宇宙厂实际是字节,这个称呼是因为字节跳动主宰了宇宙内一切App,有点家大业大的意思。
今天分享一位字节春招凉经,问了一些数据库和Java八股,没出算法题,直接挂了,竟然最喜欢出算法题的字节,这次面试竟然没出算法题。
八股问题不算很多,简单给大家罗列了一下,也针对每一个问题给出解析,大家可以边复习边查漏补缺。

数据库
数据库日志有哪些?分别有什么用?
-
undo log(回滚日志):是 Innodb 存储引擎层生成的日志,实现了事务中的原子性,主要用于事务回滚和 MVCC。
-
redo log(重做日志):是 Innodb 存储引擎层生成的日志,实现了事务中的持久性,主要用于掉电等故障恢复;
-
binlog (归档日志):是 Server 层生成的日志,主要用于数据备份和主从复制;
Redis数据结构有哪些?应用场景是什么?
Redis 提供了丰富的数据类型,常见的有五种数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
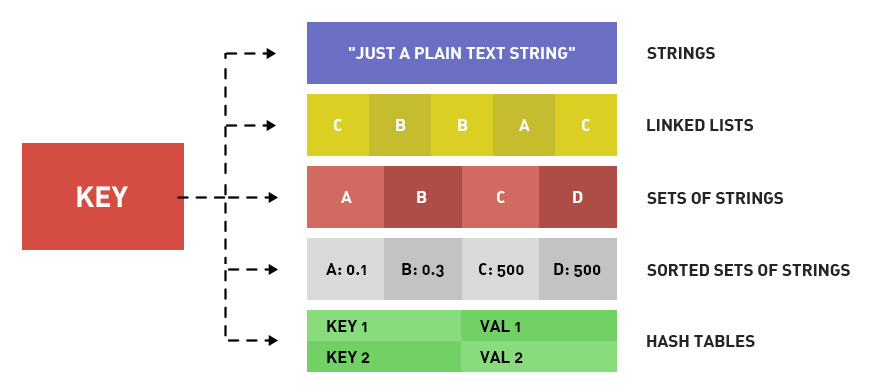
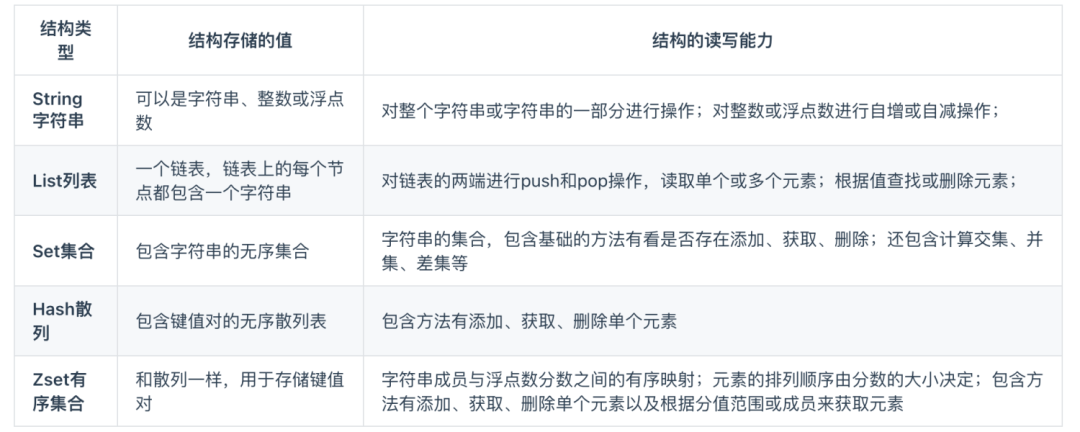
随着 Redis 版本的更新,后面又支持了四种数据类型:BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO(3.2 版新增)、Stream(5.0 版新增)。Redis 五种数据类型的应用场景:
-
String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
-
List 类型的应用场景:消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
-
Hash 类型:缓存对象、购物车等。
-
Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
-
Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
Redis 后续版本又支持四种数据类型,它们的应用场景如下:
-
BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
-
HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
-
GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
-
Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
redis中的zset底层数据结构是怎么实现的?
