前言
测试的时候就发现不对劲
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_cid_INX` (`name`,`cid`),
KEY `name_INX` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8
随便建了一个student表做测试。
create INDEX name_cid_INX ON student(name,cid);
create INDEX name_INX ON student(name);
建了两个索引,故意这样建的。
执行1:
EXPLAIN SELECT * FROM student WHERE name='小红';

依据mysql索引最左匹配原则,两个索引都匹配上了,这个没有问题。。
执行2:
EXPLAIN SELECT * FROM student WHERE cid=1;

EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';

为什么还能匹配索引。
这是知乎上的一个问题,今天我们就带着这个问题来深入理解一下mysql索引最左匹配原则。
发车
其实我觉得不用刻意的去背最左前缀法则,最重要的是理解复合索引的索引树是如何构建的,理解了符合索引树是如何构建的最左前缀法则自然了然于胸!
直接上图:(我们约定以名字的字母升序排列)
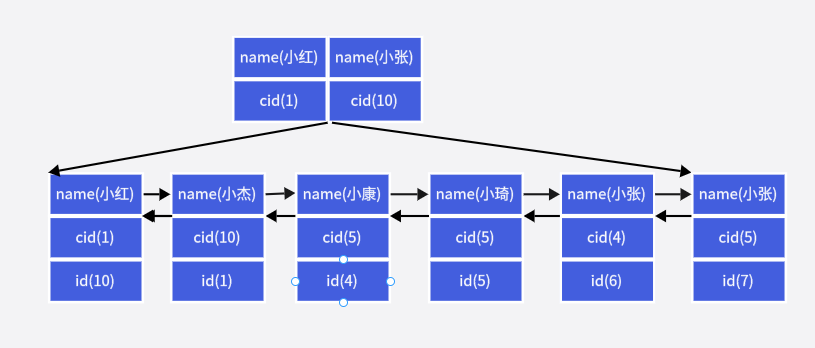
我们就会得到上面这样索引结构(当然树的深度也有可能是别的层数,为了方便理解我就画了两层),我们可以看到这棵树完全是以name的顺序构建的树,只有在name的排序规则不能排的情况下才会用到cid比如树中有两个小张。
当你使用cid去查的时候,他不知道如何取数据,从图中我们也可以看出好多个地方的cid是相同的,这便是最左前缀法则的依据所在!
针对第一句:
EXPLAIN SELECT * FROM student WHERE name='小红';
使用到索引,这个应该我们都能理解,就算不能理解,背八股文也能知道这个必须会用的索引,从图中我们也可以看出
可能使用到的索引有两个,但是最终还是选择了name_cid_INX,思考一下为什么?(后面会讲)
前面我们已经说了,就算不知道为什么会命中索引,我们通过背八股文也能知道他会命中索引,但是不理解纯背诵默写套公式就很累,今天我就来讲解一下为什么会一定命中索引!
首先我们需要知道mysql的索引分为两种,聚簇索引和二级索引,聚簇索引存完整数据记录,二级索引只存索引列和行记录的主键值!
二级索引图如下(约定以字母升序排列):

聚簇索我懒得画了!
从图中我们可以看出,这个所以结构就是以name去排序然后生成的树,所以当你使用name作为查询条件的时候必然就会用到索引!
接着我们继续讲:
EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';
为什么这一句明明我们cid排在前面怎么也会使用到索引呢?
先看图:

一条sql执行会经历这么些个阶段,其中有一个工作的部件叫做“优化器”,这个优化器会调整语法的顺序,
于是乎虽然我们写成了SELECT * FROM student WHERE cid=1 AND name='小红';
他也会把他优化成:SELECT * FROM student WHERE name='小红' and cid=1 ;
这下不就满足了最左前缀法则了嘛,对吧?
其实我们也可以通过mysql的OPTIMIZER_TRACE去证明!
那如何证明呢?
第一步:
set session optimizer_trace="enabled=on", end_markers_in_json=on;
第二步:
SELECT * FROM student WHERE cid=1 AND name='小红';
SELECT * FROM information_schema.OPTIMIZER_TRACE;
注意:这两句要一起执行!不然会出现这种情况:

der都没有!
正常执行以后我们就可以看到完整的执行过程!
文件很长,全部粘贴影响阅读,
我直接粘贴最重要的部分
"condition_processing": {
"condition": "WHERE",
"original_condition": "((`student`.`cid` = 1) and (`student`.`name` = '小红'))",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "((`student`.`name` = '小红') and multiple equal(1, `student`.`cid`))"
},
{
"transformation": "constant_propagation",
"resulting_condition": "((`student`.`name` = '小红') and multiple equal(1, `student`.`cid`))"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "((`student`.`name` = '小红') and multiple equal(1, `student`.`cid`))"
}
] /* steps */
} /* condition_processing */
我们可以看到 "resulting_condition": "((student.name= '小红') and multiple equal(1,student.cid))"
表明已经优化成了SELECT * FROM student WHERE name='小红' and cid=1 ; 所以走了索引!
好好好!
我们接着看这句:
EXPLAIN SELECT * FROM student WHERE cid=1;
为什么这句使用EXPLAIN去分析也会用到索引呢?

啊?
这也用到索引? 你在逗我吗? 我背了那么久的索引最左匹配原则,难道错了吗?
别着急,还有更炸裂的!

我们可以看到possible_keys这一列为空,这一列的意思是“可能用到的索引”,key为实际使用的索引,按照逻辑讲第一个为null
那么第二个也应该为null才对,但是现在却出现了前面为空,后面不为空的情况,这是为啥?
需要理解中这个需要回到我们的表结构去看问题!
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_cid_INX` (`name`,`cid`),
KEY `name_INX` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8
然后name_cid_INX对于应的索引树不就是它吗?
我们再仔细观察一下,这颗索引树不久已经包含这张表的所有字段嘛对吧?
也就是说我们要查询的列不就是直接可以从索引中能返回吗?
这不就是传说中的索引覆盖吗?
这种情况二级索引往往比聚集索引小,所以mysql可能会选择顺序遍历这个二
级索引直接返回,所以才出现了EXPLAIN SELECT * FROM student WHERE cid=1;依然走索引的情况!
这里的本质是产生了索引覆盖!!
OPTIMIZER_TRACE分析工具显示:
{
"considered_execution_plans": [
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`student`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "scan",
"rows": 1,
"cost": 1.2,
"chosen": true
}
] /* considered_access_paths */
} /* best_access_path */,
"cost_for_plan": 1.2,
"rows_for_plan": 1,
"chosen": true
}
] /* considered_execution_plans */
},
诚然OPTIMIZER_TRACE分析工具的"access_type": "scan"确实显示了scan,但它指的是扫描了二级索引树,并不是扫描了整张表!
如果们这时候换另一张表:
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
在这张表中我们构建了一个:idx_name_age_position联合索引,这时候如果们再分析这条sql的执行计划:
EXPLAIN SELECT * FROM employees WHERE age=20
这时候这个查询并不遵守最左前缀法则也不能实现索引覆盖
我们可以看到:

这时候并不会走索引!
我们再改一下: EXPLAIN SELECT id FROM employees WHERE age=20
这时候虽然不遵守最左前缀法则,但是产生了索引覆盖!

我们可以看到,这时候还是走了索引!
我们继续回到开头那个问题:
EXPLAIN SELECT * FROM student WHERE name='小红';
这句sql可能使用到的索引有两个,但是最终还是选择了name_cid_INX,
这便是因为name_cid_INX产生了索引覆盖,不需要再回表,查询效率高所以选择了它!
打完收工!!! 希望对你有帮助!