大家好啊,我是董董灿。
今天我们来简单聊一个在自然语言处理(NLP)中非常有用的技术——Word2Vec。
之前曾经写过一些关于文本处理的基础知识,包括判断两个文本是否相似,可以使用余弦相似度,但在此之前,在计算两个文本相似度的时候,需要把文本表示为词向量。
那么问题来了,一般情况下是如何将文本映射为词向量的呢?
今天就简单介绍一种方法,它的作用就是可以把文本映射成向量,从而使计算机具有理解人类语言的能力。
1、什么是Word2Vec?
简单来说,Word2Vec 并不是一个具体的神经网络模型,而是一个由很多生成词向量的模型(算法)组成的词向量生成框架,或者词向量生成工具。
通过它,可以将文字或者词组映射成一个多维空间中的向量。
这些向量的精妙之处在于,他们包含了单词之间的语义关系,比如两个文本如果非常相似,那么对应的两个向量的余弦相似度就非常接近于1。
比如有四个单词:“猫”、“狗”、“鱼”、“跑”,通过Word2Vec 生成的词向量可能为:
- 猫:[0.2, 0.7]
- 狗:[0.3, 0.9]
- 鱼:[-0.5, 0.2]
- 跑:[0.8, -0.1]
将上述四个向量画在坐标图上如下图。
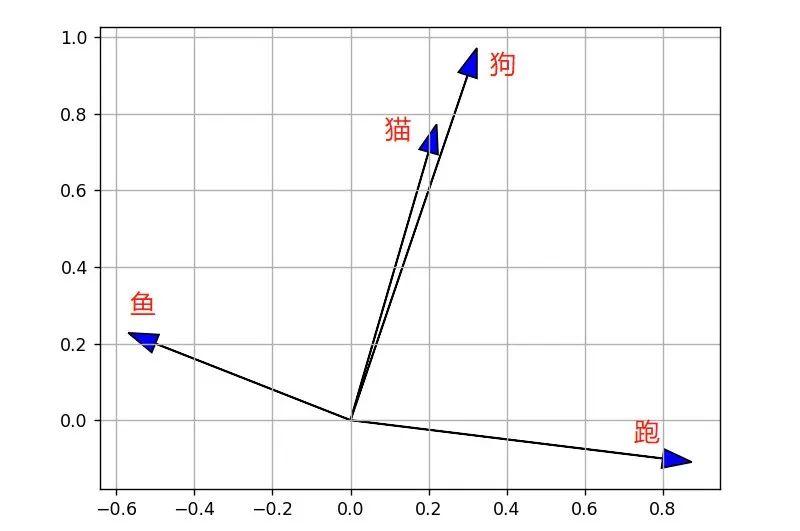
我们通过观察可以很轻松的看出来,“猫”和“狗”的两个向量很相近,“鱼”和“跑”代表的两个向量则相差很远。
这是因为猫和狗都是动物,而鱼和跑则没有什么关联性。
实际中生成的向量并非上面表示的仅仅两个维度,大部分都是512维或者1024维,这里用两维仅仅是为了展示。
可能你会问,为什么我们需要将单词转换成向量?
这是因为,在计算机看来,所有的输入和处理的文字都是数字,文本也是一样。
如果不将文本转换成计算机能理解的形式,那么计算机就像一个文盲一样处理不了它。
传统的方法如 one-hot 编码,虽然简单并且也可以将文字进行编码,但它将每个单词都孤立了,无法捕捉单词之间的关系。
例如,'王'和'后'在棋盘游戏中有紧密的联系,但在one-hot编码中,它们就是两个完全无关的向量。
关于one-hot 可以查看:5分钟搞懂 one-hot 编码。
2、Word2Vec 的工作原理
Word2Vec 通过训练语料库(可能由互联网上大量的文章组成)中的单词来生成模型,它主要有两种架构:CBOW(连续词袋模型)和 Skip-gram模型。
两者的区别在于,训练时连续词袋模型基于文本的上下文来预测单词,而Skip-gram 模型则反其道而行之,它用一个单词来预测其周围的上下文。
相同的是,这两种方法都是让模型来学习大量的文本,以及文本中单词的使用环境来生成高质量的词向量。
举个例子,如果在训练时,模型看到了句子“猫喜欢吃鱼”,在Skip-gram模型中,如果选择“喜欢”作为输入单词,模型便会试图预测它周围的“猫”和“吃鱼”。
通过这种方式,模型就学到了“喜欢”与“猫”、“吃鱼”之间在一定的语言环境下是存在关系的。
从而在生成“喜欢”这个单词的向量时,会将其与“猫”以及“吃鱼”之间的关系表示到向量中。
3、Word2Vec有什么用?
使用Word2Vec的好处非常明显。
首先,它可以捕捉到单词的多种语义关系,比如同义词、反义词,这在许多NLP任务中都非常有用,如情感分析、机器翻译和文本分类。
例如,在情感分析中,词向量可以帮助模型正确地理解某些文字是否具有正面情绪,还是具有负面情绪。
更关键的是,Word2Vec 就像是为计算机打开了一道大门,使得计算机可以真正“读懂”人类的文字(无论是汉字还是英文)。
不仅可以读懂,而且还可以“理解”文字背后的深层含义,这对于提升语言模型的理解能力来说是一个巨大的进步。
因此,可以认为,经过 Word2Vec 之后生成的词向量,是计算机的语言。
就像是如果希望从中文翻译成英文的话,我们可以先从中文翻译成俄语, 再从俄语翻译成英文。
一样的意思,可以先讲中文翻译成词向量,在将词向量翻译为英文,这就完成了中译英的任务。
好了,今天关于Word2Vec的介绍就到这里。
欢迎关注我的公众号:董董灿是个攻城狮,第一时间获取最新的文章资讯。