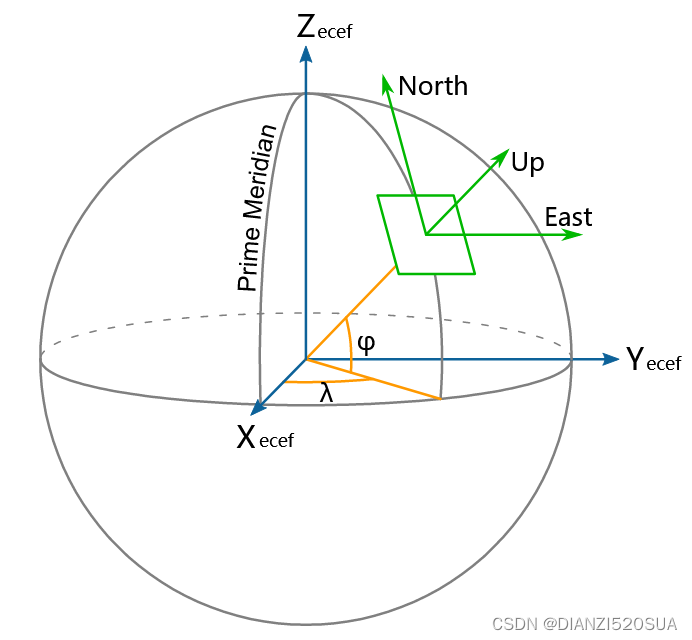
# 读取markdown内容
from langchain_community.document_loaders import UnstructuredPDFLoader
from langchain import document_loaders
# 用到的所有方法
# load_pdf_file_langchain_unstructed # x按照行,无结构化
# load_pdf_file_pypdf # x按照页码,无结构化
# load_pdf_file_MathPix # x需要填写app_id、app_key(公司付费可申请api),可以转成markdown,多级标题,字体大小相似不能识别
# load_pdf_file_unstructed # x按照行或者全文,无结构化
# load_pdf_file_PyPDFium2 # x按照页码,无结构化
# load_pdf_file_PDFMiner # x无结构化,甚至没有分页
# load_pdf_file_html # 需要改进算法
# load_pdf_file_PyPDFDirectory # x无结构化,只是能从文件夹去读取pdf文件,读取结果还是按照页码
# load_pdf_file_AmazonTextractPDFLoader # x无结构话,官方文档只提到提取文本,为提取到提取header或者提取结构
def load_pdf_file_langchain_unstructed(content_path):
loader = loader = UnstructuredPDFLoader(content_path, mode="elements")
data = loader.load()
for page in data:
print('-------------------')
print('content')
print(page.page_content)
print('metadata')
print(page.metadata)
return data
def load_pdf_file_pypdf(content_path):
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(content_path)
pages = loader.load_and_split()
for page in pages:
print('-------------------')
print('content')
print(page.page_content)
print('metadata')
print(page.metadata)
return pages
def load_pdf_file_MathPix(content_path):
from langchain_community.document_loaders import MathpixPDFLoader
loader = MathpixPDFLoader(content_path)
data = loader.load()
for page in data:
print('-------------------')
print('content')
print(page.page_content)
print('metadata')
print(page.metadata)
return data
def load_pdf_file_unstructed(content_path):
from langchain_community.document_loaders import UnstructuredPDFLoader
loader = UnstructuredPDFLoader(content_path, mode="elements")
loader2 = UnstructuredPDFLoader(content_path)
data = loader.load()
for page in data:
print('-------------------')
print('content')
print(page.page_content)
print('metadata')
print(page.metadata)
return data
def load_pdf_file_PyPDFium2(content_path):
from langchain_community.document_loaders import PyPDFium2Loader
loader = PyPDFium2Loader(content_path)
data = loader.load()
for page in data:
print('-------------------')
print('content')
print(page.page_content)
print('metadata')
print(page.metadata)
return data
def load_pdf_file_PDFMiner(content_path):
from langchain_community.document_loaders import PDFMinerLoader
loader = PDFMinerLoader(content_path)
data = loader.load()
for page in data:
print(page.page_content)
print(page.metadata)
return data
def load_pdf_file_html(content_path):
'''
这个函数的逻辑可以分为以下几个步骤:
使用 PDFMinerPDFasHTMLLoader 加载 PDF 文件并将其转换为 HTML 格式。
使用 BeautifulSoup 解析 HTML 内容,并找到所有的 'div' 标签。
遍历所有的 'div' 标签,并从每个标签的 'style' 属性中提取出字体大小('font-size')。
将具有相同字体大小的连续文本片段合并为一个片段,并将这些片段及其对应的字体大小存储在 snippets 列表中。
遍历 snippets 列表,根据每个片段的字体大小将其分类为标题或内容,并将其存储在 semantic_snippets 列表中。具体的分类规则如下:
如果当前片段的字体大小大于前一个片段的标题字体大小,那么将当前片段视为新的标题。
如果当前片段的字体大小小于或等于前一个片段的内容字体大小,那么将当前片段视为前一个片段的内容。
如果当前片段的字体大小大于前一个片段的内容字体大小但小于前一个片段的标题字体大小,那么将当前片段视为新的标题。
返回 semantic_snippets 列表,其中每个元素都是一个 Document 对象,包含一个标题和其对应的内容。
'''
from langchain_community.document_loaders import PDFMinerPDFasHTMLLoader
loader = PDFMinerPDFasHTMLLoader(content_path)
data = loader.load()[0] # entire PDF is loaded as a single Document
from bs4 import BeautifulSoup
soup = BeautifulSoup(data.page_content,'html.parser')
