直接用表征还是润色改写?LLM用于文生图prompt语义增强的两种范式
导语
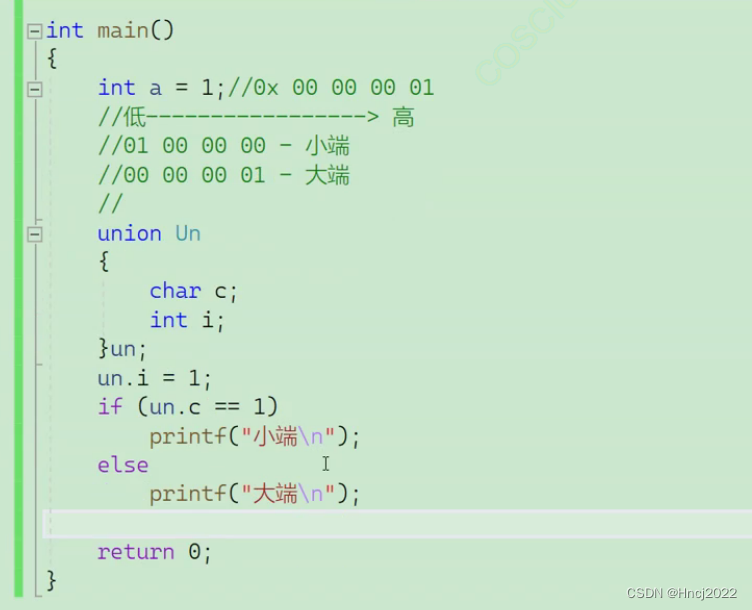
目前的文生图模型大多数都是使用 CLIP text encoder 作为 prompt 文本编码器。众所周知,由于训练数据是从网络上爬取的简单图文对,CLIP 只能理解简单语义,而无法理解复杂语法 。这导致生成的图片经常出现语义错误、属性绑定错误等问题。为了适配 CLIP 的简单语义的模式,现有的 Stable Diffusion 等生图模型的文本 prompt 也一般是宛如咒语一般的一组单词,而非正常的自然语言句子。现在的 LLM 大模型所擅长的正是复杂文本的语义理解,近来出现了一些工作使用 LLM 来对生图 prompt 进行润色改写或直接作为文生图模型的文本编码器,从而提高文生图模型对 prompt 的理解能力,并将 prompt 的语义在生图结果中更好地体现出来。
具体来说,目前使用 LLM 对文生图 prompt 进行语义增强的方法可以分为两种范式:一是使用 LLM 的文本生成能力对 prompt 进行改写、润色,使之适用于作为生图 prompt;二是直接将 LLM 的 hidden states 拿出来替换掉 CLIP 的 text embedding,作为条件通过交叉注意力注入到 UNet 生图过程中。本质上,这两类范式的区别就是语言模型与生图模型交互的交互媒介(interface)不同,关于这两类范式各自的优劣,将在文末讨论。
LaVi-Bridge
TL; DR:在 LLM 和 DM 中各自插入一些 LoRA,并在二者之间接一个 MLP。
方法
在 LLM 和 DM 中各自插入一些 LoRA,并在二者之间接一个 MLP。可以用于在各种 LLM 和 DM 之间适配。

总结
LaVi-Bridge 是比较简单直接的连接 LLM 和 DM 的做法。
ELLA
TL; DR:使用 LLM + Adapter 替换 CLIP text encoder 的简单语义 embedding,其中 LLM 和 Diffusion UNet、VAE 均冻结,仅训练 Adapter 部分。目前适用于 sd1.5 的模型已开源,但是训练代码和适用于 sdxl 的模型预计不会开源 (issue link)。
方法
- 网络结构:提出了一种不同时间步不同的网络结构 TSC (Timestep-aware Semantic Connector)。实际上是用的 Flamingo 中的 Resampler,从而支持对于任意长度的文本输入,输出固定长度的 query token。另外,考虑到在不同的时间步,模型生成的重点不同(比如在前期确定整体构图布局,后期是增加更多细节),所以本文在 Adapter 上加入了 timestep embedding,从而使得 Adapter 能感知当前所处的时间步,来输出不同的 query token。将 LLM 的最后一层 hidden states 作为 TSC Adapter 的输入,然后 TSC Adapter 的输出通过交叉注意力作为条件注入到 UNet 中。
- 训练数据:由于 web 上的图文对训练数据质量较差,本文使用 CogVLM 在筛选的图片上生成复杂文本描述。图片筛选条件包括美学分和最小分辨率等。
- 新基准:本文还提出了一个复杂 prompt 信息文生图的 benchmark:DPG-Bench。

