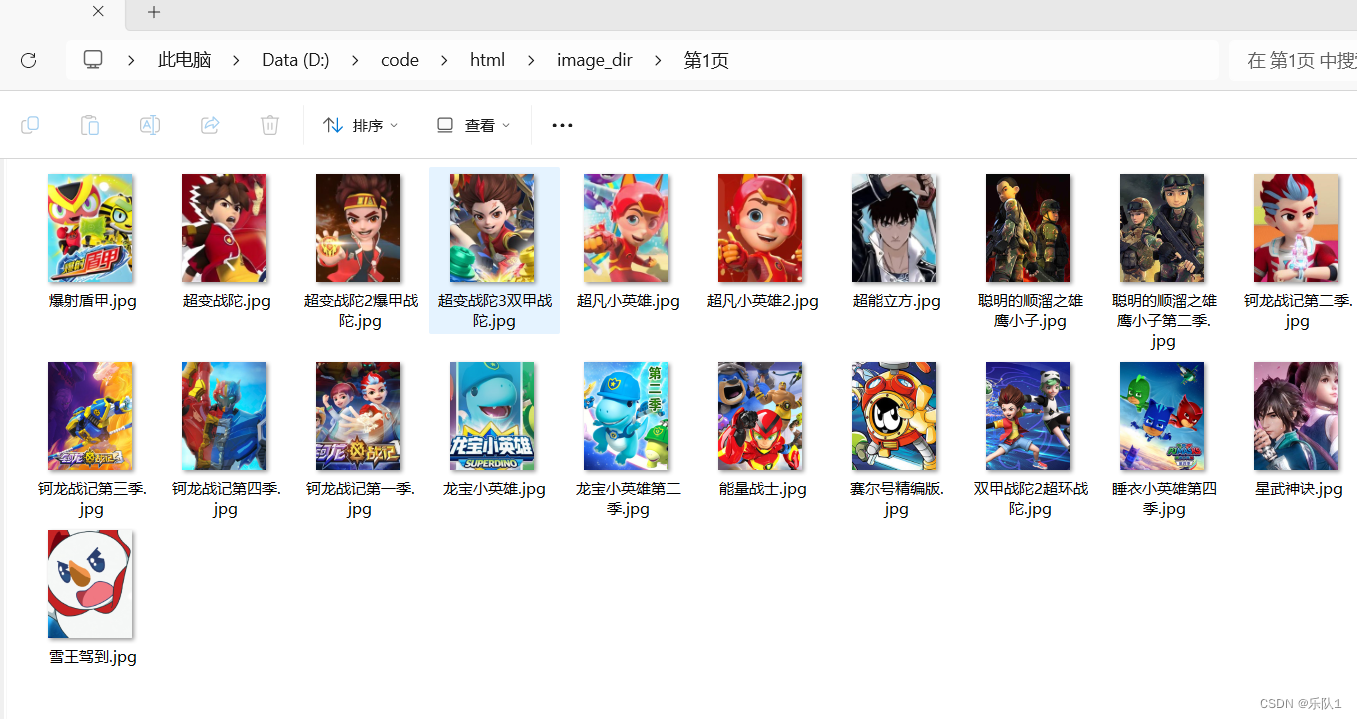
3.2 xpath项目1
对图片进行抓取
#!/usr/bin/env python
import requests
from lxml import etree
import logging
import random
from fake_useragent import UserAgent
import os
ua = UserAgent()
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s : %(message)s')
url = 'https://www.4399dmw.com/search/dh-1-0-0-0-0-0-0/'
filepath = "D:\\code\\html\\http_proxies.txt"
def read_proxy_file(filepath):
proxy_list = []
try:
with open(filepath,'r') as file:
for line in file:
if line:
proxy_list.append(line.strip())
except FileExistsError:
logging.error("文件未找到")
except Exception as e:
logging.error(f"发生错误:{e}")
return proxy_list
def get_proxy():
proxy = random.choice(read_proxy_file(filepath))
return {"http":proxy}
#下载图片并保存到本地
def save_image(img_url,img_name):
headers = {
"User-Agent":ua.random,
"Cookie":"UM_distinctid=18a97aab8cf882-083b9875fb34fe-7f5d5476-1bcab9-18a97aab8d0d81; Hm_lvt_6bed68d13e86775334dd3a113f40a535=1695364979,1695696815,1695798201,1695816352; a_180_90_index=2; CNZZDATA3217746=cnzz_eid%3D924600740-1694761663-%26ntime%3D1695816461; Hm_lpvt_6bed68d13e86775334dd3a113f40a535=1695816461; a_200_90_index=4; a_980_90_index=1",
"Referer":"https://www.4399dmw.com/donghua/"
}
try:
img = requests.get(url=img_url,headers=headers)
iamge_name = img_name + ".jpg"
with open(iamge_name,'ab') as f:
f.write(img.content)
except Exception as e:
logging.error(e)
def mk_dir(path):
#判断这个目录是否存在
#os.path.exists判断是否存在路径
#os.path.join连接路径和文件名
is_exist = os.path.exists(os.path.join('D:\\code\\html\image_dir',path))
if not is_exist:
#创建文件夹
os.mkdir(os.path.join('D:\\code\\html\\image_dir',path))
os.chdir(os.path.join('D:\\code\\html\\image_dir',path))
return True
else:
os.chdir(os.path.join('D:\\code\\html\\image_dir',path))
return True
def next_page(html):
next_url = html.xpath('//a[@class="next"]/@href')
#拼接
if next_url:
next_url = "https://www.4399dmw.com/" + next_url[0]
return next_url
else:
return False
def spider_4399dmw(url):
# 图片的xpath
# result = html.xpath('//div[@class="lst"]/a[@class="u-card"]/img/@data-src')
#title的xpath
#html.xpath('//div[@class="lst"]/a[@class="u-card"]/div[@class="u-ct"]/p[@class="u-tt"]/text()')
headers = {
"User-Agent":ua.random,
"Cookie":"UM_distinctid=18a97aab8cf882-083b9875fb34fe-7f5d5476-1bcab9-18a97aab8d0d81; Hm_lvt_6bed68d13e86775334dd3a113f40a535=1695364979,1695696815,1695798201,1695816352; a_180_90_index=2; CNZZDATA3217746=cnzz_eid%3D924600740-1694761663-%26ntime%3D1695816461; Hm_lpvt_6bed68d13e86775334dd3a113f40a535=1695816461; a_200_90_index=4; a_980_90_index=1",
