7、体系结构分类
1、按处理机的数量进行分类:
单处理系统(一个处理单元和其他设备集成)、
并行处理系统(两个以上的处理机互联)、
分布式处理系统(物理上远距离且耦合的多计算机系统)
2、Flynn分类法:(考点)
分类有两个因素,即指令流和数据流。
**指令流由控制部分处理,**每一个控制部分处理一条指令流,多指令流就由多个控制部分;
数据流由处理器来处理,每一个处理器处理一条数据流,多数据流就有多个处理器;
至于主存模块,是用来存储的,存储指令流或者数据流,因此,无论是多指令流还是多数据流,都需要多个主存模块来存储,对于主存模块,指令和数据都一样。
3、依据计算机特性
依据计算机特性,是由指令来控制数据的传输,因此,一条指令可以控制一条或多条数据流,但一条数据流不能被多条指令控制,否则会出错,就如同上级命令太多还互相冲突,不知道该执行哪个,因此多指令单数据 MISD不可能。

8、存储系统
1、Cache

计算机采用分级存储体系的主要目的是为了解决存储容量、成本和速度之间的矛盾问题。
两级存储:Cache-主存,主存-辅存(虚拟存储体系)。
**局部性原理:**总的来说,在CPU运行时,所访问的数据会趋向于一个较小的局部空间地址内,包括下面两个方面:
- 时间局部性原理:如果一个数据项正在被访问,那么在近期它很可能会再次访问,即在相邻的时间里会访问同一个数据项。
- 空间局部性原理:在最近的将来会用到的数据的地址和现在正在访问的数据地址很可能是相近的,即**相邻的空间地址会被连续访问。**比如 for 循环。
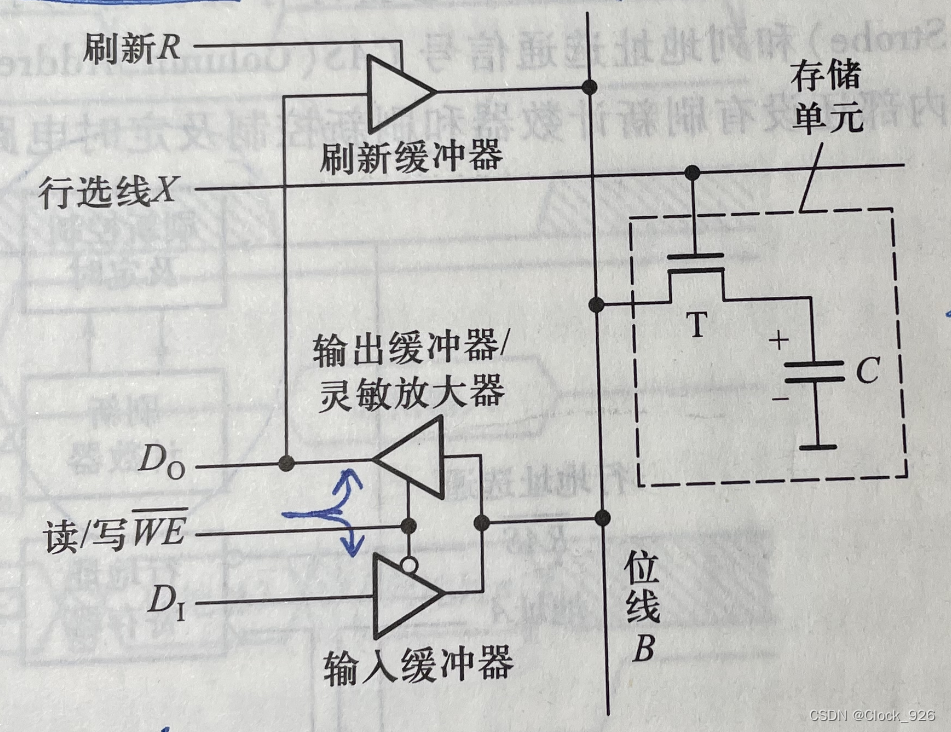
高速缓存Cache 用来存储当前最活跃的程序和数据,直接与CPU交互,位于CPU和主存之间,容量小,速度为内存的5-10倍,由半导体材料构成。其内容是主存内存的副本拷贝,对于程序员来说是透明的(透明不可见)
Cache 由控制部分和存储器组成,存储器存储数据,控制部分判断CPU要访问的数据是否在Cache中,在则命中,不在则依据一定的算法从主存中替换。
地址映射:在CPU工作时,送出的是主存单元的地址,而应从Cache存储器中读/写信息。这就需要将主存地址转换为Cache存储器地址,这种地址的转换称为地址映像,由硬件自动完成映射,分为下列三种方法:
这三种方法(了解即可):