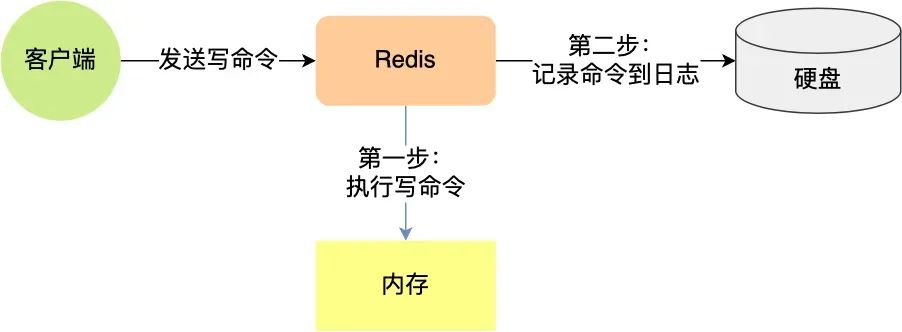
redis持久化的方式有哪些?
Redis 的读写操作都是在内存中,所以 Redis 性能才会高,但是当 Redis 重启后,内存中的数据就会丢失,那为了保证内存中的数据不会丢失,Redis 实现了数据持久化的机制,这个机制会把数据存储到磁盘,这样在 Redis 重启就能够从磁盘中恢复原有的数据。
Redis 持久化的方式有两种:
-
AOF 日志:每执行一条写操作命令,就把该命令以追加的方式写入到一个文件里;
-
RDB 快照:将某一时刻的内存数据,以二进制的方式写入磁盘;
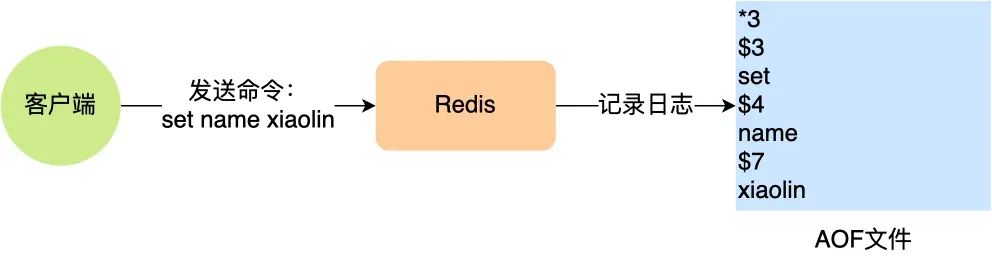
AOF 日志是如何实现的?
Redis 在执行完一条写操作命令后,就会把该命令以追加的方式写入到一个文件里,然后 Redis 重启时,会读取该文件记录的命令,然后逐一执行命令的方式来进行数据恢复。
我这里以「_set name xiaolin_」命令作为例子,Redis 执行了这条命令后,记录在 AOF 日志里的内容如下图:
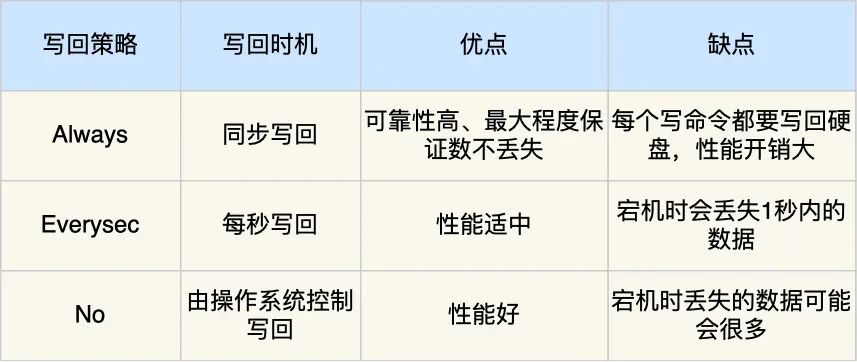
Redis 提供了 3 种写回硬盘的策略, 在 Redis.conf 配置文件中的 appendfsync 配置项可以有以下 3 种参数可填:
-
Always,这个单词的意思是「总是」,所以它的意思是每次写操作命令执行完后,同步将 AOF 日志数据写回硬盘;
-
Everysec,这个单词的意思是「每秒」,所以它的意思是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;
-
No,意味着不由 Redis 控制写回硬盘的时机,转交给操作系统控制写回的时机,也就是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回硬盘。
我也把这 3 个写回策略的优缺点总结成了一张表格:
RDB 快照是如何实现的呢?
