文章目录
- 索引的概述
- 索引的优劣势
- 优势
- 劣势
- 索引的分类
- 实现索引的数据结构
- B 树(B-Tree)
- B+树(B+ Tree)
- 哈希索引(Hash Index)
前言: 相信接触过编程的同学都听说过 索引,那么到底什么是索引?它又有什么作用呢?本篇文章将为你答疑解惑。
索引的概述
索引是数据库中的一种数据结构,用于快速查找和访问数据库表中的特定数据。它类似于书籍中的目录,可以帮助快速找到需要的信息而不必逐页查找。
在数据库中,索引可以根据某个或多个字段的值排序并保存,这样数据库就可以通过索引快速定位到符合特定条件的数据行,而不必全表扫描,大大提高数据库的查询性能和效率。
索引的优劣势
优势
-
提高查询性能: 索引可以显著提高数据库查询的性能,特别是对于大型数据表而言。通过使用索引,数据库可以快速定位到符合查询条件的数据,而不必扫描整个表。
-
加速数据检索: 索引使得数据库系统能够更快速地定位到特定数据,从而加速了数据检索的过程。这对于常见的查询操作非常有用,例如等值查询、范围查询等。
-
支持唯一性约束: 索引可以用于强制实施唯一性约束,确保特定列或字段中的值是唯一的。这有助于保持数据的一致性和完整性。
-
优化排序和连接操作: 索引可以提高排序和连接操作的效率。当数据库需要对查询结果进行排序或者执行多表连接时,索引可以帮助数据库更快速地完成这些操作。
劣势
-
增加写操作的开销: 索引不仅提高了读取性能,也会增加写入操作(插入、更新、删除)的开销。因为每次写入操作都可能需要更新索引,这会导致额外的性能开销。
-
占用存储空间: 索引需要额外的存储空间来存储索引数据结构和索引值。对于大型数据表来说,索引可能会占用相当大的存储空间,特别是在内存中。
-
维护成本高: 维护索引需要数据库系统定期对索引进行重建、重新组织或者优化。这需要消耗系统资源和时间,特别是在数据量大的情况下。
-
过多索引影响性能: 过多的索引可能会影响数据库的性能,因为每个索引都需要额外的系统资源和维护成本。此外,过多的索引也可能导致查询优化器选择不合适的索引,从而降低查询性能。
虽然索引可以显著提高数据库的查询性能和效率,但在设计和使用时需要权衡其优劣势,避免过度索引和滥用索引,以确保数据库的性能和可维护性。
索引的分类
索引可以根据其实现方式、数据结构以及应用场景进行分类,下面是一些常见的索引分类:
1.单值索引
- 单值索引是最基本的索引类型,它通过将每个索引键映射到一个数据行或者数据块来加速查询。
- 单值索引可以用于任何类型的数据,例如数字、字符串等。
2.复合索引
- 复合索引是由多个列组合而成的索引,它可以提高针对多个列的查询性能。
- 复合索引可以包含多个列,查询时可以同时利用这些列来加速检索,从而提高查询效率。
3.唯一索引
- 唯一索引要求索引列中的所有值都是唯一的,用于实施唯一性约束。
- 唯一索引通常用于确保数据库表中某列或组合列的值不重复,例如主键列或者候选键列。
4.聚集索引
- 聚集索引定义了数据的物理排序顺序,并且表中的行按照索引键值的顺序进行存储。
- 聚集索引通常与主键相关联,如果表中有主键,则主键通常是聚集索引。每个表只能有一个聚集索引。
5.非聚集索引
- 非聚集索引是独立于数据存储顺序的索引,它将索引键值映射到数据行的物理位置。
- 一个表可以有多个非聚集索引,非聚集索引通常用于加速对表的特定列的查询。
6.全文索引
- 全文索引用于在文本数据中进行全文搜索,而不仅仅是对特定的字段进行匹配。
- 全文索引通常用于支持关键字搜索、短语搜索等功能。
7.哈希索引
- 哈希索引使用哈希函数将索引键值映射到存储位置,用于支持快速的等值查询。
- 哈希索引通常用于等值查询,例如查找一个具体的值是否存在。
实现索引的数据结构
索引的实现依赖于不同的数据结构,常见的包括 B树、B+树、哈希表 等。
B 树(B-Tree)
B 树又称 B- 树,是一种多路搜索树,用于对大量数据进行高效存储和检索。

图片来源 —— 8分钟,复习一遍B树,B+树!
