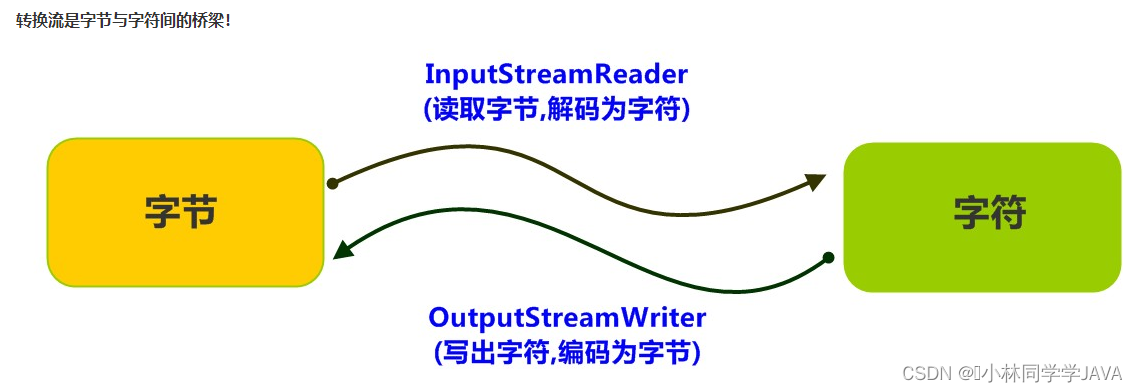
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。

- 推荐:「stormsha的主页」👈,持续学习,不断总结,共同进步,为了踏实,做好当下事儿~
- 专栏导航
- Python面试合集系列:Python面试题合集,剑指大厂
- GO基础学习笔记系列:记录博主学习GO语言的笔记,该笔记专栏尽量写的试用所有入门GO语言的初学者
- 数据库系列:详细总结了常用数据库 mysql 技术点,以及工作中遇到的 mysql 问题等
- 运维系列:总结好用的命令,高效开发
- 算法与数据结构系列:总结数据结构和算法,不同类型针对性训练,提升编程思维
非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。💝💝💝 ✨✨ 欢迎订阅本专栏 ✨✨
|
💖The Start💖点点关注,收藏不迷路💖
|
📒文章目录
- 1、概述
- 2、Conv2d 核心参数
- 2.1、什么是卷积核(kernel)?
- 2.2、可训练参数(Trainable Parameters)和偏置(Bias)
- 2.3、输入通道和输出通道的数量(Number of Input and Output Channels)
- 2.4、卷积核大小(Kernel size)
- 2.5、步长(Strides)
- 2.6、填充(Padding)
- 2.7、膨胀(Dilation)
- 2.8、组(Groups)
- 2.9、输出通道大小(Output Channel Size)
- 3、总结
1、概述
随着人功智能的发展,涌现出了很多深度学习的库和平台,如Tensorflow、Keras、Pytorch、Caffe或Theano,在我们的日常开发中为我们提供很多帮助,基于这些深度学习库的应用程序层出不穷也让我们感到惊叹。每个开发者都有自己最喜欢的框架,它们的共同点是易于使用且可根据需要进行配置使我们的工作变得简单。但我们还是需要了解这些工具可用的论据是什么,以便更好地利用这些框架赋予我们的所有功能。
在这篇文章中,我将尝试列出所有这些参数。如果你想了解它们对计算时间、可训练参数的数量以及卷积输出通道大小的影响,那么这篇文章适合你。

Input Shape : (3, 7, 7) — Output Shape : (2, 3, 3) — K : (3, 3) — P : (1, 1) — S : (2, 2) — D : (2, 2) — G : 1
2、Conv2d 核心参数
这篇文章的部分内容将根据以下参数进行讲解。这些参数可以在 Pytorch Conv2d 模块的文档中找到
- in_channels(int)- 输入图像的通道数
- out_channels(int)- 卷积生成的通道数
- kernel_size(int 或 tuple)- 卷积核的大小
- stride(int 或 tuple,可选)- 卷积的步长。默认:1
- padding(int 或 tuple,可选)- 添加到输入两侧的零填充。默认:0
- dilation(int 或 tuple,可选)- 核元素之间的间距。默认:1
- groups(int,可选)- 从输入通道到输出通道的块连接数。默认:1
- bias(bool,可选)- 如果为 True,则在输出中添加可学习的偏置。默认:True
最后,我们将掌握根据参数和输入通道大小计算输出通道大小的所有关键点。
2.1、什么是卷积核(kernel)?
