第五章 深度学习
六、PaddlePaddle 图像分类
4. 思路及实现
4.1 数据集介绍
来源:爬虫从百度图片搜索结果爬取
内容:包含 1036 张水果图片,共 5 个类别(苹果 288 张、香蕉 275 张、葡萄 216 张、橙子 276 张、梨 251 张)
图像预处理时,将其中 10%作为测试数据,90%作为训练数据
4.2 总体步骤
数据预处理:建立分类文件,建立训练集、测试集
训练与模型评估
读取测试图片,进行预测
4.3 数据预处理
图片位于 5 个目录,遍历每个目录,将其中 90%写入训练集文件,10%写入测试集文件,文件中记录了图片的路径,用于数据读取器进行读取
生成 3 个文件:readme.json(汇总文件)、trainer.list(训练集)、test.list(测试集)
注意:
- 数据集路径是否正确
- 生成的汇总文件、训练集文件、测试集文件是否正确
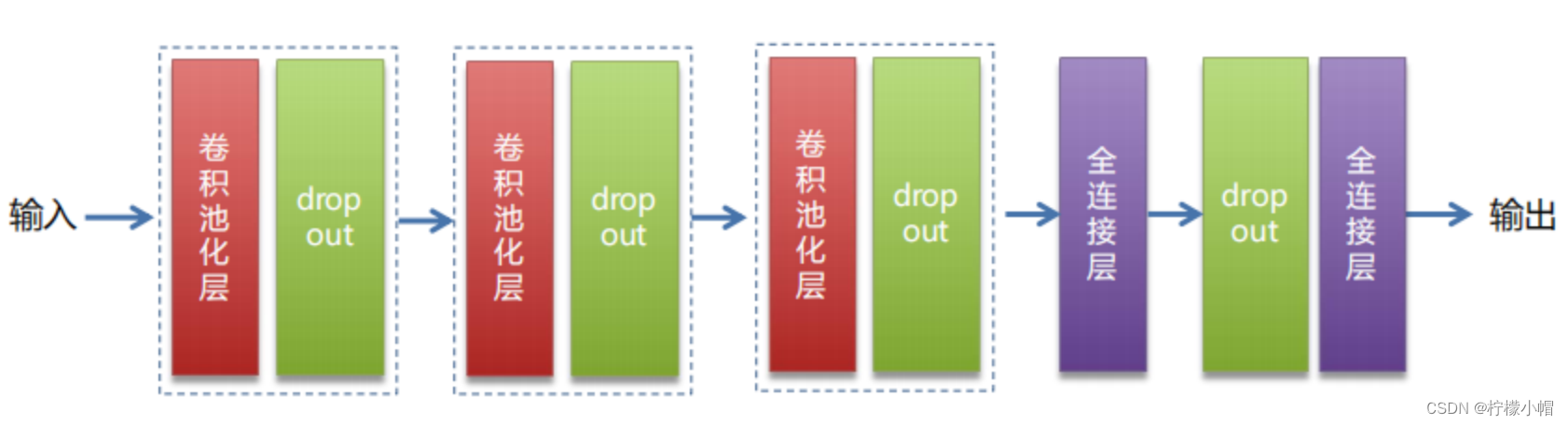
4.4 模型结构
加载模型并预测
4.5 案例 1:利用 CNN 实现图片分类
4.5.1 数据预处理部分
# 利用深层CNN实现水果分类
# 数据集:爬虫从百度图片搜索结果爬取
# 内容:包含1036张水果图片,共5个类别(苹果288张、香蕉275张、葡萄216张、橙子276张、梨251张)
############################# 预处理部分 ################################
import os
name_dict = {"apple":0, "banana":1, "grape":2, "orange":3, "pear":4}
data_root_path = "data/fruits/" # 数据样本所在目录
test_file_path = data_root_path + "test.txt" #测试文件路径
train_file_path = data_root_path + "train.txt" # 训练文件路径
name_data_list = {} # 记录每个类别有哪些图片 key:水果名称 value:图片路径构成的列表
# 将图片路径存入name_data_list字典中
def save_train_test_file(path, name):
if name not in name_data_list: # 该类别水果不在字典中,则新建一个列表插入字典
img_list = []
img_list.append(path) # 将图片路径存入列表
name_data_list[name] = img_list # 将图片列表插入字典
else: # 该类别水果在字典中,直接添加到列表
name_data_list[name].append(path)
# 遍历数据集下面每个子目录,将图片路径写入上面的字典
dirs = os.listdir(data_root_path) # 列出数据集目下所有的文件和子目录
for d in dirs:
full_path = data_root_path + d # 拼完整路径
if os.path.isdir(full_path): # 是一个子目录
imgs = os.listdir(full_path) # 列出子目录中所有的文件
for img in imgs:
save_train_test_file(full_path + "/" + img, #拼图片完整路径
d) # 以子目录名称作为类别名称
else: # 文件
pass
# 将name_data_list字典中的内容写入文件
## 清空训练集和测试集文件
with open(test_file_path, "w") as f:
pass
with open(train_file_path, "w") as f:
pass
# 遍历字典,将字典中的内容写入训练集和测试集
for name, img_list in name_data_list.items():
i = 0
num = len(img_list) # 获取每个类别图片数量
print("%s: %d张" % (name, num))
# 写训练集和测试集
for img in img_list:
