Java 安装
下载JDK
查看Linux 服务区的操作系统位数,下载适合的JKD安装包
[root@master ~]# getconf LONG_BIT
64
下载jdk-8u361
解压安装JDK
tar -zxvf jdk-8u361-linux-x64.tar.gz -C /usr/local
添加JAVA 环境变量
执行命令 vi ~/.bash_profile 在~/.bash_profile文件中增加Java环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_361
export JAVA_BIN=$JAVA_HOME/bin
export JAVA_LIB=$JAVA_HOME/lib
export CLASSPATH=.:$JAVA_LIB/tools.jar:$JAVA_LIB/dt.jar
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$JAVA_BIN
export PATH
最后 source ~/.bash_profile
验证JAVA是否安装成功
[root@master src]# java -version
java version "1.8.0_361"
Java(TM) SE Runtime Environment (build 1.8.0_361-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.361-b09, mixed mode)
修改host
[root@master ~]# vim /etc/hosts
## 在文件末尾添加一行
127.0.0.1 hadoop001
创建hadoop 用户
useradd hadoop
给普通用户设置超级管理的权限
/etc/sudoers文件默认情况下是只读的,若要修改它需要为其添加写权限,使用命令 chmod u+w /etc/sudoers
chmod u+w /etc/sudoers
编辑/etc/sudoers, 在 root ALL=(ALL) ALL 这一行下面添加一行
## 为 hadoop 用户添加 sudo 权限,sudo 时需要键入密码
hadoop ALL=(ALL) ALL:
修改完毕,保存文件,取消掉 /etc/sudoers 的写权限
chmod u-w /etc/sudoers
Hadoop 安装[单机版]
Hadoop 下载
hadoop-3.2.3
Hadoop 安装
tar -zxvf hadoop-3.2.3.tar.gz -C /usr/local/
添加Hadoop 环境变量
vim ~/.bash_profile
export HADOOP_HOME=/usr/local/hadoop-3.2.3
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$JAVA_BIN:`$HADOOP_HOME/bin:$HADOOP_HOME/sbin`
修改hadoop 配置
配置目录 $HADOOP_HOME/etc/hadoop
hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_361
export HADOOP_HOME=/usr/local/hadoop-3.2.3
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
<description>The runtime framework for executing MapReduce jobs</description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.3</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.3</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.3</value>
</property>
</configuration>
core-site.xml
| 参数 | 值 |
|---|---|
| fs.default.name | NameNode的IP地址及端口 |
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop001:9001</value>
</property>
</configuration>
hdfs-site.xml
| 参数 | 值 |
|---|---|
| dfs.namenode.name.dir | NameNode 存储名字空间及汇报日志的位置 |
| dfs.datanode.data.dir | DataNode 存储数据块的位置 |
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/dfs/datanode</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<final>true</final>
</property>
</configuration>
启动Hadoop
格式化NameNode
第一次启动HDFS需要先进行格式化
hdfs namenode -format
启动NameNode && 启动DataNode
hdfs --daemon start namenode
hdfs --daemon start datanode
jps
bash-4.2$ jps
11526 NameNode
11643 DataNode
11679 Jps
如果启动失败,可以查看%HADOOP_HOME%/logs/ 目录下的日志进行错误排查
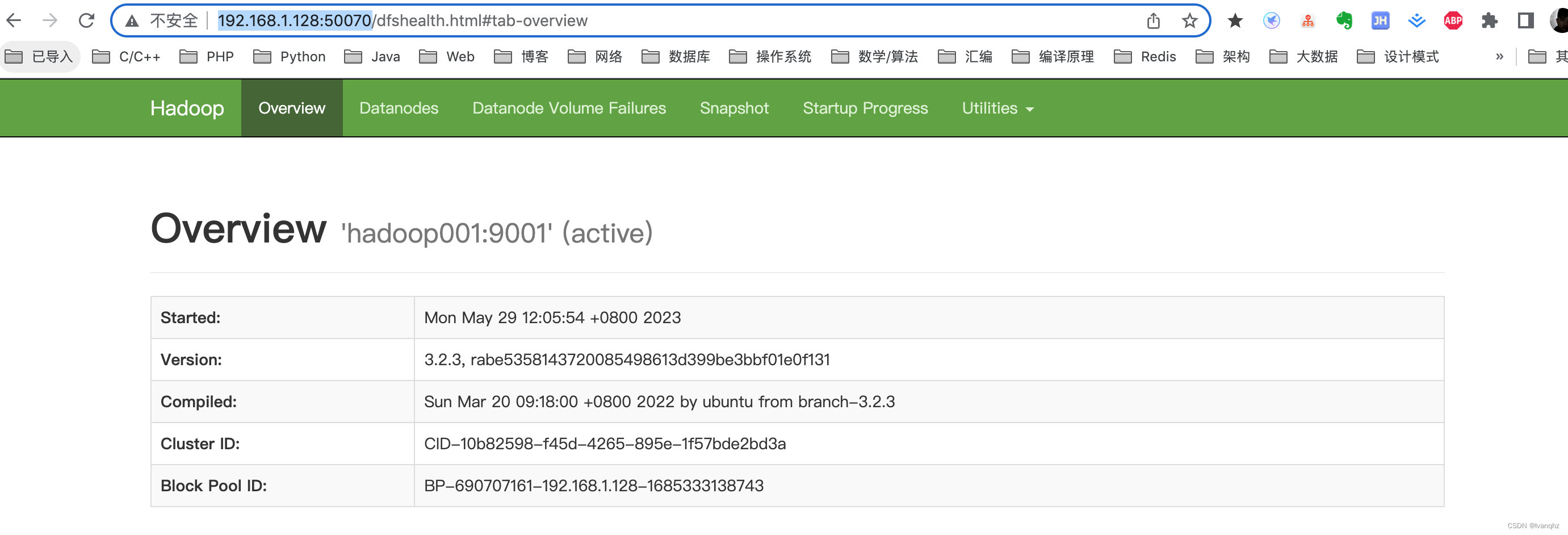
访问HDFS的管理界面
输入 http://192.168.1.128:50070/
本机SSH免密码登录配置
关闭防火墙和SELinux(root权限)
永久有效
修改 /etc/selinux/config 文件中的 SELINUX=enforcing 修改为 SELINUX=disabled ,然后重启
临时生效
setenforce 0
配置sshd(root权限)
编辑 /etc/ssh/sshd_config 文件,使用命令:vi /etc/ssh/sshd_config ,去掉以下3行的 “#” 注释
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
重启 sshd 服务,使用命令:systemctl restart sshd.service
生成秘钥(普通用户权限)
从 root 用户切换到hadoop 用户. 执行命令 ssh-keygen -t rsa 来生成秘钥
将公钥导入到认证文件(普通用户权限
cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys
设置认证文件访问权限(普通用户权限
chmod 700 /home/hadoop/.ssh
chmod 600 /home/hadoop/.ssh/authorized_keys
启动Yarn
bash-4.2$ start-yarn.sh
Starting resourcemanager
resourcemanager is running as process 13040. Stop it first and ensure /tmp/hadoop-hadoop-resourcemanager.pid file is empty before retry.
