前言
昨天技术面的时候,面试官说人家公司现在用的都是最新的技术,比如 Doris 等一些最新的工具,确实这些课是学校永远不会开设的,好在他说去了会带着我做一做。可是 ...... 学院舍不得让走啊 ...... 没办法,情况就是这么个情况,尽管我心里几百个我上早八

实在可悲,和辅导员说老师我拿到实习 offer 了,辅导员说哪都别去,乖乖学校上课,没课也给我老实待着,认真挺好每一节那还用担心就不了业?每每听到这句话我又按耐不住了。。。我tm没日没夜两年了,好不容易以为熬到头了,有个实习经历找工作能顺利一点 ....
言归正传,这学还是得上的,尽管我国的高等教育中有这么一大批自私自利、误人子弟、自认为高知的形式主义分子,每天的任务就是开会吹牛逼。但是我们个人还是尽量避免影响到自己,做好自己该做的。
1、实时数仓 VS 离线数仓
离线数仓的一大特点:T+1 ,其实就是时效性不强,今天只能计算得到昨天及之前的数据。而我们的实时数仓为的就是解决这么一个问题,但是不同业务需求对时效性要求也是不同的。比如电商报表就不需要毫秒级别的实时响应,毕竟报表是给人看的,毫秒级别的变化我们肉眼看得多难受;而且最重要的一点,延时性越低,对我们资源的消耗、硬件的配置也就越高,那必然浪费资源而且没有必要。但是对于一些智能驾驶、银行资金监控等一些领域必须要有毫秒级别的响应。
1.1、数仓架构
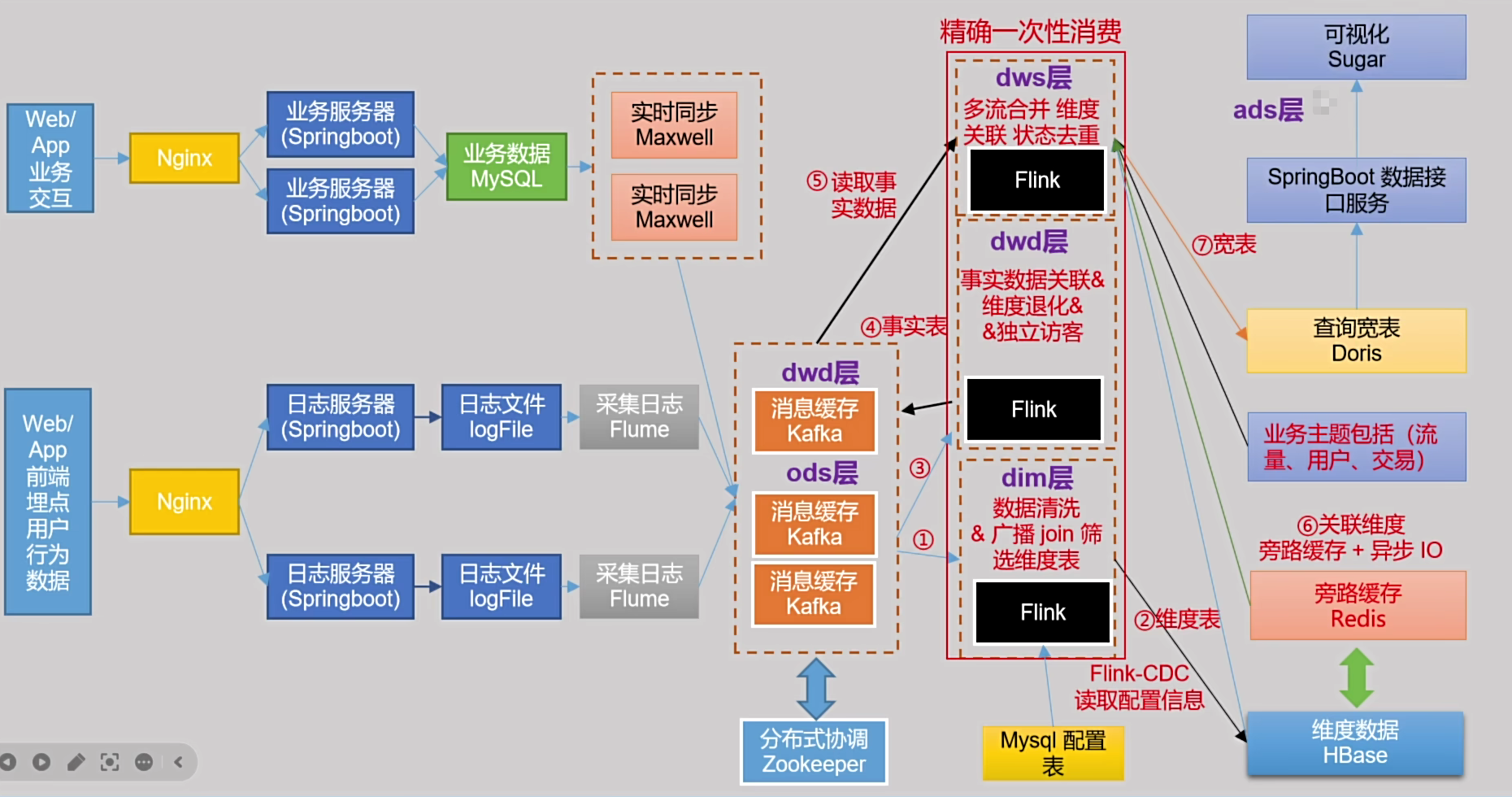
下面的架构图包含了我们之前的离线数仓和今天开始要学习的实时数仓:

1.1.1、ODS 层对比
ODS 层的任务为后续的数据清洗、转换、整合提供原料。离线数仓的 ODS 层做的主要就是数据备份,它会把数据映射为一张张 Hive 表,方便上层使用。而实时数仓的 ODS 层几乎是啥也不干,就做一些简单的工作比如过滤,因为实时数仓追求的是时效性。
实时数仓的ODS层强调的是高速度的数据收集与初步处理能力,以满足即时性数据分析的需要;而离线数仓的ODS层则侧重于稳定且周期性的数据整合,为深度分析和长期趋势的报告提供基础。
1.1.2、DWD 层对比
DWD 层在数仓中的任务就是拆分事实表,在离线数仓中,提取出实时数据后同样会映射为一张 Hive 表,存储到 HDFS 中。但在实时数仓中,它为了实时性所以一般写入到 Kafka 。
- 实时数仓的 DWD 层通常处理的是实时或近实时的数据流。它接收来自 ODS 层的原始数据,并进行初步的清洗和转换,以满足后续分析的需求。由于实时数仓强调数据的实时性,DWD层的设计会尽量减少数据处理的延迟,所以一般通过流式处理技术来实现快速的数据处理。比如采用 Kafka 来支持高吞吐量的数据写入和实时处理。