if i % 10 == 0: # 每10笔写一笔测试集
with open(test_file_path, "a") as f: #以追加模式打开测试集文件
line = "%s\t%d\n" % (img, name_dict[name]) # 拼一行
f.write(line) # 写入文件
else: # 训练集
with open(train_file_path, "a") as f: #以追加模式打开测试集文件
line = "%s\t%d\n" % (img, name_dict[name]) # 拼一行
f.write(line) # 写入文件
i += 1 # 计数器加1
print("数据预处理完成.")
4.5.2 模型训练与评估
import paddle
import paddle.fluid as fluid
import numpy
import sys
import os
from multiprocessing import cpu_count
import time
import matplotlib.pyplot as plt
def train_mapper(sample):
"""
根据传入的样本数据(一行文本)读取图片数据并返回
:param sample: 元组,格式为(图片路径,类别)
:return:返回图像数据、类别
"""
img, label = sample # img为路径,label为类别
if not os.path.exists(img):
print(img, "图片不存在")
# 读取图片内容
img = paddle.dataset.image.load_image(img)
# 对图片数据进行简单变换,设置成固定大小
img = paddle.dataset.image.simple_transform(im=img, # 原始图像数据
resize_size=128, # 图像要设置的大小
crop_size=128, # 裁剪图像大小
is_color=True, # 彩色图像
is_train=True) # 随机裁剪
# 归一化处理,将每个像素值转换到0~1
img = img.astype("float32") / 255.0
return img, label # 返回图像、类别
# 从训练集中读取数据
def train_r(train_list, buffered_size=1024):
def reader():
with open(train_list, "r") as f:
lines = [line.strip() for line in f] # 读取所有行,并去空格
for line in lines:
# 去掉一行数据的换行符,并按tab键拆分,存入两个变量
img_path, lab = line.replace("\n","").split("\t")
yield img_path, int(lab) # 返回图片路径、类别(整数)
return paddle.reader.xmap_readers(train_mapper, # 将reader读取的数进一步处理
reader, # reader读取到的数据传递给train_mapper
cpu_count(), # 线程数量
buffered_size) # 缓冲区大小
# 搭建CNN函数
# 结构:输入层 --> 卷积/激活/池化/dropout --> 卷积/激活/池化/dropout -->
# 卷积/激活/池化/dropout --> fc --> dropout --> fc(softmax)
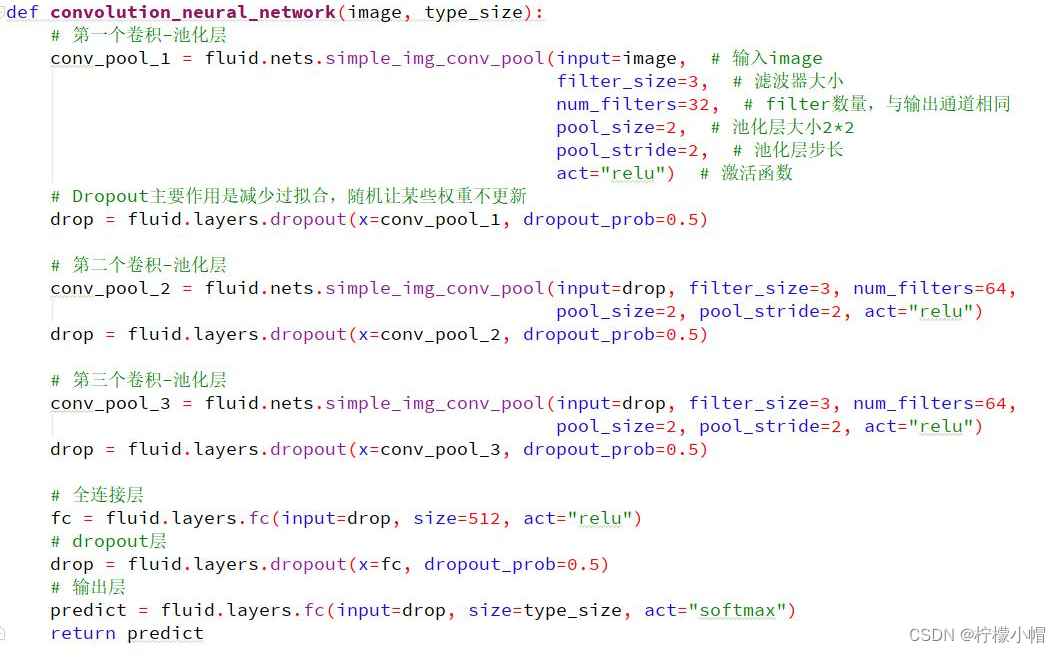
def convolution_neural_network(image, type_size):
"""
创建CNN
:param image: 图像数据
:param type_size: 输出类别数量
:return: 分类概率
"""
# 第一组 卷积/激活/池化/dropout
conv_pool_1 = fluid.nets.simple_img_conv_pool(input=image, # 原始图像数据
filter_size=3, # 卷积核大小
num_filters=32, # 卷积核数量