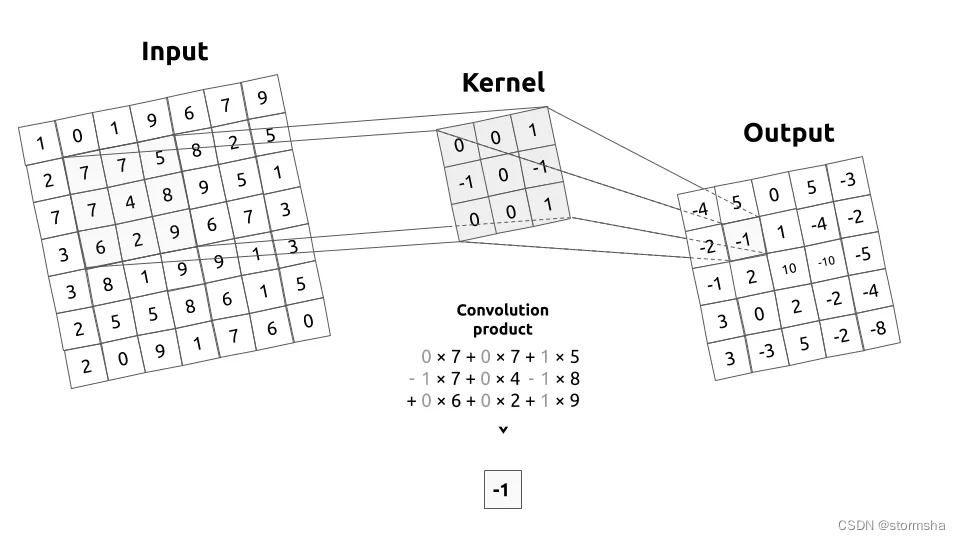
输入图像和kernel之间的卷积过程
先介绍一下 kernel(或卷积矩阵)是什么。 kernel 描述了我们将要在一个输入图像上进行卷积操作的滤波器。简单来说, kernel 会在整个图像上移动,从左到右,从上到下,通过应用卷积运算。这个操作的输出被称为过滤图像。
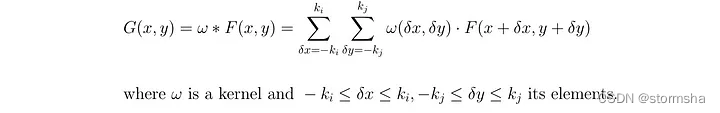
卷积积(Convolution product)

Input shape : (1, 9, 9) — Output Shape : (1, 7, 7) — K : (3, 3) — P : (0, 0) — S : (1, 1) — D : (1, 1) — G : 1
举一个非常基本的例子,让我们想象一个3乘3的卷积核对一个9乘9的图像进行过滤。然后,这个卷积核(Convolution Kernel)会在整个图像上移动,以捕捉图像中所有相同大小的方块(3乘3)。卷积积(Convolution product)是一种元素级(或点积)的乘法。这个结果的总和就是输出(或过滤后)图像上的像素值。
如果你对滤波器和卷积矩阵还不熟悉,那么我强烈建议你花更多的时间来理解卷积核(Convolution Kernel)。它们是二维卷积层的核心。
2.2、可训练参数(Trainable Parameters)和偏置(Bias)