因为 AOF 日志记录的是操作命令,不是实际的数据,所以用 AOF 方法做故障恢复时,需要全量把日志都执行一遍,一旦 AOF 日志非常多,势必会造成 Redis 的恢复操作缓慢。
为了解决这个问题,Redis 增加了 RDB 快照。所谓的快照,就是记录某一个瞬间东西,比如当我们给风景拍照时,那一个瞬间的画面和信息就记录到了一张照片。
所以,RDB 快照就是记录某一个瞬间的内存数据,记录的是实际数据,而 AOF 文件记录的是命令操作的日志,而不是实际的数据。
因此在 Redis 恢复数据时, RDB 恢复数据的效率会比 AOF 高些,因为直接将 RDB 文件读入内存就可以,不需要像 AOF 那样还需要额外执行操作命令的步骤才能恢复数据。
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave,他们的区别就在于是否在「主线程」里执行:
-
执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程;
-
执行了 bgsave 命令,会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞;
Redis为什么快?
原因:
-
Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构,因此 Redis 瓶颈可能是机器的内存或者网络带宽,而并非 CPU,既然 CPU 不是瓶颈,那么自然就采用单线程的解决方案了;
-
Redis 采用单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题。
-
Redis 采用了 I/O 多路复用机制处理大量的客户端 Socket 请求,IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听 Socket 和已连接 Socket。内核会一直监听这些 Socket 上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
Java
Java怎么获取数据库字段?
可以使用JDBC来获取数据库字段。通过执行SQL查询语句,可以从数据库中检索所需的字段数据。以下是一个简单的示例代码:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class Main {
public static void main(String[] args) {
try {
// 连接数据库
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydatabase", "username", "password");
// 创建Statement对象
Statement stmt = conn.createStatement();
// 执行查询语句
ResultSet rs = stmt.executeQuery("SELECT column1, column2 FROM mytable");
// 遍历结果集
while (rs.next()) {
String value1 = rs.getString("column1");
String value2 = rs.getString("column2");
// 处理获取到的字段数据
System.out.println("Value1: " + value1 + ", Value2: " + value2);
}
// 关闭连接
rs.close();
stmt.close();
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
在上面的代码中,首先建立数据库连接,然后创建Statement对象执行查询语句,通过ResultSet对象获取数据库字段的值,并进行处理。最后记得关闭连接以释放资源。
说一下你知道的创建线程的方式
方式一:继承Thread类并重写run()方法。
public class CreatingThread01 extends Thread {
@Override
public void run() {
System.out.println(getName() + " is running");
}
public static void main(String[] args) {
new CreatingThread01().start();
new CreatingThread01().start();
new CreatingThread01().start();
new CreatingThread01().start();
}
}
采用继承Thread类方式
-
优点: 编写简单,如果需要访问当前线程,无需使用Thread.currentThread ()方法,直接使用this,即可获得当前线程
-
缺点:因为线程类已经继承了Thread类,所以不能再继承其他的父类