content = soup.find_all('div')
import re
cur_fs = None
cur_text = ''
snippets = [] # first collect all snippets that have the same font size
for c in content:
sp = c.find('span')
if not sp:
continue
st = sp.get('style')
if not st:
continue
fs = re.findall('font-size:(\d+)px',st)
if not fs:
continue
fs = int(fs[0])
if not cur_fs:
cur_fs = fs
if fs == cur_fs:
cur_text += c.text
else:
snippets.append((cur_text,cur_fs))
cur_fs = fs
cur_text = c.text
snippets.append((cur_text,cur_fs))
# Note: The above logic is very straightforward. One can also add more strategies such as removing duplicate snippets (as
# headers/footers in a PDF appear on multiple pages so if we find duplicates it's safe to assume that it is redundant info)
from langchain.docstore.document import Document
cur_idx = -1
semantic_snippets = []
# Assumption: headings have higher font size than their respective content
for s in snippets:
# if current snippet's font size > previous section's heading => it is a new heading
if not semantic_snippets or s[1] > semantic_snippets[cur_idx].metadata['heading_font']:
metadata={'heading':s[0], 'content_font': 0, 'heading_font': s[1]}
metadata.update(data.metadata)
semantic_snippets.append(Document(page_content='',metadata=metadata))
cur_idx += 1
continue
# if current snippet's font size <= previous section's content => content belongs to the same section (one can also create
# a tree like structure for sub sections if needed but that may require some more thinking and may be data specific)
if not semantic_snippets[cur_idx].metadata['content_font'] or s[1] <= semantic_snippets[cur_idx].metadata['content_font']:
semantic_snippets[cur_idx].page_content += s[0]
semantic_snippets[cur_idx].metadata['content_font'] = max(s[1], semantic_snippets[cur_idx].metadata['content_font'])
continue
# if current snippet's font size > previous section's content but less than previous section's heading than also make a new
# section (e.g. title of a PDF will have the highest font size but we don't want it to subsume all sections)
metadata={'heading':s[0], 'content_font': 0, 'heading_font': s[1]}
metadata.update(data.metadata)
semantic_snippets.append(Document(page_content='',metadata=metadata))
cur_idx += 1
return semantic_snippets
def load_pdf_file_PyPDFDirectory(content_path):
from langchain_community.document_loaders import PyPDFDirectoryLoader
loader = PyPDFDirectoryLoader(content_path)
docs = loader.load()
for doc in docs:
print('-------------------')
print('content')
print(doc.page_content)
print('metadata')
print(doc.metadata)
return docs
def load_pdf_file_AmazonTextractPDFLoader(content_path):
from langchain_community.document_loaders import AmazonTextractPDFLoader
loader = AmazonTextractPDFLoader(content_path)
documents = loader.load()
for doc in documents:
print('-------------------')
print('content')
print(doc.page_content)
print('metadata')
print(doc.metadata)
return documents
content_path= r"/home/xinrui/project/xinren-rag-inti/tests/data/测试-导入文本策略.pdf"
Directory_path= r"/home/xinrui/project/xinren-rag-inti/tests/data/"
# load_pdf_file_AmazonTextractPDFLoader(content_path)
参考文件:
langchain_community.document_loaders.pdf.AmazonTextractPDFLoader
How to Extract Data From PDFs Using AWS Textract With Python
Amazon Textract
langchain-pdf