目录
- 1.解决过拟合的方法
- 2. regularization
- 2. regularization分类
- 3. pytorch L2 regularization
- 4. 自实现L1 regularization
- 5. 完整代码
1.解决过拟合的方法
- 更多的数据
- 降低模型复杂度
regularization - Dropout
- 数据处理
- 早停止
2. regularization
以二分类的cross entropy为例,就是在其公式后增加一项参数一范数累加和,并乘以一个超参数用来权衡参数配比。
模型优化是要使得前部分loss尽量小,那么同时也要后半部分范数接近于0,但是为了保持模型的表达能力还要保留比如
β
0
β_{0}
β0+
β
1
β_{1}
β1x+
β
2
β_{2}
β2
x
2
x^2
x2,那么可能使得
β
0
β_{0}
β0、
β
2
β_{2}
β2、
β
3
β_{3}
β3 = 0.01 而
β
4
β_{4}
β4-
β
n
β_{n}
βn很小很小,比如0.0001,这样就使得比如f(x)=
x
7
x^7
x7,退化为
β
0
β_{0}
β0+
β
1
β_{1}
β1x+
β
2
β_{2}
β2
x
2
x^2
x2,这样即保证了模型的表达能力,也降低了模型的复杂度。从而防止过拟合。

下图是未增加regularization和增加了regularization的区别展示图
可以看出未增加regularization的时候,模型可以将噪点也拟合进去了,因此图形很不平滑,发生了过拟合。而增加regularization之后,图形变得很平滑。

2. regularization分类
regularization有两类分别是L1和L2,L1增加的是参数的一范数,L2增加的二范数

最常用的是L2regularization
3. pytorch L2 regularization
pytorch中L2 regularization叫weight_decay

4. 自实现L1 regularization
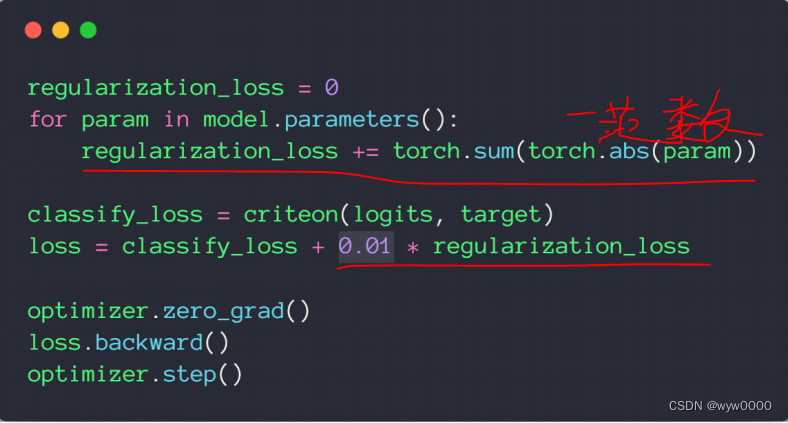
5. 完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdom
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.01)
criteon = nn.CrossEntropyLoss().to(device)
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.',
legend=['loss', 'acc.']))
global_step = 0
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
global_step += 1
viz.line([loss.item()], [global_step], win='train_loss', update='append')
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.argmax(dim=1)
correct += pred.eq(target).float().sum().item()
viz.line([[test_loss, correct / len(test_loader.dataset)]],
[global_step], win='test', update='append')
viz.images(data.view(-1, 1, 28, 28), win='x')
viz.text(str(pred.detach().cpu().numpy()), win='pred',
opts=dict(title='pred'))
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))