方式二:实现Runnable接口并实现run()方法,然后将实现了Runnable接口的类传递给Thread类。
public class CreatingThread02 implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " is running");
}
public static void main(String[] args) {
new Thread(new CreatingThread02()).start();
new Thread(new CreatingThread02()).start();
new Thread(new CreatingThread02()).start();
new Thread(new CreatingThread02()).start();
}
}
采用实现Runnable接口方式:
-
优点:线程类只是实现了Runable接口,还可以继承其他的类。在这种方式下,可以多个线程共享同一个目标对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
-
缺点:编程稍微复杂,如果需要访问当前线程,必须使用Thread.currentThread()方法。
方式三:使用Callable和Future接口通过Executor框架创建线程。
public class CreatingThread03 implements Callable<Long> {
@Override
public Long call() throws Exception {
Thread.sleep(2000);
System.out.println(Thread.currentThread().getId() + " is running");
return Thread.currentThread().getId();
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Long> task = new FutureTask<>(new CreatingThread03());
new Thread(task).start();
System.out.println("等待完成任务");
Long result = task.get();
System.out.println("任务结果:" + result);
}
}
采用实现Callable接口方式:
-
缺点:编程稍微复杂,如果需要访问当前线程,必须调用Thread.currentThread()方法。
-
优点:线程只是实现Runnable或实现Callable接口,还可以继承其他类。这种方式下,多个线程可以共享一个target对象,非常适合多线程处理同一份资源的情形。
介绍一下线程池工作原理
线程池是为了减少频繁的创建线程和销毁线程带来的性能损耗。
线程池分为核心线程池,线程池的最大容量,还有等待任务的队列,提交一个任务,如果核心线程没有满,就创建一个线程,如果满了,就是会加入等待队列,如果等待队列满了,就会增加线程,如果达到最大线程数量,如果都达到最大线程数量,就会按照一些丢弃的策略进行处理。
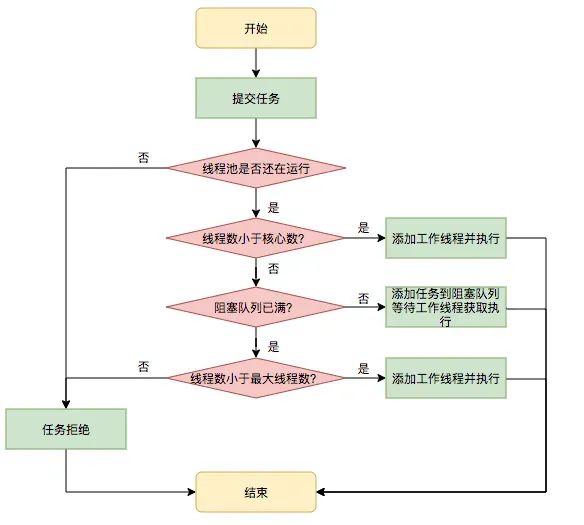
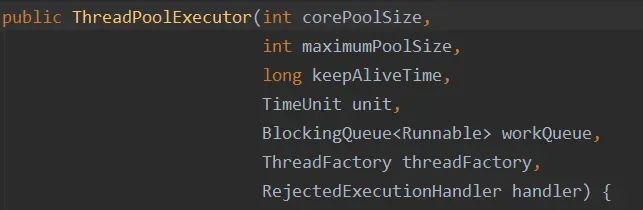
线程池的构造函数有7个参数:
-
corePoolSize:线程池核心线程数量。默认情况下,线程池中线程的数量如果 <= corePoolSize,那么即使这些线程处于空闲状态,那也不会被销毁。
-
maximumPoolSize:线程池中最多可容纳的线程数量。当一个新任务交给线程池,如果此时线程池中有空闲的线程,就会直接执行,如果没有空闲的线程且当前线程池的线程数量小于corePoolSize,就会创建新的线程来执行任务,否则就会将该任务加入到阻塞队列中,如果阻塞队列满了,就会创建一个新线程,从阻塞队列头部取出一个任务来执行,并将新任务加入到阻塞队列末尾。如果当前线程池中线程的数量等于maximumPoolSize,就不会创建新线程,就会去执行拒绝策略。
-
keepAliveTime:当线程池中线程的数量大于corePoolSize,并且某个线程的空闲时间超过了keepAliveTime,那么这个线程就会被销毁。
-
unit:就是keepAliveTime时间的单位。
-
workQueue:工作队列。当没有空闲的线程执行新任务时,该任务就会被放入工作队列中,等待执行。
-
threadFactory:线程工厂。可以用来给线程取名字等等
-
handler:拒绝策略。当一个新任务交给线程池,如果此时线程池中有空闲的线程,就会直接执行,如果没有空闲的线程,就会将该任务加入到阻塞队列中,如果阻塞队列满了,就会创建一个新线程,从阻塞队列头部取出一个任务来执行,并将新任务加入到阻塞队列末尾。如果当前线程池中线程的数量等于maximumPoolSize,就不会创建新线程,就会去执行拒绝策略。
线程的状态有哪些?