可训练参数,也被称为“参数”,是在网络训练过程中将被更新的所有参数。在Conv2d中,可训练的元素是构成卷积核的值。所以对于我们的3乘3卷积核,我们有3*3=9个可训练参数。
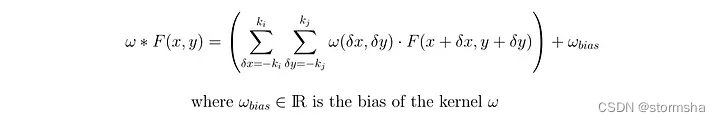
卷积积(Convolution Product)与偏置(Bias)
为了更完整,我们可以包括偏置或不包含。偏置的作用是被添加到卷积积的总和中。这个偏置也是一个可训练参数,这使得我们3乘3卷积核的可训练参数数量上升到10个。
2.3、输入通道和输出通道的数量(Number of Input and Output Channels)
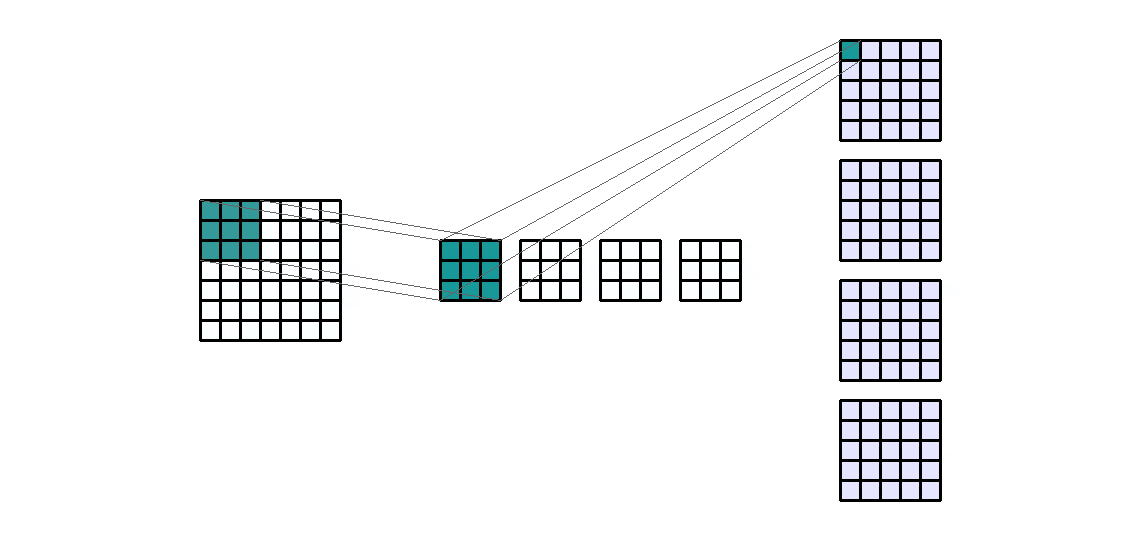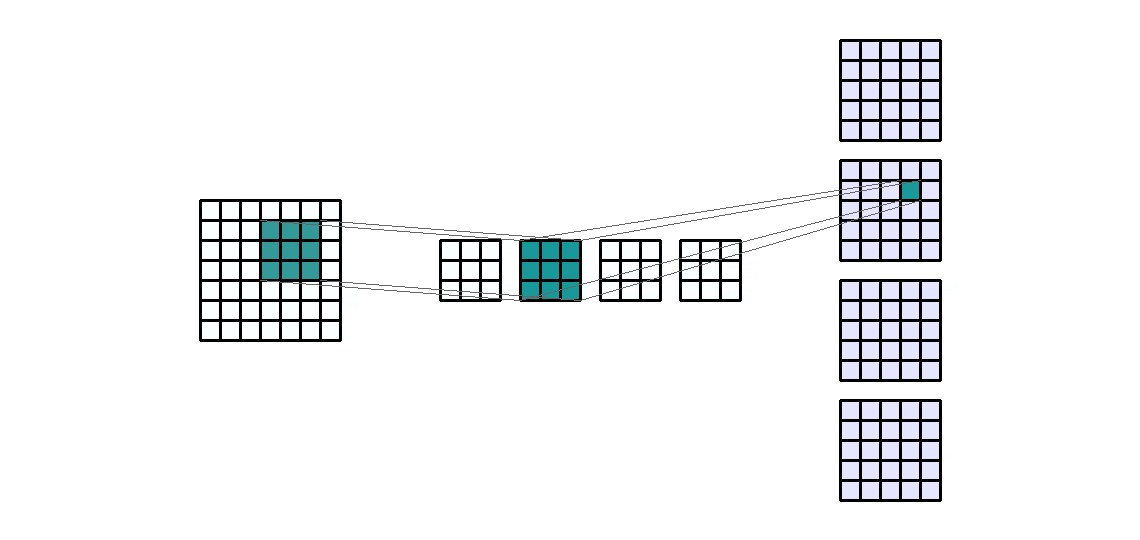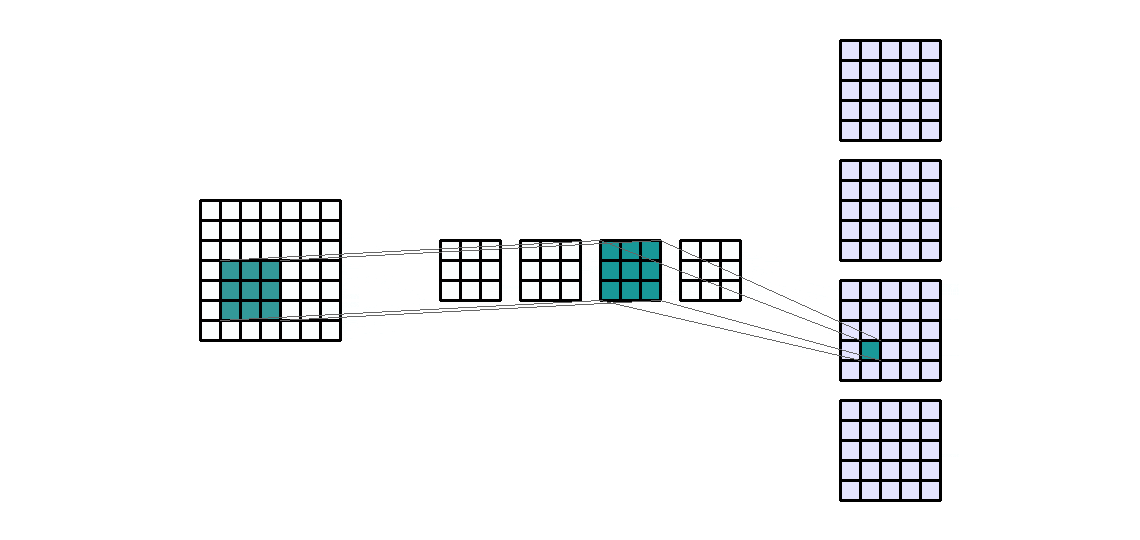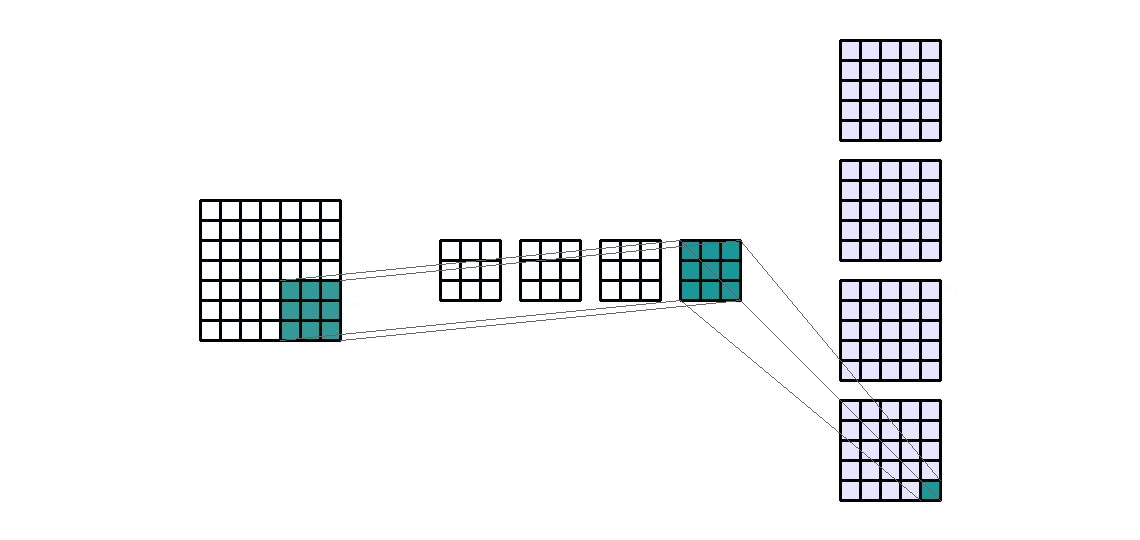
Input Shape: (1, 7, 7) — Output Shape : (4, 5, 5) — K : (3, 3) — P : (0, 0) — S : (1, 1) — D : (1, 1) — G : 1
使用层级结构的优势在于能够同时执行类似的操作。换句话说,如果我们想对一个输入通道应用4个相同大小的不同滤波器,那么我们将得到4个输出通道。这些通道是4个不同滤波器的结果。所以来自于4个不同的卷积核。
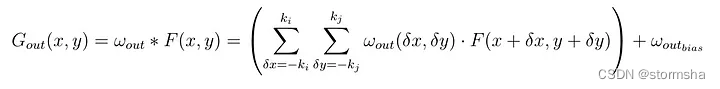