pool_size=2, # 2*2区域池化
pool_stride=2, # 池化步长值
act="relu")#激活函数
drop = fluid.layers.dropout(x=conv_pool_1, dropout_prob=0.5)
# 第二组
conv_pool_2 = fluid.nets.simple_img_conv_pool(input=drop, # 以上一个drop输出作为输入
filter_size=3, # 卷积核大小
num_filters=64, # 卷积核数量
pool_size=2, # 2*2区域池化
pool_stride=2, # 池化步长值
act="relu")#激活函数
drop = fluid.layers.dropout(x=conv_pool_2, dropout_prob=0.5)
# 第三组
conv_pool_3 = fluid.nets.simple_img_conv_pool(input=drop, # 以上一个drop输出作为输入
filter_size=3, # 卷积核大小
num_filters=64, # 卷积核数量
pool_size=2, # 2*2区域池化
pool_stride=2, # 池化步长值
act="relu")#激活函数
drop = fluid.layers.dropout(x=conv_pool_3, dropout_prob=0.5)
# 全连接层
fc = fluid.layers.fc(input=drop, size=512, act="relu")
# dropout
drop = fluid.layers.dropout(x=fc, dropout_prob=0.5)
# 输出层(fc)
predict = fluid.layers.fc(input=drop, # 输入
size=type_size, # 输出值的个数(5个类别)
act="softmax") # 输出层采用softmax作为激活函数
return predict
# 定义reader
BATCH_SIZE = 32 # 批次大小
trainer_reader = train_r(train_list=train_file_path) #原始reader
random_train_reader = paddle.reader.shuffle(reader=trainer_reader,
buf_size=1300) # 包装成随机读取器
batch_train_reader = paddle.batch(random_train_reader,
batch_size=BATCH_SIZE) # 批量读取器
# 变量
image = fluid.layers.data(name="image", shape=[3, 128, 128], dtype="float32")
label = fluid.layers.data(name="label", shape=[1], dtype="int64")
# 调用函数,创建CNN
predict = convolution_neural_network(image=image, type_size=5)
# 损失函数:交叉熵
cost = fluid.layers.cross_entropy(input=predict, # 预测结果
label=label) # 真实结果
avg_cost = fluid.layers.mean(cost)
# 计算准确率
accuracy = fluid.layers.accuracy(input=predict, # 预测结果
label=label) # 真实结果
# 优化器
optimizer = fluid.optimizer.Adam(learning_rate=0.001)
optimizer.minimize(avg_cost) # 将损失函数值优化到最小
# 执行器
# place = fluid.CPUPlace()
place = fluid.CUDAPlace(0) # GPU训练
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