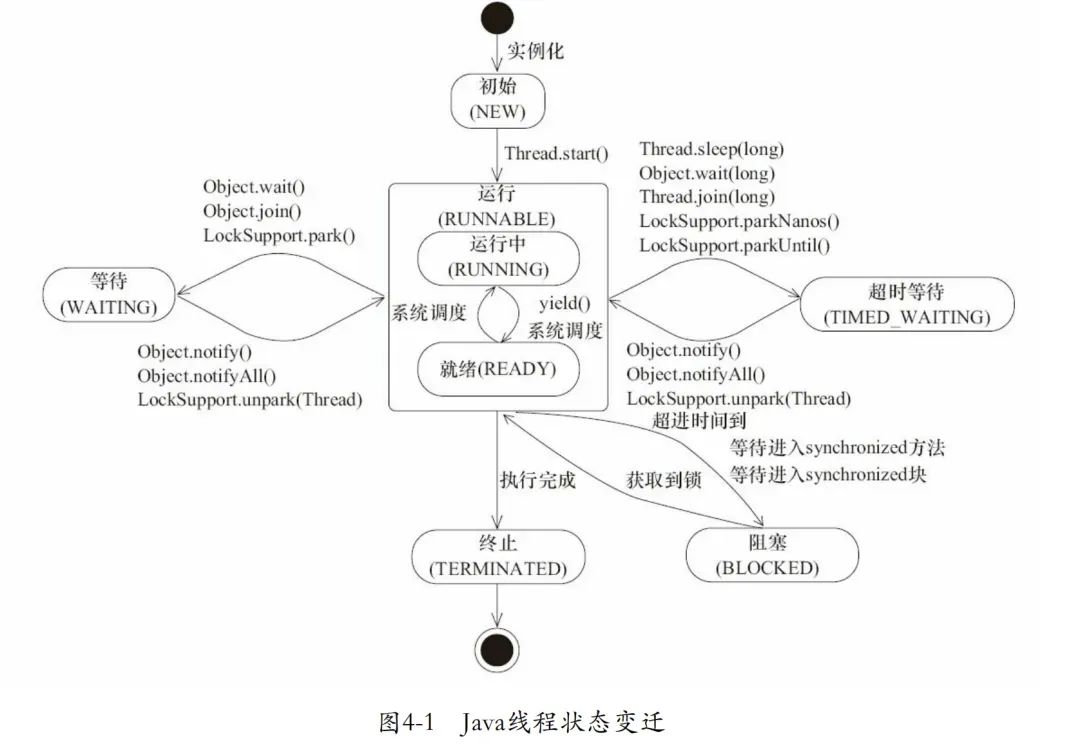
源自《Java并发编程艺术》 java.lang.Thread.State枚举类中定义了六种线程的状态,可以调用线程Thread中的getState()方法获取当前线程的状态。
| 线程状态 | 解释 |
|---|---|
| NEW | 尚未启动的线程状态,即线程创建,还未调用start方法 |
| RUNNABLE | 就绪状态(调用start,等待调度)+正在运行 |
| BLOCKED | 等待监视器锁时,陷入阻塞状态 |
| WAITING | 等待状态的线程正在等待另一线程执行特定的操作(如notify) |
| TIMED_WAITING | 具有指定等待时间的等待状态 |
| TERMINATED | 线程完成执行,终止状态 |
线程池中shutdown (),shutdownNow()这两个方法有什么作用?