它的每个节点可以有多个子节点,并且节点中的键值按照升序排列。B 树的实现能够使得每次查找的时间复杂度保持在 O(log n) 的水平(算法的效率随着输入规模的增加而增加,但非常缓慢)。
数据库通过 B 树的节点结构将索引键值和指向子节点的指针存储在磁盘上,这样可以有效地组织和管理索引数据。
优势
-
适用于磁盘存储:B 树的节点大小一般和磁盘页大小相近,适合于在磁盘上进行快速的顺序访问和随机访问。
-
支持范围查询:由于 B 树的节点中存储了有序的键值,因此支持范围查询的效率较高。
-
高度平衡:B 树通过自平衡的方式维持了树的平衡性,保证了查询效率的稳定性。
劣势
- 不适用于内存存储:B 树的节点通常较大,不适合于内存存储。对于大部分存储在内存中的数据,B 树的优势可能不如其他数据结构明显。
应用场景
适用于需要在磁盘上进行高效的数据存储和检索的场景,因为 B 树的节点大小一般和磁盘页大小相近,可以减少磁盘 I/O 操作次数。
在磁盘 IO 中,每次都是读取一块数据到内存中,不论数据中的数据是否全部被用到,都将读取。B 树在一个结点中保存了多个数据,对一个结点的读写,可一次从磁盘中读取,进而可节省大量 IO 开销。
对应产品 —— Mongodb
B+树(B+ Tree)
B+ 树是在 B 树的基础上进行了改进,更适合于磁盘存储的场景。
与 B 树不同的是,B+ 树的内部节点不存储数据,只存储键值和指向子节点的指针。所有的数据都存储在叶子节点中,叶子节点之间通过指针连接形成一个有序链表。
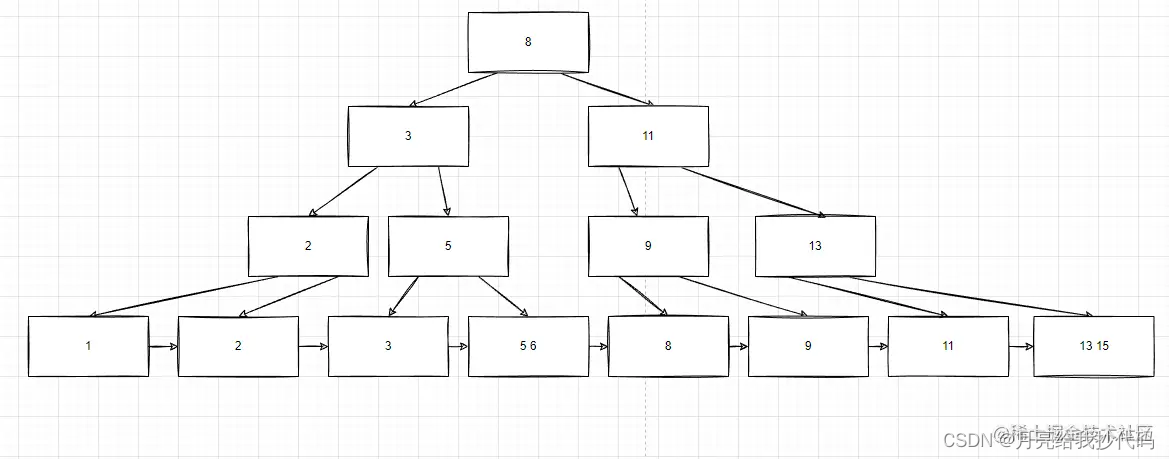
图片来源 —— 8分钟,复习一遍B树,B+树!
B+ 树的叶子节点形成了一个有序链表,支持范围查询和顺序访问。
数据库通过 B+ 树的节点结构将索引键值和指向子节点的指针存储在磁盘上,叶子节点中存储了完整的数据行或者数据块,这样可以实现高效的范围查询和顺序访问。
优势
-
适用于范围查询:B+ 树的叶子节点形成了一个有序链表,支持范围查询和顺序访问,因此适合于范围查询场景。
-
更高的磁盘利用率:B+ 树内部节点不存储数据,只存储键值和指向子节点的指针,因此可以实现更高的磁盘利用率。
劣势
- 不适用于随机访问:由于数据只存储在叶子节点中,因此对于随机访问的查询效率可能较低。
应用场景
适用于范围查询和顺序访问频繁的场景,因为 B+ 树的叶子节点形成了有序链表,支持快速范围查询和顺序遍历操作。
常见于需要支持范围查询的数据库系统中,例如处理时间范围、价格范围等查询场景。
对应产品 —— MySQL
哈希索引(Hash Index)
哈希索引使用哈希函数将索引键值映射到存储位置,用于支持快速的等值查询。适用于等值查询,但不适用于范围查询。
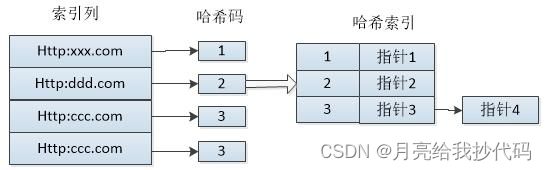
图片来源 —— Mysql索引
数据库通过哈希函数将索引键值映射到哈希表中的存储位置,然后直接访问该位置以获取数据。哈希索引通常需要解决哈希冲突、动态扩展等问题。
优势
-
高效的等值查询:哈希索引通过哈希函数将索引键值映射到存储位置,支持高效的等值查询。
-
适用于内存存储:哈希索引对于内存存储的数据具有较高的效率,可以在内存中快速定位到目标数据。
劣势
-
不支持范围查询:哈希索引不支持范围查询,只能用于等值查询。
-
哈希冲突:由于哈希函数的映射可能存在冲突,因此需要解决哈希冲突的问题,例如使用链表或开放寻址法。
应用场景
适用于需要快速等值查询的场景,例如根据唯一标识(如用户ID)进行数据检索。常见于内存存储的数据库系统中,如 MongoDB、Redis 等,以及一些关系型数据库中,用于加速对特定列的等值查询操作。






![[巅峰极客 2022]smallcontainer](https://img-blog.csdnimg.cn/direct/1e2c38399c2d4032b54a447fda6fee9c.png)