"Referer":"https://www.4399dmw.com/donghua/"
}
logging.info("开始爬取: "+url)
resp=requests.get(url=url,headers=headers,proxies=get_proxy())
html_text = resp.content.decode('utf-8')
html = etree.HTML(html_text)
page = html.xpath('//span[@class="cur"]/text()')
mk_dir("第"+page[0]+"页")
#title的xpath
title = html.xpath('//div[@class="lst"]/a[@class="u-card"]/div[@class="u-ct"]/p[@class="u-tt"]/text()')
#image的xpath
image_src = html.xpath('//div[@class="lst"]/a[@class="u-card"]/img/@data-src')
#讲链接前面拼上http
image_url = []
for i in image_src:
image_url.append("http:"+i)
#保存图片
#1.请求图片的url
#2.将请求的内容保存成图片
for nurl,ntitle in zip(image_url,title):
save_image(nurl,ntitle)
if next_page(html=html):
spider_4399dmw(next_page(html))
else:
logging.warning("已完成,无法找到下一页")
spider_4399dmw(url)
# read_proxy_file(filepath)
# logging.warning(get_proxy())
3.3.xpath项目2
对图片进行抓取下载到本地以及服务器上
import os
import paramiko
# 远程服务器的连接信息
hostname = '192.168.135.131' # 远程服务器的IP地址或主机名
port = 22 # SSH连接的端口号,默认为22
username = 'root' # SSH连接的用户名
password = '123456' # SSH连接的密码(或者可以使用密钥认证)
# 本地图片文件夹路径
local_image_folder = 'D:\\code\\html\\image_dir' # 本地图片文件夹的路径
# 远程服务器上的目标路径,可以根据需要进行更改
remote_target_path = '/root/spider_img/' # 远程服务器上存储图片的目标路径
def upload_images_recursively(local_folder, remote_folder, ssh_client):
# 打开SFTP连接
with ssh_client.open_sftp() as sftp:
# 递归遍历本地文件夹及其子文件夹
for root, _, files in os.walk(local_folder):
for filename in files:
# 检查文件是否以指定图片文件扩展名之一结尾
if filename.endswith(('.jpg', '.jpeg', '.png', '.gif', '.bmp')):
local_filepath = os.path.join(root, filename) # 获取本地文件的完整路径
# 构建远程服务器上的文件路径,使用相对路径并连接到远程基础路径
relative_path = os.path.relpath(local_filepath, local_folder)
remote_filepath = os.path.join(remote_folder, relative_path)
# 输出上传信息,包括本地文件路径和远程文件路径
print(f'Uploaded: {local_filepath} to {hostname}:{remote_filepath}')
# 创建远程文件夹以确保上传路径存在
remote_folder = os.path.dirname(remote_filepath)
sftp.mkdir(remote_folder)
# 上传文件到远程服务器
sftp.put(local_filepath, remote_filepath)
try:
# 建立SSH连接
ssh_client = paramiko.SSHClient()
ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 设置自动添加远程主机密钥策略
ssh_client.connect(hostname, port, username, password) # 连接到远程服务器
# 调用递归函数上传所有图片文件
upload_images_recursively(local_image_folder, remote_target_path, ssh_client)
print(f'All images successfully uploaded to {hostname}:{remote_target_path}')
except Exception as e:
print(f'Error: {e}') # 捕获并打印任何异常信息
finally:
ssh_client.close() # 最终关闭SSH连接
结果