# feeder
feeder = fluid.DataFeeder(feed_list=[image, label], # 指定要喂入数据
place=place)
model_save_dir = "model/fruits/" # 模型保存路径
costs = [] # 记录损失值
accs = [] # 记录准确度
times = 0
batches = [] # 迭代次数
# 开始训练
for pass_id in range(40):
train_cost = 0 # 临时变量,记录每次训练的损失值
for batch_id, data in enumerate(batch_train_reader()): # 循环读取样本,执行训练
times += 1
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data), # 喂入参数
fetch_list=[avg_cost, accuracy])# 获取损失值、准确率
if batch_id % 20 == 0:
print("pass_id:%d, step:%d, cost:%f, acc:%f" %
(pass_id, batch_id, train_cost[0], train_acc[0]))
accs.append(train_acc[0]) # 记录准确率
costs.append(train_cost[0]) # 记录损失值
batches.append(times) # 记录迭代次数
# 训练结束后,保存模型
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
fluid.io.save_inference_model(dirname=model_save_dir,
feeded_var_names=["image"],
target_vars=[predict],
executor=exe)
print("训练保存模型完成!")
# 训练过程可视化
plt.title("training", fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(batches, costs, color='red', label="Training Cost")
plt.plot(batches, accs, color='green', label="Training Acc")
plt.legend()
plt.grid()
plt.savefig("train.png")
plt.show()
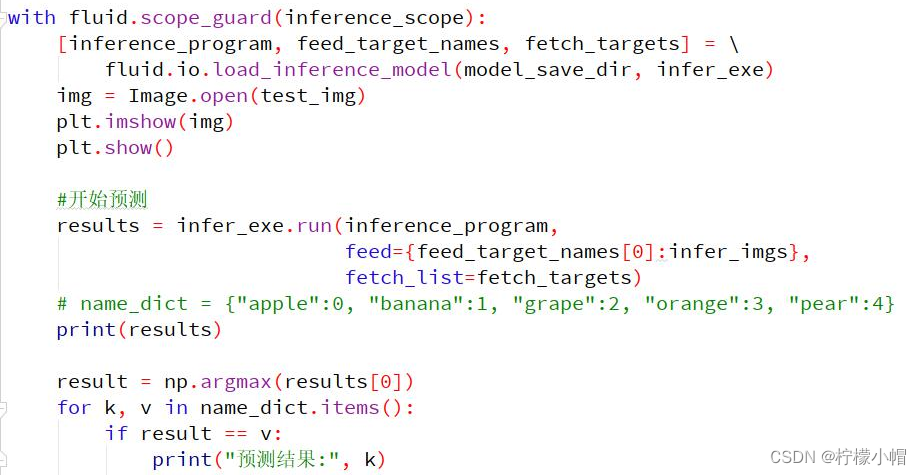
4.5.3 预测
from PIL import Image
# 定义执行器
place = fluid.CPUPlace()
infer_exe = fluid.Executor(place)
model_save_dir = "model/fruits/" # 模型保存路径
# 加载数据
def load_img(path):
img = paddle.dataset.image.load_and_transform(path, 128, 128, False).astype("float32")
img = img / 255.0
return img
infer_imgs = [] # 存放要预测图像数据
test_img = "./data/grape_1.png" #待预测图片
infer_imgs.append(load_img(test_img)) #加载图片,并且将图片数据添加到待预测列表
infer_imgs = numpy.array(infer_imgs) # 转换成数组
# 加载模型
infer_program, feed_target_names, fetch_targets = \
fluid.io.load_inference_model(model_save_dir, infer_exe)
# 执行预测
results = infer_exe.run(infer_program, # 执行预测program
feed={feed_target_names[0]: infer_imgs}, # 传入待预测图像数据