随着卷积核数量的增加,参数的数量也会线性增加。因此,它也与所需的输出通道数量成线性关系。同样需要注意的是,计算时间也与输入通道的大小和卷积核的数量成正比。
参数图中的曲线是相同的
同样的原则也适用于输入通道的数量。让我们考虑一个使用RGB编码的图像的情况。这个图像有3个通道:红、蓝和绿。我们可以决定使用相同大小的滤波器在这三个通道上提取信息,以获得四个新的通道。因此,这个操作在三个通道上是相同的,用于获得四个输出通道。

Input Shape: (3, 7, 7) — Output Shape : (4, 5, 5) — K : (3, 3) — P : (0, 0) — S : (1, 1) — D : (1, 1) — G : 1
每个输出通道是过滤后的输入通道的总和。对于4个输出通道和3个输入通道,每个输出通道是3个过滤后的输入通道的总和。换句话说,卷积层由4*3=12个卷积核组成。
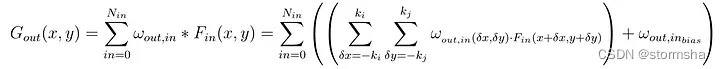
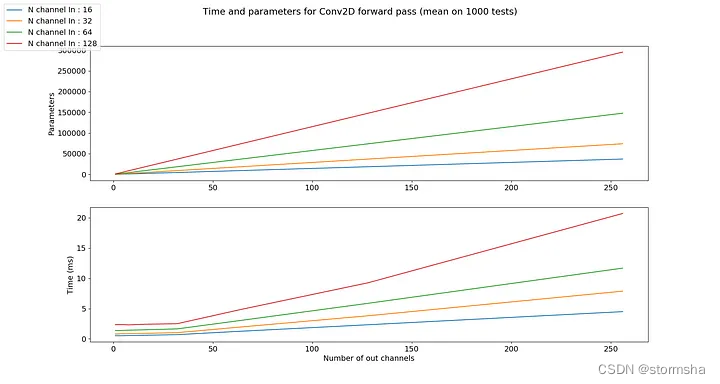
参数的数量和计算时间与输出通道的数量成正比。这是因为每个输出通道都与与其他通道不同的卷积核相关联。对于输入通道的数量也是如此。计算时间和参数数量会按比例增长。
2.4、卷积核大小(Kernel size)
到目前为止,所有的例子都是使用3乘3大小的卷积核。事实上,选择它的大小完全取决于你。你可以创建一个具有11或1919大小的卷积层。