Cache 地址映像块冲突概率从高到低:直接映像、组相联映像、全相联映像
替换算法的目标就是**使Cache获得尽可能高的命中率。**常用算法有如下几种:
(1)随机替换算法。就是使用随机数发生器产生一个要替换的块号,将该块替换出去。
(2)先进先出算法。就是将最先进入Cache的信息块替换出去。
(3)近期最少使用方法。(目前最常用),这种方法是将近期最少使用的Cache中的信息块替换出去。
(4)**优化替换算法。**这种方法必须先执行一段程序,统计Cache的替换情况。有了这样的先验信息,在第二次执行该程序时便可以用最有效的方式来替换。
命中率及平均时间:
Cache有一个命中率的概念,即当CPU所访问的数据在Cache中时,命中,直接从Cache中读取数据,设读取一次Cache时间为1ns,若CPU访问的数据不在Cache中,则需要从内存中读取,设读取一次Cache时间为1ns,若CPU访问的数据**不在Cache中,则需要从内存中读取,**设读取一次内存的时间为1000ns,若在CPU多次读取数据的过程中,有90%命中Cache,则CPU读取一次的平均时间为(90% * 1 + 10% * 1000)ns
容量越大,命中率越高(Cache 3MB,主存/内存 8GB,如果 Cache 容量大到 8GB,则可以完全将内存的东西拷贝过来,自然就100%访问 Cache 了。)

基本概念:K、M、G 是数量单位,在存储器里相差 1024倍。b,B是存储单位,1B = 8b。
真题:地址编号从80000H到BFFFFH且按字节编址的内存容量为()KB,若用16K*4bit的存储器芯片构成该内存,共需()片
特别提醒:不要硬算,要化简为2的幂指数来算。
16进展:A(10)、B(11)、C(12)、D(13)、E(14)、F(15)
(BFFFF - 80000) + 1 = 3FFFF + 1 = 40000H
按字节编址:每个存储到单元室1个字节,即1B
1KB = 1024B
1B = 8b
40000H = 4 * 164(10进制) = 218 B
218 B / 1024B = 218 B / 210 = 28KB = 256KB
16K*4bit = 16K * 0.5B = 8KB
256KB/8KB = 32 片
2、磁盘结构和参数、磁盘调度
磁盘有正反两个盘面,每个盘面有多个同心圆,每个同心圆是一个磁道,每个同心圆又被划分为多个扇区,数据就被存放在一个个扇区中。(磁盘是在旋转的,每分钟多少转,比如7200转每秒)
磁头首先要寻找到对应的磁道,然后等待磁盘进行周期旋转,旋转到指定的扇区,才能读取到对应的数据,因此,会产生寻道时间和等待时间。
公式为:存取时间= 寻道时间+等待时间(平均定位时间+转动延迟)。
注意:寻道时间是指磁头移动到磁道所需的时间;等待时间为等待读写的扇区转到磁头下方所用的时间。
磁盘数据的读取时间分为寻道时间+旋转时间,也即先找到对应的磁道,而后旋转到对应的扇区才能读取数据,其中寻道时间耗时最长,需要重点调度,有如下调度算法:
**先来先服务FCFS:**根据进程请求访问磁盘的先后顺序进行调度
**最短寻道时间优先SSTF:**请求访问的磁道与当前磁道最近的进程优先调度,使得每次的寻道时间最短。会产生“饥饿”现象,即远处进程可能永远无法访问。(比如当前在磁道5,相较于磁道8,他会先去磁道3,因为(5 - 3 < 8 - 5),去了磁道3,再判断离的最近的磁道,只跟距离有关,与方向无关)
**扫描算法SCAN:**又称“电梯算法”,磁头在磁盘上双向移动,其会选择离磁头当前所在磁道最近的请求访问磁道,并且与磁头方向一致,磁头永远都是从里向外或者从外向里一直移动完才掉头,与电梯相似。(即5-》6-》7-》1-》2-》3-》4)
**单向扫描调度算法CSCAN:**与SCAN不同的是,其只做单向移动,即只能从里向外或从外向里。(即:1-》2-》3-》4-》5-》6-》7-》6-》6-》4-》3-》2-》1-》…)

33ms 转一圈,11个物理块即11扇区,
33 / 11 = 3ms,即每3ms可以读取一个扇区(只要转过去,就读过去了)
每读一个3ms,处理一个也是3ms。
所以刚开始时:读R0用了3ms,处理也用了3ms,即R0读完处理完用了6ms,而每个扇区读取是3ms(磁头指向),所以6ms时,此时磁头指向的事 R2,因为要按顺序处理,所以需要转到 R1时,才能继续读取和处理。所以要等待转动一圈到 R1。而从 R2 转到 R1,需要 R3、R4、R5、R6、R7、R8、R9、R10、R0、R1 共计10个,即 3 * 10 = 30ms
所以:3 + 3(R0处理) + (10 * 3 + 3 + 3)* 10= 366ms
10 * 3 是等待 30ms 才能回到 R1,3 + 3 是 3ms 读取 R1,3ms 处理 R1,后续的 R2、R3… R10 都是如此,所以乘以 10。
读 3,处理 3,(3 + 3) * 11 = 66,正好6秒时转到下一个,即读、即处理。


21 柱面/磁道距离 23柱面/磁道最近,然后确定扇区,扇区是按照顺序的即3 4 6,或6 4 3 (即顺时针或逆时针)
所以是:②⑧③
23 结束后就是 17,扇区按照顺序则是 ⑤,此时①和⑦的扇区号都是⑨,(可以顺时针 从小到大 也可以逆时针 从大到小),所以此时可以是 ⑤⑦①或⑤①⑦,
所以答案是 D。