📝个人主页:五敷有你
🔥系列专栏:算法分析与设计
⛺️稳中求进,晒太阳

题目
DNA序列 由一系列核苷酸组成,缩写为
'A','C','G'和'T'.。
- 例如,
"ACGAATTCCG"是一个 DNA序列 。在研究 DNA 时,识别 DNA 中的重复序列非常有用。
给定一个表示 DNA序列 的字符串
s,返回所有在 DNA 分子中出现不止一次的 长度为10的序列(子字符串)。你可以按 任意顺序 返回答案。
示例
示例 1:
输入:s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT" 输出:["AAAAACCCCC","CCCCCAAAAA"]示例 2:
输入:s = "AAAAAAAAAAAAA" 输出:["AAAAAAAAAA"]
提示:
0 <= s.length <= 105
思路
这个算法的思路是使用一个哈希表来记录每个长度为10的子串的出现次数。具体步骤如下:
- 创建一个空的 ArrayList 来存储重复出现的长度为10的子串。
- 创建一个 HashMap 来存储子串及其出现的次数,其中键为子串,值为子串出现的次数。
- 遍历字符串 s 的每个字符,从索引 0 开始直到索引 n-10。这样可以保证在截取长度为10的子串时不会超出字符串的范围。
- 在每次迭代中,使用 s.substring(i, i + 10) 截取长度为10的子串。
- 将截取得到的子串作为键,查询哈希表中是否已经存在该子串。如果存在,则更新该子串的出现次数加1;如果不存在,则将该子串作为键,出现次数初始化为1。
- 检查当前子串在哈希表中的出现次数,如果等于2,则将该子串添加到结果集合中。
- 最后返回结果集合。
这个算法的时间复杂度是 O(n),其中 n 是字符串 s 的长度,因为需要遍历整个字符串一次。空间复杂度也是 O(n),因为需要存储哈希表和结果集合。
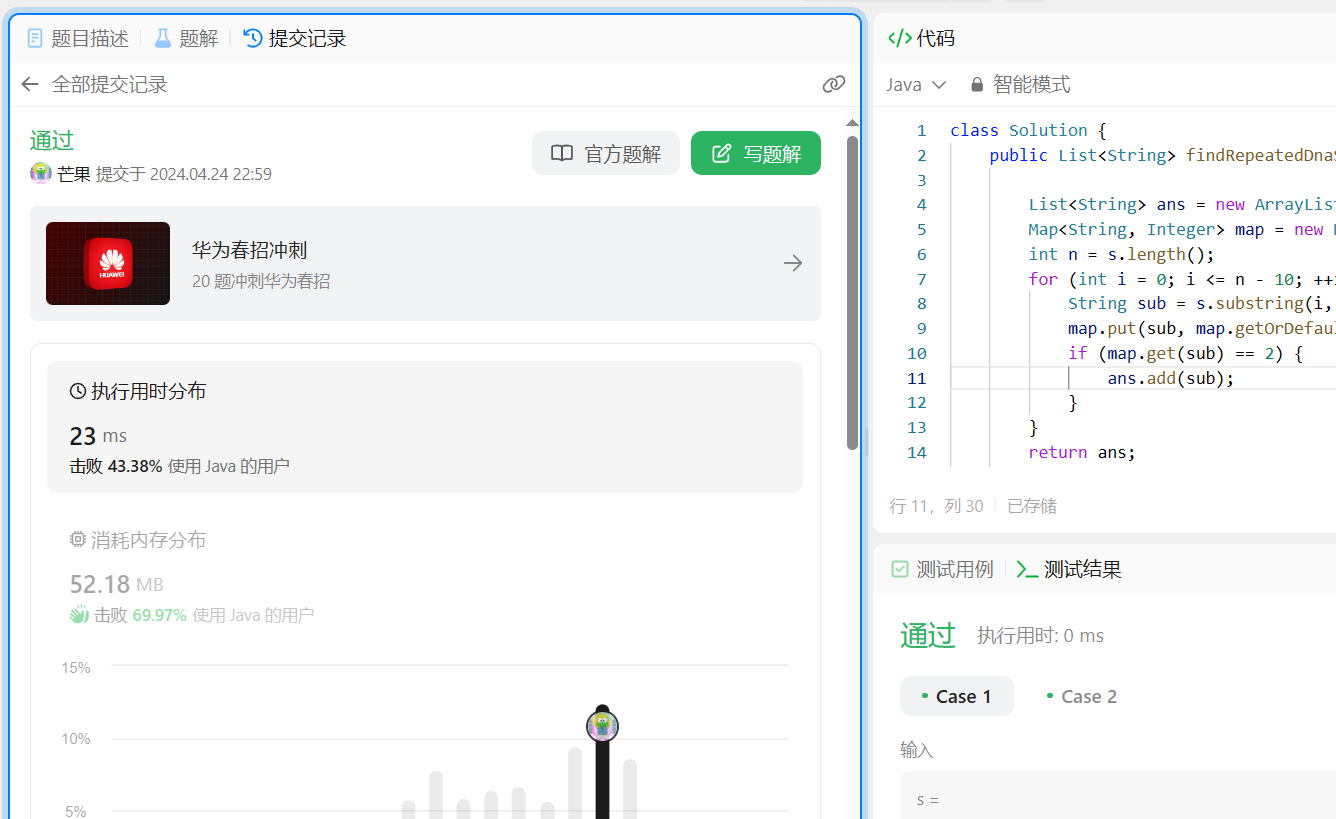
代码实现
class Solution {
public List<String> findRepeatedDnaSequences(String s) {
List<String> ans = new ArrayList<String>();
Map<String, Integer> map = new HashMap<String, Integer>();
int n = s.length();
for (int i = 0; i <= n - 10; ++i) {
String sub = s.substring(i, i + 10);
map.put(sub, map.getOrDefault(sub, 0) + 1);
if (map.get(sub) == 2) {
ans.add(sub);
}
}
return ans;
}
}运行结果