并不是必须使用正方形的卷积核。可以选择具有不同高度和宽度的卷积核。这在信号图像分析中经常出现。如果我们知道我们想要扫描一个信号或声音的图像,那么我们可能更喜欢使用5*1大小的卷积核。如下图所示:

Input Shape: (3, 7, 9) — Output Shape : (2, 3, 9) — K : (5, 2) — P : (0, 0) — S : (1, 1) — D : (1, 1) — G : 1
你会注意到所有大小都由奇数定义。定义一个偶数的卷积核大小也是可以接受的。但在实践中,这很少做。通常选择奇数大小的卷积核,因为在中心像素周围有对称性。
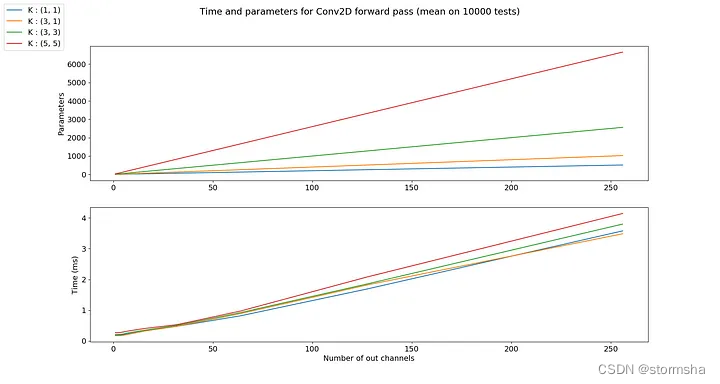
由于卷积层的所有(经典)可训练参数都在卷积核中,所以参数的数量随着卷积核大小的增加而线性增长。计算时间也成比例变化。
2.5、步长(Strides)
默认情况下,卷积核从左到右、从上到下逐个像素进行移动。但这种移动也可以改变。通常用于对输出通道进行降采样。例如,使用步长为(1, 3),滤波器在水平方向上每3个像素移动一次,在垂直方向上每1个像素移动一次。这将产生水平方向上降采样3倍的输出通道。

Input Shape: (3, 9, 9) — Output Shape : (2, 7, 3) — K : (3, 3) — P : (0, 0) — S : (1, 3) — D : (1, 1) — G : 1