从源码【高亮】注释可以很清晰的看出两者的区别:
-
shutdown使用了以后会置状态为SHUTDOWN,正在执行的任务会继续执行下去,没有被执行的则中断。此时,则不能再往线程池中添加任何任务,否则将会抛出 RejectedExecutionException 异常
-
而 shutdownNow 为STOP,并试图停止所有正在执行的线程,不再处理还在池队列中等待的任务,当然,它会返回那些未执行的任务。它试图终止线程的方法是通过调用 Thread.interrupt() 方法来实现的,但是这种方法的作用有限,如果线程中没有sleep 、wait、Condition、定时锁等应用, interrupt()方法是无法中断当前的线程的。所以,ShutdownNow()并不代表线程池就一定立即就能退出,它可能必须要等待所有正在执行的任务都执行完成了才能退出。
shutdown 源码:
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 高亮
advanceRunState(SHUTDOWN);
interruptIdleWorkers();
onShutdown();
} finally {
mainLock.unlock();
}
tryTerminate();
}
shutdownNow 源码:
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 高亮
advanceRunState(STOP);
interruptWorkers();
// 高亮
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
// 高亮
return tasks;
}
提交给线程池中的任务可以被撤回吗?
可以,当向线程池提交任务时,会得到一个Future对象。这个Future对象提供了几种方法来管理任务的执行,包括取消任务。
取消任务的主要方法是Future接口中的cancel(boolean mayInterruptIfRunning)方法。这个方法尝试取消执行的任务。参数mayInterruptIfRunning指示是否允许中断正在执行的任务。如果设置为true,则表示如果任务已经开始执行,那么允许中断任务;如果设置为false,任务已经开始执行则不会被中断。
public interface Future<V> {
// 是否取消线程的执行
boolean cancel(boolean mayInterruptIfRunning);
// 线程是否被取消
boolean isCancelled();
//线程是否执行完毕
boolean isDone();
// 立即获得线程返回的结果
V get() throws InterruptedException, ExecutionException;
// 延时时间后再获得线程返回的结果
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
取消线程池中任务的方式,代码如下,通过 future 对象的 cancel(boolean) 函数来定向取消特定的任务。
public static void main(String[] args) {
ExecutorService service = Executors.newSingleThreadExecutor();
Future future = service.submit(new TheradDemo());
try {
// 可能抛出异常
future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}finally {
//终止任务的执行
future.cancel(true);
}
}
怎么判断对象是否可以被回收?
垃圾收集器在做垃圾回收的时候,首先需要判定的就是哪些内存是需要被回收的,哪些对象是「存活」的,是不可以被回收的;哪些对象已经「死掉」了,需要被回收。一般有两种方法来判断:
-
引用计数器法:为每个对象创建一个引用计数,有对象引用时计数器 +1,引用被释放时计数 -1,当计数器为 0 时就可以被回收。它有一个缺点不能解决循环引用的问题;
-
可达性分析算法:从 GC Roots 开始向下搜索,搜索所走过的路径称为引用链。当一个对象到 GC Roots 没有任何引用链相连时,则证明此对象是可以被回收的。
你知道哪些垃圾收集器?