- 离线数仓的 DWD 层则更多地关注数据的详细存储和历史数据的积累。它通常基于 HDFS 等分布式文件系统来存储大量数据,并且会进行更为复杂的数据预处理,如数据的清洗、去重、变换等。离线数仓的 DWD 层在设计时会考虑空间和时间的权衡,可能会有更多的层级划分来提高效率。
1.1.3、DIM 层
DIM 层的主要作用就是存储维度数据,等到事实表聚合之后来进行一个维度关联(和维度表进行 join),所以需要持久化存储在一个地方。在之前的离线数仓中,我们依然是存到 Hive 中的。而在实时数仓中,我们一般会把 DIM 层的数据保存到 HBase 和 Redis。
1.1.4、DWS 层
DWS 层存储的一般是项目中可能需要重用的一些中间计算结果,在实时数仓中,我们一般会把这些宽表(join 得到的)存储在 Doris 中。
1.1.5、ADS 层
ADS 层主要做的是我们的指标分析,在之前的离线数仓中,我们是通过把计算出来的结果通过脚本(DataX)导出到关系型数据库再做展示的,毕竟离线项目中的指标一般变动不大。但是在实时数仓中,我们往往分析的是当下的一个指标,比如双十一,等到双十一过了我们就不需要这个指标了,可能就需要换成双十二了,所以我们的指标的变化比较快。所以一般我们在实时数仓中会选用 SpringBoot 数据服务接口在完成 ADS 层的开发。
1.2、技术选型
1.2.1、Doris 介绍
Apache Doris由百度大数据部研发(之前叫百度 Palo,2018年贡献到 Apache 社区后,更名为 Doris),在百度内部,有超过200个产品线在使用,部署机器超过1000台,单一业务最大可达到上百 TB。
Apache Doris是一个现代化的MPP (Massively Parallel Processing,即大规模并行处理)分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris的分布式架构非常简洁,易于运维,并且可以支持10PB以上的超大数据集。
Apache Doris可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。
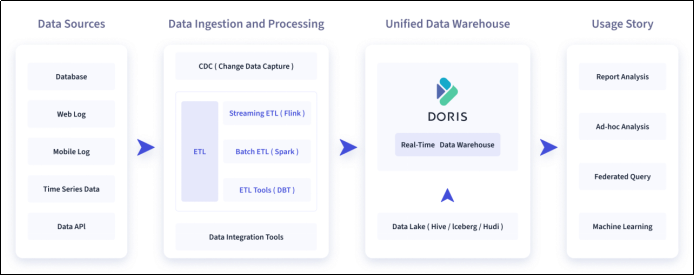
所以 Doris 的最大特点就是处理的数据量又大又快,当然它对开发环境的要求也是比较高的。
1.2.2、ODS 层
首先,不管离线还是实时数仓的数据都是存储在 Kafka 的主题当中的,离线数仓要用的时候会通过 Flume 去读取到 HDFS,然后再把这些数据映射为一张张 Hive 表。但是在实时数仓中并不需要,我们通常是什么时候下游(DWD、DIM)需要数据了,我们再从 Kafka 中读取除了进行一个简单的过滤发送到下游去。
所以,在实时数仓中,我们的 ODS 层指的就是 Kafka 的主题,在我们这个项目中,指的就是 topic_db 和 topic_log 这两个主题。