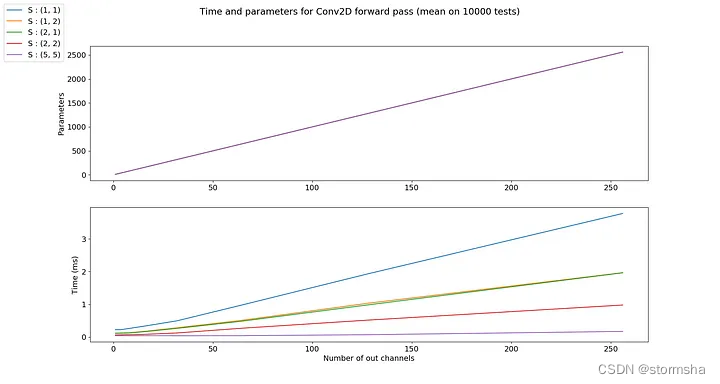
步长对参数数量没有影响,但计算时间会随着步长的增加而线性减少。
2.6、填充(Padding)
填充是指在对输入通道进行卷积滤波之前,添加到输入通道边缘的像素数量。通常,填充像素被设置为零。输入通道被扩展。

Input Shape : (2, 7, 7) — Output Shape : (1, 7, 7) — K : (3, 3) — P : (1, 1) — S : (1, 1) — D : (1, 1) — G : 1
当您希望输出通道的大小等于输入通道的大小时,这非常有用。简单来说,当卷积核为3*3时,输出通道的大小在每个方向上减小一个像素。为了解决这个问题,我们可以使用1个像素的填充。
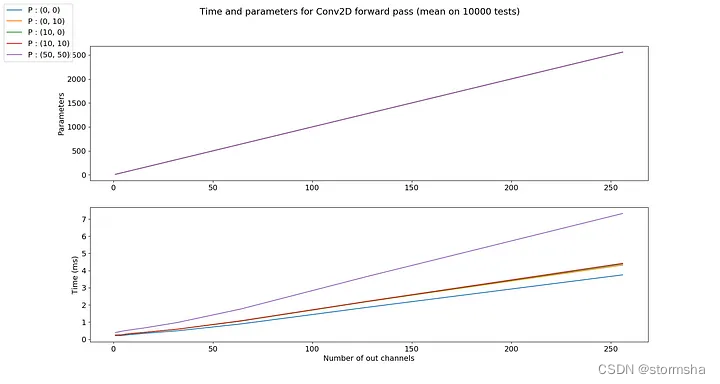
参数图中的曲线是相同的。
因此,填充对参数数量没有影响,但会产生与填充大小成正比的额外计算时间。但通常来说,填充相对于输入通道的大小来说通常足够小,可以认为对计算时间没有影响。
2.7、膨胀(Dilation)
膨胀可以看作是卷积核的宽度。默认情况下等于1,它对应于卷积过程中卷积核在输入通道上的每个像素之间的偏移量。

Input Shape: (2, 7, 7) — Output Shape : (1, 1, 5) — K : (3, 3) — P : (1, 1) — S : (1, 1) — D : (4, 2) — G : 1