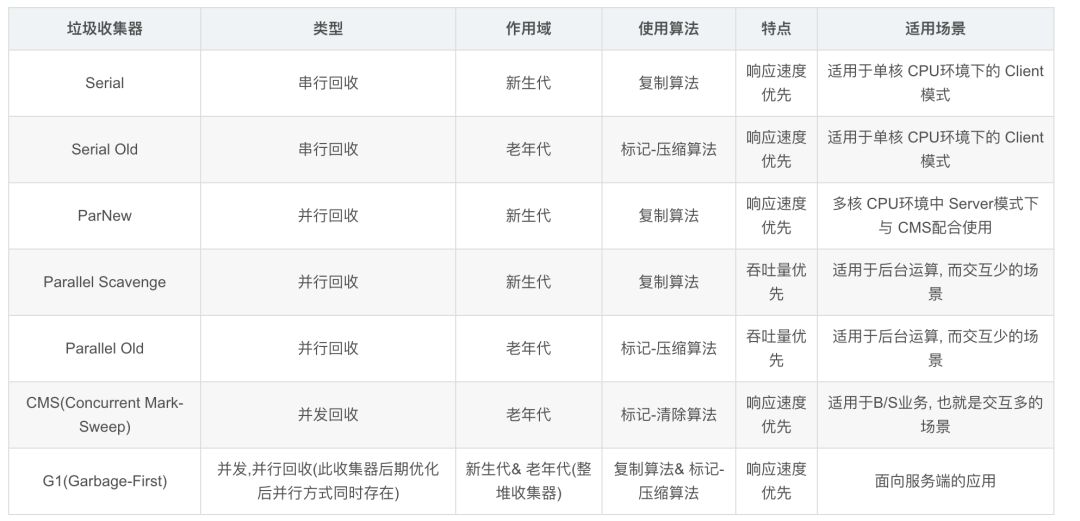
-
Serial收集器(复制算法): 新生代单线程收集器,标记和清理都是单线程,优点是简单高效;
-
ParNew收集器 (复制算法): 新生代收并行集器,实际上是Serial收集器的多线程版本,在多核CPU环境下有着比Serial更好的表现;
-
Parallel Scavenge收集器 (复制算法): 新生代并行收集器,追求高吞吐量,高效利用 CPU。吞吐量 = 用户线程时间/(用户线程时间+GC线程时间),高吞吐量可以高效率的利用CPU时间,尽快完成程序的运算任务,适合后台应用等对交互相应要求不高的场景;
-
Serial Old收集器 (标记-整理算法): 老年代单线程收集器,Serial收集器的老年代版本;
-
Parallel Old收集器 (标记-整理算法):老年代并行收集器,吞吐量优先,Parallel Scavenge收集器的老年代版本;
-
CMS(Concurrent Mark Sweep)收集器(标记-清除算法):老年代并行收集器,以获取最短回收停顿时间为目标的收集器,具有高并发、低停顿的特点,追求最短GC回收停顿时间。
-
G1(Garbage First)收集器 (标记-整理算法):Java堆并行收集器,G1收集器是JDK1.7提供的一个新收集器,G1收集器基于“标记-整理”算法实现,也就是说不会产生内存碎片。此外,G1收集器不同于之前的收集器的一个重要特点是:G1回收的范围是整个Java堆(包括新生代,老年代),而前六种收集器回收的范围仅限于新生代或老年代
说一下你对 Spring 的理解
-
IoC容器(Inversion of Control):Spring通过控制反转实现了对象的创建和对象间的依赖关系管理。开发者只需要定义好Bean及其依赖关系,Spring容器负责创建和组装这些对象。
-
AOP(Aspect-Oriented Programming):面向切面编程,允许开发者定义横切关注点(cross-cutting concerns),例如事务管理、安全控制等,独立于业务逻辑的代码。通过AOP,可以将这些关注点模块化,提高代码的可维护性和可重用性。
-
事务管理:Spring提供了一致的事务管理接口,支持声明式和编程式事务。开发者可以轻松地进行事务管理,而无需关心具体的事务API。
-
MVC框架:Spring MVC是一个基于Servlet API构建的Web框架,采用了模型-视图-控制器(MVC)架构。它支持灵活的URL到页面控制器的映射,以及多种视图技术。