1.2.3、DWD 层
DWD 的数据要求是保持数据流的形式,进行下一步的聚合。所以能满足这一要求的就是 Kafka,毕竟 Kafka 现在也叫数据流平台。将来 DWD 层的数据我们会存储到 Kafka,用不同的主题对应不同的事实表。
所以对于 DWD 层的数据,我们是从 Kafka 来(ODS),再写回到 Kafka 中去(DWD)。
1.2.4、DIM 层
DIM 层是用来存储维度表的,其目的就是为了之后在数据聚合之后,再根据事实表的维度外键和我们的维度表进行关联。所以它就需要存储到一个地方(数据库),等待被 join。
关于 DIM 层数据的存储,我们需要进行一个技术选择:
- mysql:不擅长海量数据的存储
- redis:内存存储(不落盘)
- hbase:速度一般(相比较Hive快,谁和Hive比都快,所以hbase只是相对的快,大数据快,小数据并不快)但是键值对存储 getKey() 就比较快,适合海量数据存储
- doris:快,适合海量数据存储计算,但是使用成本比较高,尽量不要把大量原始数据存储到 doris
- clickHouse:列式存储,列式数据聚合操作速度快(早期实时数仓的 DWS 层采用 clickhouse)
综合考虑,首先 mysql 我们不采用,因为现在是流式数据场景,数据是一条一条来的,而关于 DIM 层中的数据,我们通常是用它去和 DWD 层的事实数据进行 join 的,所以来一条数据 join 一次用 hbase 是最合适的,因为它的 getKey 速度要快一些(通过 rowKey 获取某一单元格的数据),而 mysql 适合于对一整张表进行查询,并不符合我们这里的场景;redis 数据不能持久化也不可靠;doris 成本太高,而且我们现在的维度信息都还是原始数据状态;clickhouse 对于需要字段聚合操作的数据性能比较好,但是我们这里的维度数据并不需要聚合。所以我们最终选择 hbase 作为 DIM 层的数据存储工具,但是 hbase 毕竟速度一般,所以我们还会结合 redis 做一个旁路缓存优化。
1.2.5、DWS 层
DWS 层的任务就是聚合 DWD 层的数据(窗口聚合)并维度关联 DIM 层的数据,然后进行灵活的数据接口的编写,同时能够实现即席查询的功能,所以存储到 Doris(早期存储到 ClickHouse 中)。
1.2.6、ADS 层
ADS 层我们使用 SpringBoot 编写数据接口,读取 doris 数据来展示到报表上。
1.3、实时数仓和实时计算的比较
为什么我们不像之前学习 Flink 的时候一样直接编写一个 flink 程序,而要花费大量精力去开发一个实时数仓呢?