在GIF图中有点夸张,但如果我们以(4, 2)的膨胀为例,那么卷积核在输入通道上的感受野在垂直方向上会扩大4 * (3 -1)=8个像素,在水平方向上会扩大2 * (3-1)=4个像素(对于一个3乘3的卷积核)。
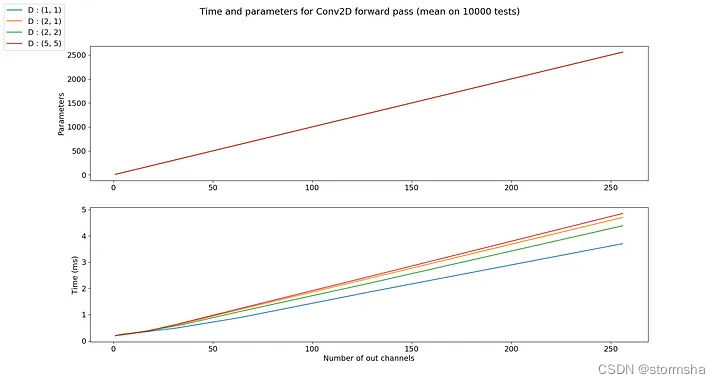
参数图中的曲线是相同的。
就像填充一样,膨胀对参数数量没有影响,对计算时间的影响也非常有限。
2.8、组(Groups)
在某些特定情况下,组可以非常有用。例如,如果我们有多个连接的数据源。当没有必要将它们相互依赖地处理时,输入通道可以分组并独立处理。最后,输出通道在结束时连接在一起。
如果有2个输入通道和4个输出通道,并且有2个组。那么这就像将输入通道分成两个组(每个组中有1个输入通道),并通过一个输出通道数量减半的卷积层。然后输出通道被连接在一起。
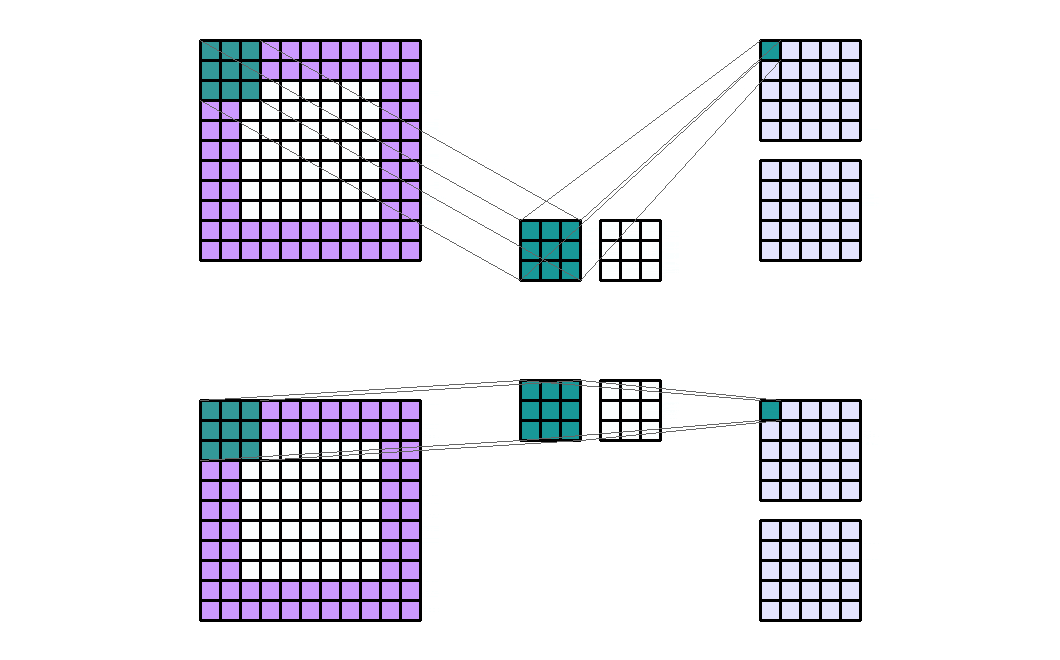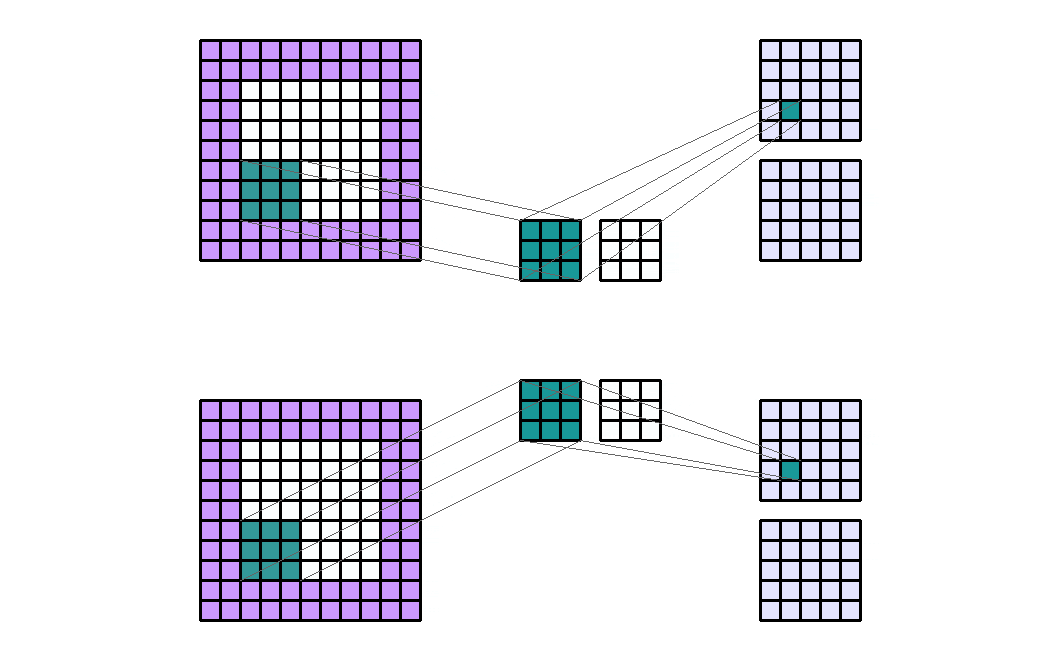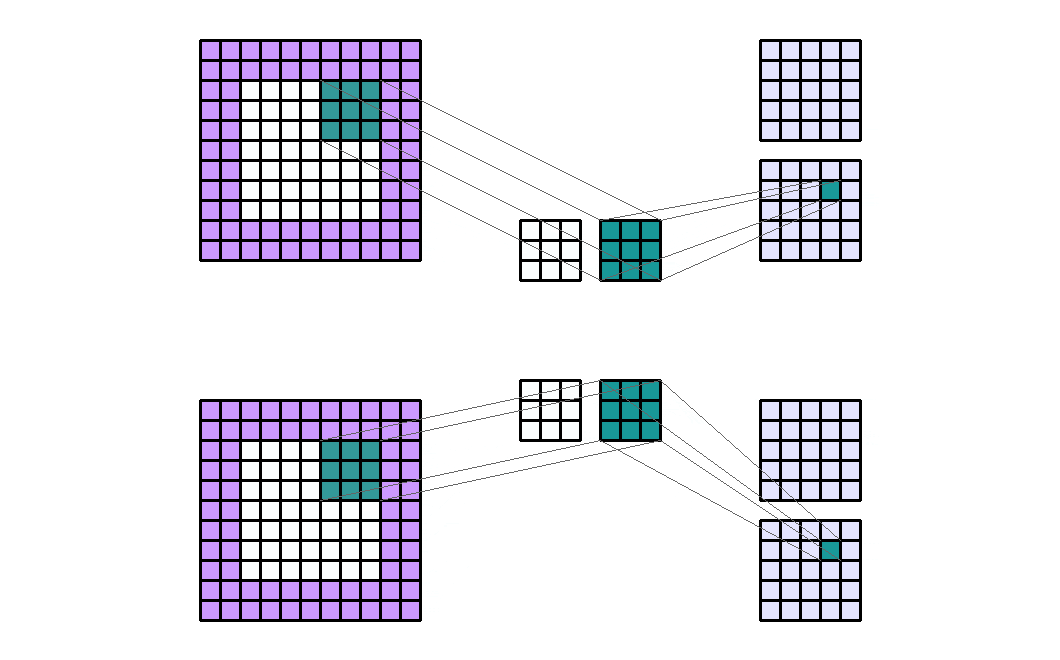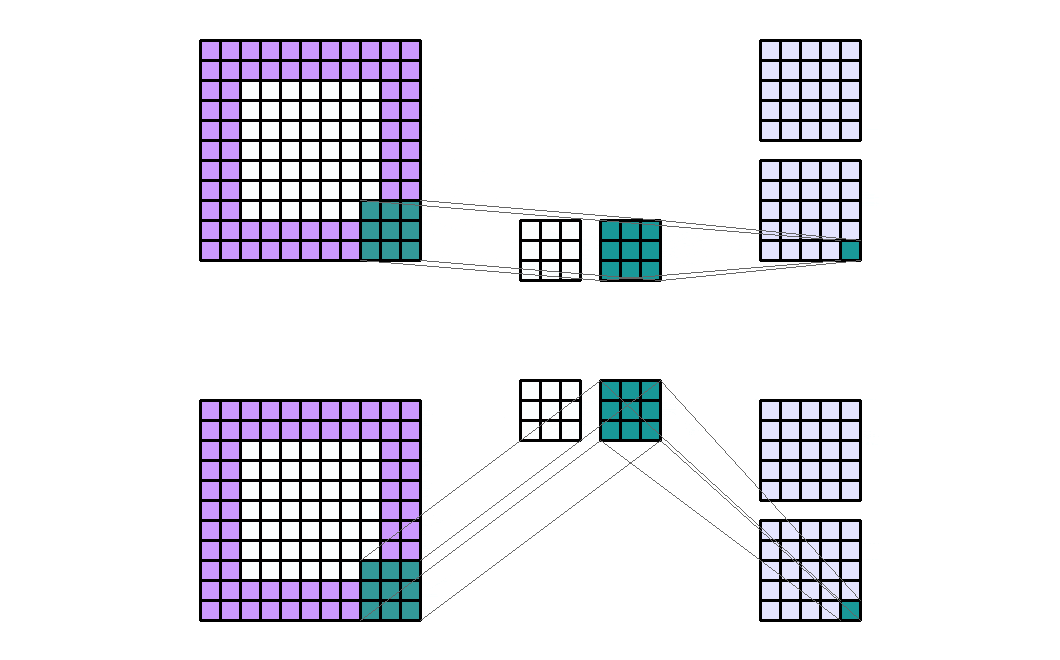
Input Shape : (2, 7, 7) — Output Shape : (4, 5, 5) — K : (3, 3) — P : (2, 2) — S : (2, 2) — D : (1, 1) — G : 2
需要注意的是,组的数量必须能够整除输入通道的数量和输出通道的数量(公因数)。