Spring框架核心特性包括:
-
IoC容器(Inversion of Control):Spring通过控制反转实现了对象的创建和对象间的依赖关系管理。开发者只需要定义好Bean及其依赖关系,Spring容器负责创建和组装这些对象。
-
AOP(Aspect-Oriented Programming):面向切面编程,允许开发者定义横切关注点(cross-cutting concerns),例如事务管理、安全控制等,独立于业务逻辑的代码。通过AOP,可以将这些关注点模块化,提高代码的可维护性和可重用性。
-
事务管理:Spring提供了一致的事务管理接口,支持声明式和编程式事务。开发者可以轻松地进行事务管理,而无需关心具体的事务API。
-
MVC框架:Spring MVC是一个基于Servlet API构建的Web框架,采用了模型-视图-控制器(MVC)架构。它支持灵活的URL到页面控制器的映射,以及多种视图技术。
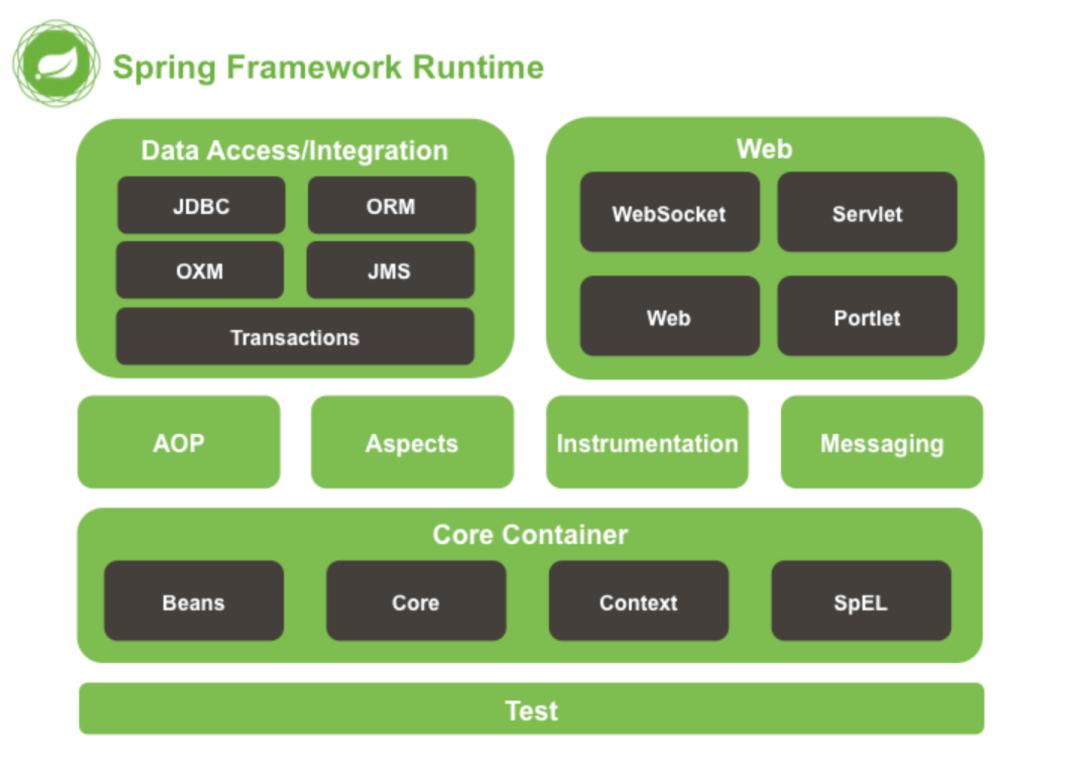
Spring框架核心特性包括:
-
IoC容器:Spring通过控制反转实现了对象的创建和对象间的依赖关系管理。开发者只需要定义好Bean及其依赖关系,Spring容器负责创建和组装这些对象。
-
AOP:面向切面编程,允许开发者定义横切关注点,例如事务管理、安全控制等,独立于业务逻辑的代码。通过AOP,可以将这些关注点模块化,提高代码的可维护性和可重用性。
-
事务管理:Spring提供了一致的事务管理接口,支持声明式和编程式事务。开发者可以轻松地进行事务管理,而无需关心具体的事务API。
-
MVC框架:Spring MVC是一个基于Servlet API构建的Web框架,采用了模型-视图-控制器(MVC)架构。它支持灵活的URL到页面控制器的映射,以及多种视图技术。
Spring AOP的实现依赖于动态代理技术。动态代理是在运行时动态生成代理对象,而不是在编译时。它允许开发者在运行时指定要代理的接口和行为,从而实现在不修改源码的情况下增强方法的功能。Spring AOP支持两种动态代理:
-
基于JDK的动态代理:使用
java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口实现。这种方式需要代理的类实现一个或多个接口。 -
基于CGLIB的动态代理:当被代理的类没有实现接口时,Spring会使用CGLIB库生成一个被代理类的子类作为代理。CGLIB(Code Generation Library)是一个第三方代码生成库,通过继承方式实现代理。