fetch_list=fetch_targets) #返回结果
print(results)
result = numpy.argmax(results[0]) # 取出预测结果中概率最大的元素索引值
for k, v in name_dict.items(): # 将类别由数字转换为名称
if result == v: # 如果预测结果等于v, 打印出名称
print("预测结果:", k) # 打印出名称
# 显示待预测的图片
img = Image.open(test_img)
plt.imshow(img)
plt.show()
5. 图像分类优化手段
5.1 样本优化
增大样本数量
数据增强
- 形态变化:翻转、平移、随机修剪、尺度变换、旋转
- 色彩变化:色彩抖动(错位的位移对图像产生的一种特殊效果)、图像白化(将图像本身归一化成 Gaussian(0,1) 分布)
- 加入噪声:噪声扰动
5.2 参数优化
丢弃学习:按照一定比率丢弃神经元输出
权重衰减:通过为模型损失函数添加惩罚项使得训练的模型参数较小
批量正则化:在网络的每一层输入之前增加归一化处理,使输入的均值为 0,标准差为 1。目的是将数据限制在统一的分布下
变化学习率:学习率由固定调整为变化,例如由固定 0.001 调整为 0.1, 0.001, 0.0005
加深网络:加深网络可能提高准确率,也可能降低准确率,视具体情况而定
5.3 模型优化
更换更复杂、精度更高的网络模型。如由简单 CNN 更换为 VGG、GooLeNet、ResNet
5.4 利用 VGG 实现图像分类
在水果识别案例第二部分(模型搭建部分)增加如下代码:
# 创建VGG模型
def vgg_bn_drop(image, type_size):
def conv_block(ipt, num_filter, groups, dropouts):
# 创建Convolution2d, BatchNorm, DropOut, Pool2d组
return fluid.nets.img_conv_group(input=ipt, # 输入图像像,[N,C,H,W]格式
pool_stride=2, # 池化步长值
pool_size=2, # 池化区域大小
conv_num_filter=[num_filter] * groups, #卷积核数量
conv_filter_size=3, # 卷积核大小
conv_act="relu", # 激活函数
conv_with_batchnorm=True,#是否使用batch normal
pool_type="max") # 池化类型
conv1 = conv_block(image, 64, 2, [0.0, 0]) # 最后一个参数个数和组数量相对应
conv2 = conv_block(conv1, 128, 2, [0.0, 0])
conv3 = conv_block(conv2, 256, 3, [0.0, 0.0, 0.0])
conv4 = conv_block(conv3, 512, 3, [0.0, 0.0, 0.0])
conv5 = conv_block(conv4, 512, 3, [0.0, 0.0, 0.0])
drop = fluid.layers.dropout(x=conv5, dropout_prob=0.2) # 待调整
fc1 = fluid.layers.fc(input=drop, size=512, act=None)
bn = fluid.layers.batch_norm(input=fc1, act="relu") # batch normal
drop2 = fluid.layers.dropout(x=bn, dropout_prob=0.0)
fc2 = fluid.layers.fc(input=drop2, size=512, act=None)
predict = fluid.layers.fc(input=fc2, size=type_size, act="softmax")
return predict
将创建网络部分改为以下代码即可:
# 调用上面的函数创建VGG
predict = vgg_bn_drop(image=image, type_size=5) # type_size和水果类别一致