效果展示
ELLA 展示出的效果还是非常不错的,可以看到相比于 SDXL 和 DALL-E 3,ELLA 对 prompt 的理解都更好,对于复杂的物体关系、物体属性,都在生图结果中有正确的体现。

总结
使用 LLM 代替 CLIP 提供语义更完善准确的文本 embedding,虽然需要进行训练,但是 ELLA 的方案看起来是比较简洁的。但是比较可惜 ELLA-SDXL 不开源。
RPG Master
TL; DR:本文提出 RPG 生图框架,通过利用 LLM 的 CoT 推理能力,来对复杂的生图 prompt 进行拆解,将复杂图像的生成拆分为多个子区域的生成。并集成了文本生成和图像编辑,最后通过互补区域扩散,将全局 prompt 和各个区域 prompt 结合起来,完成最终生图。
方法
现有的文生图方法在面对包含多个物体,多种属性的复杂生图 prompt 时,经常出现属性绑定错落的情况。RPG 方法的三个字母,指的分别是 Recaption、Plan 和 Generate,这是本方法的三个步骤,通过 LLM 的复杂文本理解能力,对原 prompt 进行重写和分区域规划,再用互补区域采样生成完整图片。整体流程如下图所示。

- Recaption 是根据用户的复杂 prompt(本文中也作为 base prompt),由 (M)LLM 识别出其中的实体并对每个实体重写一个 prompt。注意根据实体的属性、数目等,会有特定的切分策略,避免多种属性落到同一区域内导致混乱;
- Plan 是根据 base prompt 和各实体的 prompt,进行计划划分,将不同实体分配到图像的各个区域,并按照指定的格式输出区域切分的长宽比和
- Generate 阶段,作者使用了一种新的多区域采样方法 CRD(Complementary Regional Diffusion)(如下图所示),base prompt 和各区域 prompt 各自进行正常的生成,最后将各区域的 latent 进行缩放并按位置拼接,得到一整张图的区域 latent,再与 base prompt 的全局 latent 计算加权和,解码得到最终图像。

另外,RPG 还支持使用多模态大模型(MLLM)结合文本 prompt 和此前的生图结果进行闭环迭代式的 prompt 图像编辑(流程见下图)。MLLM 同时接收编辑修改后的 prompt 和此前的生图结果,将二者的实体进行对照,根据二者差异进行 Add / Del / Mod 三种类型的修改,重新进行 Recaption、Plan、Generate 三个步骤,实现图像编辑。

效果展示
RPG 的效果展示如下图,可以看到,在面对多个物体、多种属性的复杂 prompt (如上方例子中的冰山、火山、村庄、滑雪、游玩等)时,利用 LLM 在不同区域生成对应的 prompt 并各自采样,RPG 可以将 prompt 中描述的物体和属性的对应关系正确地体现出来,而 SDXL 和 DALL-E 3 则出现了或是出现了属性缺失,或是出现了属性错乱的现象。

总结
RPG 中核心问题的解决方式就是利用 LLM 的推理能力,来对复杂 prompt 进行重写和分区域规划。因此该方法能否 work 的关键就在于所谓的 MLLM’s powerful reasoning ability 到底有没有那么 powerful。在实测中貌似许多 (M)LLM 对指令的理解能力和 reasoning 能力并不足以稳定的进行 recaptioning 和 planning。而且这个 instruct prompt 看起来也需要非常复杂详尽,不太好写。不过 RPG 是 training-free 的,这点比较好。
SUR-Adapter
TL; DR:构建简单 prompt、复杂 prompt、高质量图片三元组数据集,训练一个新增的 Adapter,蒸馏 LLM 从简单 prompt 到复杂 prompt 的扩写能力。
方法
上面的 RPG 解决的是 prompt 过于复杂,导致生图结果中物体属性混乱的问题,这里的 SUR-Adapter 解决的则是 prompt 过于简单,生图结果中细节太少,整体质量较差的问题。RPG 将复杂 prompt 进行改写拆分,分区域单独生成,避免属性混乱,而 SUR-Adapter 则是将简单 prompt 进行语义增强扩充,使得文生图模型能够得到细节更丰富的结果。
首先,作者构建了一个 SURD (Semantic Understanding and Reasoning Dataset)数据集:在 lexica、C 站、sd web 网站上收集高质量图片及其详细、复杂 prompt 的 pair,然后用 blip 生成该图片的简单 prompt,组成简单 prompt、复杂 prompt、高质量图片的三元组数据。经过清洗,最终共收集了 57000+ 样本。