首先,如果我们的指标特别少(2~3个),那直接用一个 Flink 程序也没有问题,数据一来就直接给干到结果了。但是如果指标不断的变化、增加,比如现在有100个指标,那么就会出现大量的重复计算,开发的成本就会变高。
所以说数仓存在的意义,对数据处理流程进行规划、分层,目的就是提高数据的复用性。
1.4、离线数仓和实时数仓的比较
离线数仓擅长处理历史数据,提供深度的数据挖掘和分析能力,其优点在于数据质量高、准确性强、可靠性好。相比之下,实时数仓注重实时数据处理和快速响应,能够满足企业对实时性要求较高的业务需求。
2、数仓建模
数仓建模这里我们之前在学离线数仓的时候已经讲过了,这里只介绍实时数仓和离线数仓不同的地方。
规范化与反规范化
规范化是指使用一系列范式设计数据库的过程,其目的是减少数据冗余,增强数据的一致性。通常情况下,规范化之后,一张表的字段会拆分到多张表。
反规范化是指将多张表的数据冗余到一张表,其目的是减少join操作,提高查询性能。
在设计维度表时,如果对其进行规范化,得到的维度模型称为雪花模型,如果对其进行反规范化,得到的模型称为星型模型。

数据仓库系统的主要目的是用于数据分析和统计,所以是否方便用户进行统计分析决定了模型的优劣。采用雪花模型,用户在统计分析的过程中需要大量的关联操作,使用复杂度高,同时查询性能很差,而采用星型模型,则方便、易用且性能好。所以出于易用性和性能的考虑,离线维度表一般是很不规范化的-星型模型。
我们之前在离线数仓中使用的就是星型模型,它并不遵循三范式,毕竟我们不可能让数据不存在冗余,大数据场景下,存储空间往往是最不值钱的,我们只需要尽量减少数据的冗余,但是在一些情况下,依然允许数据冗余,比如维度退化。
实时数仓和离线数仓在维度模型上是不一样的,离线数仓我们不遵循三方式,毕竟我们的数据是一天一算,今天的数据收集完了,那么它就不会变了,即使存在数据冗余,比如用户张三一天内改了100次姓名,其实并不影响,因为对于维度属性变化的表,我们保存维度的策略有两种:全量快照表和拉链表,这里的用户信息数据量很大,我们一般会做一个拉链表,拉链表会在原始表上增加两个字段(开始日期和结束日期),所以我们只需要在查询的时候增加条件 where end_date='9999-12-31' 即可查到最后的状态。
但是对于流处理,我们的数据是实时增加而且可能发生变化的,比如上一个窗口中这个用户叫张三,下一个窗口他改名叫李四了。所以在实时数仓中,我们必须要遵循三范式,使用雪花模型来建模。
在离线数仓中,普通维度表是通过主维表和相关维表做关联查询生成的。与之对应的业务数表数据是通过每日一次全量同步导入到 HDFS 的,只须每日做一次全量数据的关联查询即可。而实时数仓中,系统上线后我们采集的是所有表的变化数据,这样就会导致一旦主维表或相关维表中的某张表数据发生了变化,就需要和其它表的历史数据做关联。
此时我们会面临一个问题:如何获取历史数据?