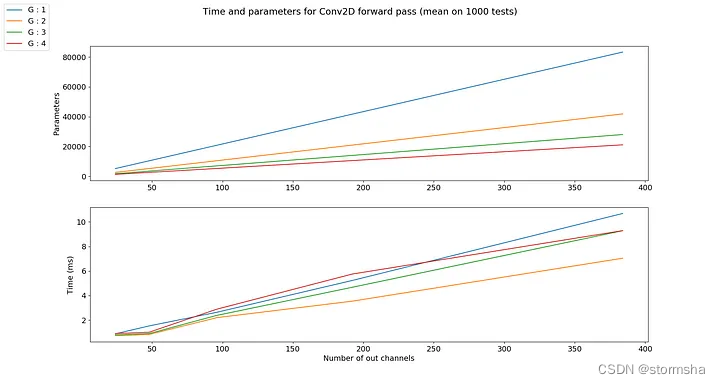
因此,参数的数量被组的数量所除。至于使用Pytorch的计算时间,算法针对组进行了优化,因此应该减少计算时间。然而,也应该考虑到必须将组的形成和输出通道的连接的计算时间相加。
2.9、输出通道大小(Output Channel Size)
有了所有参数的知识,就可以根据输入通道的大小计算输出通道的大小。

3、总结
所有计算时间测试都是使用Pytorch在我的GPU(GeForce GTX 960M)上进行的,如果你想自己运行它们或进行其他测试,Gitee仓库地址:https://gitee.com/stormsha/conv2d_demo
以上所有的GIF图像都是由Python生成,源码地址:Gitee仓库地址:https://gitee.com/stormsha/conv2d_demo
参考:
Deep Learning Tutorial, Y. LeCun
Documentation torch.nn, Pytorch
Convolutional Neural Networks, cs231n
Convolutional Layers, Keras
❤️❤️❤️本人水平有限,如有纰漏,欢迎各位大佬评论批评指正!😄😄😄
💘💘💘如果觉得这篇文对你有帮助的话,也请给个点赞、收藏、分享下吧,非常感谢!👍 👍 👍
🔥🔥🔥道阻且长,行则将至,让我们一起加油吧!🌙🌙🌙
|
💖The End💖点点关注,收藏不迷路💖
|