然后,作者在预训练的文生图模型中加入了一个 Adapter(具体结构如下图所示),用于学习将简单 prompt 的文本特征优化对齐到复杂 prompt 的文本特征,这中间蒸馏 LLM 的理解、推理能力,来进行学习。具体来说,Adapter 的训练需要三个训练目标来驱动。
1 蒸馏 LLM 的理解推理能力
首先是要蒸馏学习 LLM 的理解、推理能力,学会从简单 prompt 到复杂 prompt 的扩写。将简单 prompt 分别输入到 LLM 和 text-encoder + adapter 中,最小化二者得到 embedding 的 KL 散度。
2 维持生图模型的原有生图能力
为了避免微调 adapter 过程中对原生图模型的生图能力有损害,第二个训练目标是常规扩散模型的去噪训练。值得注意的是,这里的用的文本 embedding 是 LLM 和 text-encoder + adapter 二者对简单 prompt 提取的文本 embedding 的加权和。
3 对齐简单 prompt 和复杂 prompt 的表征
对齐 2 中实际输入 UNet 的加权文本 embedding 与 text encoder 对复杂 prompt 的表征结果,最小化二者的 KL 散度。

效果展示
下图左侧展示了 CLIP text encoder 在多物体计数和多物体色彩绑定情况下出的问题,右侧分别展示了文生图模型在复杂 prompt、简单 prompt 和本文方法对简单 prompt 进行增强的情况下的生图结果。可以看到,仅使用简单 prompt 时,生图的细节确实比较单薄,而使用复杂 prompt 或本文增强的 prompt,细节明显更加丰富。

总结
也属于利用 LLM hidden states 表征能力的方法,搞得比较花哨。相当于学习 LLM 对简单 prompt 的扩写、细节丰富的能力。
整体总结
直接用表征还是润色改写?这是目前 LLM 用于文生图 prompt 语义增强的两种范式。
润色改写的代表方法是 RPG。这类方法优点是利用 LLM 本身的生成能力,不需要额外训练,缺点是比较依赖 (M)LLM 强大的指令跟随和语义理解能力,并且 LLM instruct prompt 的设计需要比较复杂详尽。如果 (M)LLM 能力不够强或 LLM instruct prompt 写得不好,很难稳定地生成高质量的结果。
直接用表征的方法比较多,LLaVi-Bridge、ELLA、SUR-Adapter 都属于这类方法。这类方法将 LLM 作为一个强大的文本表征模型,直接使用 LLM 的 hidden states 替换 CLIP 的 text embedding,都需要引入额外的 adapter 并进行训练。但是不需要设计 LLM instruct prompt,训练后的出图效果一般也比较稳定。但笔者一直有一个疑惑就是 LLM 这类预测下一个 token 的自回归模型用作表征模型的效率到底如何,以及为什么 LLM 的 hidden states 就比 CLIP 的 text embedding 的语义表征能力更强?
本质上,这两类范式的区别就是语言模型与生图模型交互的交互媒介(interface)不同。前者是使用 embedding 作为交互媒介,后者则是使用自然语言。直觉上来说,以 embedding 作为交互媒介似乎是更符合深度学习时代的做法。但是,最近的也有工作(如 De-Diffusion)指出了大模型/AIGC时代自然语言作为交互媒介的优势:灵活性和可解释性。以自然语言作为 interface,我们就能无缝地对接各类 LLMs、Diffusion Models,而不需要任何额外训练。这在介绍上述各方法时也有体现,只有以自然语言为媒介的 RPG 是不需要额外微调的。另外,自然语言可以直接被人类阅读,可解释性也大大增强。也可以引入人工参与,手动修改中间的 prompt。