对于这个问题,一种方案是在某张与维度表相关的业务表数据发生变化时,执行一次 maxwell-bootstrap 命令,将相关业务数据库维度表的数据导入 Kafka。但是这样做又会面临三个问题:
- Kafka 中存储冗余数据;
- maxwell-bootstrap 命令交给谁去执行?必然要引入调度组件或功能;
- 实时数仓中的数据是以流的形式存在的,如果不同流中数据进入程序的机器时间差异过大就会出现 join 不上的情况。如何保证导入的历史数据和变化数据可以关联上?势必要尽可能及时地执行历史数据导入命令且在 Flink 程序中设置足够的延迟。而前者难以保证,后者又会影响整个实时数仓的时效性。综上,这种方案并不合理。
另一种方案是维度表发生变化时去 HBase 中读取关联后的维表,筛选受影响的数据,与变化或新增的维度信息(通常生产环境的业务数据库是不会删除的)做关联,再把关联后的数据写入HBase。但是考虑这样一种情况,以商品表为例,主维表为sku_info,相关维表有spu_info,base_trademark,base_category1,base_category2,base_category3等,假设base_category1表的某条数据发生了变化,HBase表受影响的数据非常多(base_category1表的粒度较粗),我们需要把这些数据取出来,修改,然后再写回HBase。显然,这种方案也不合理。
第三种方案是将分表导入 HBase,关联操作在 HBase 中完成。首先 HBase 的 join 性能很差,其次,关联操作不在流处理的 DAG 图中,需要单独调度,增加了系统复杂度。最后,当粒度较粗的维表数据发生变化时,受影响的数据很多。综上,这种方案也不合理。
基于上述分析,对业务表做 join 形成维度表的方式并不适用于实时数仓。
因此,在实时数仓中,我们不再对业务数据库中的维度表进行合并(离线数仓中我们在设计维度表的时候需要确定主维表和相关维表),仅对一些不需要的字段进行过滤,然后将维度数据写入 HBase 的维度表中,业务数据库的维度表和 HBase 的维度表是一一对应的。
写入维度数据使用HBase的put方法,实现幂等写入。当维度数据发生变化时,程序会用变化后的新数据覆盖旧数据。从而保证HBase中保存的是一份全量最新的维度数据。
这样做会产生一个问题:实时数仓没有保存历史维度数据,与数仓特征(保存历史数据)相悖。那么,维度表可以按照上述思路设计吗?
首先,我们要明确:数仓之所以要保存历史数据,是为了运用历史数据做一些相关指标的计算,而实时数仓本就是对最新的业务数据做分析计算,不涉及历史数据,因此无须保存。
此外,生产环境中实时数仓的上线通常不会早于离线数仓,如果有涉及到历史数据的指标,在离线数仓中计算即可。因此,实时数仓中只需要保留一份最新的维度数据,上述方案是切实可行的。
特别地,对于字典表,数据一般不会变化,而且我们至多只会用到 dic_code,dic_name 和parent_code三个字段,建立单独的维度表意义不大,选择将维度字段退化到事实表中。
3、项目架构设计准备
我们接下来会创建一个普通 Maven 项目 gmall2024-realtime ,并创建四个 module:
- realtime-common:用于引入公共的第三方依赖,编写工具类、实体类等。
- realtime-dim:用于编写DIM层业务代码。
- realtime-dwd:用于编写DWD层业务代码。
- realtime-dws:用于编写DWS层业务代码。
其中,后三个module统称为业务模块,业务模块都要将realtime-common模块作为依赖引入。
3.1、创建父工程 gmall2024-realtime
在父项目中声明一些依赖,这些依赖不会打包到 jar 包里,但是我们在本地运行的时候需要提供:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.lyh</groupId>
<artifactId>gmall2024-realtime</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>realtime-common</module>
<module>realtime-dim</module>
<module>realtime-dwd</module>
<module>realtime-dws</module>
</modules>
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.17.1</flink.version>
<scala.version>2.12</scala.version>
<hadoop.version>3.3.4</hadoop.version>
<flink-cdc.vesion>2.4.0</flink-cdc.vesion>
<fastjson.version>1.2.83</fastjson.version>
<hbase.version>2.4.11</hbase.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency><!--在 idea 运行的时候,可以打开 web 页面-->
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!--如果保存检查点到hdfs上,需要引入此依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-reload4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
<scope>provided</scope>
</dependency>
<!--Flink默认使用的是slf4j记录日志,相当于一个日志的接口,我们这里使用log4j作为具体的日志实现-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-loader</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>${flink-cdc.vesion}</version>
</dependency>
<!-- hbase 依赖-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-reload4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-2.2</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.doris/flink-doris-connector-1.17 -->
<dependency>
<groupId>org.apache.doris</groupId>
<artifactId>flink-doris-connector-1.17</artifactId>
<version>1.4.0</version>
</dependency>
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.4</version>
</dependency>
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>6.2.4.RELEASE</version>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<!--原本是 3.1.1-->
<version>3.5.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
<exclude>org.apache.hadoop:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. -->
<!-- 打包时不复制META-INF下的签名文件,避免报非法签名文件的SecurityExceptions异常-->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<!-- The service transformer is needed to merge META-INF/services files -->
<!-- connector和format依赖的工厂类打包时会相互覆盖,需要使用ServicesResourceTransformer解决-->
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>dependencyManagement 标签下的依赖同样不会被打包进 jar 包,它在这里只是起到一个管理版本的作用。
3.2、创建公共模块 realtime-common
新建子模块 realtime-common ,导入依赖,这里的依赖不需要写版本号,因为我们都是继承自父工程 gmall2024-realtime 的,它帮我们进行了版本管理。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>gmall2024-realtime</artifactId>
<groupId>org.lyh</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>realtime-common</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
</dependency>
<!-- hbase 依赖-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-2.2</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.doris/flink-doris-connector-1.17 -->
<dependency>
<groupId>org.apache.doris</groupId>
<artifactId>flink-doris-connector-1.17</artifactId>
</dependency>
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
</dependency>
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</dependency>
</dependencies>
</project>在 realtime-common 模块中,除了要把一些公共的包导进来,还需要把一些全局使用的东西配置一下,比如 log4j 和一些公共的类库:
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %10p (%c:%M) - %m%n
log4j.rootLogger=error,stdout
3.3、创建其它子模块
新建子模块 realtime-dim、这些模块都不再需要导入所以依赖了,只需要继承导入 realtime-common 模块即可。
<dependencies>
<dependency>
<groupId>org.lyh</groupId>
<artifactId>realtime-common</artifactId>
<version>1.0-SNAPSHOT</version>
<scope>provided</scope>
</dependency>
</dependencies>总结
至此,准备工作基本完成了,这一节最重要的就是学习离线数仓和实时数仓的一些区别了,比如每一层的存储方式,在离线数仓中我们不需要考虑时效性,所以存到 HDFS 当中即可,但是实时数仓考虑到时效性,我们的数据尽可能以一个流的形式被处理,所以我们的实时数仓主要借助 Kafka 以及 HBase、Redis 等一些快速或者在大数据场景下相对快速的工具进行数据存储。