Starting nodemanagers
bash-4.2$ jps
13040 ResourceManager
13731 Jps
12824 NameNode
12687 DataNode
13583 NodeManager
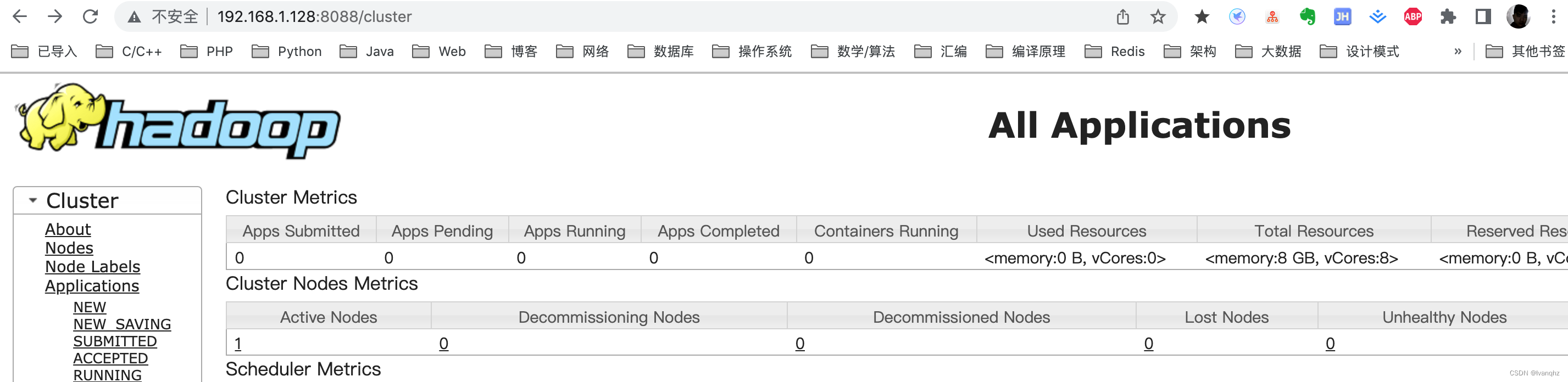
查看YARN的管理界面
MapReduce测试
bash-4.2$ hdfs dfs -mkdir /input # 在HDFS根目录下创建input目录
bash-4.2$ hdfs dfs -mkdir /output # 在HDFS根目录下创建output目录
bash-4.2$ hdfs dfs -ls / # 查看HDFS根目录下文件列表
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2023-05-29 16:30 /input
drwxr-xr-x - hadoop supergroup 0 2023-05-29 16:30 /output
其他命令
hdfs dfs -put src out # 文件夹上传
hdfs dfs -get src out # 文件夹下载
hdfs dfs -cat # 文件查看
hdfs dfs -rm -r # 删除
Spark 安装[单机版]
Spark 下载
spark-3.0.0-without-hadoop
解压安装
# 解压安装包并移动到/usr/local/下
sudo tar -zxvf spark-3.0.0-bin-without-hadoop.tgz
sudo mv ./spark-3.0.0-bin-without-hadoop/ /usr/local/spark
环境配置
sudo vim /etc/profile
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
配置 ${SPARK_HOME}/conf/spark-env.sh 文件关联 spark-without-hadoop 和 hadoop【非without版本无需配置】
bash-4.2$ sudo cp spark-env.sh.template spark-env.sh
bash-4.2$ vim spark-env.sh
# 添加以下内容
# 实际就是执行时在 CLASSPATH 中加入 Hadoop 的 Jar 包 【要根据Hadoop的安装路径配置】
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop-3.2.3/bin/hadoop classpath)
Local模式
Local 模式是最简单的一种运行方式,它采用单节点多线程方式运行,适合日常测试开发使用
bash-4.2$ spark-shell --master local[*]
- local:只启动一个工作线程
- local[k]:启动 k 个工作线程
- local[*]:启动跟 cpu 数目相同的工作线程数

spark 测试
进入 spark-shell 后,程序已经自动创建好了上下文 SparkContext ,等效于执行了下面的 Scala 代码
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
val conf = new SparkConf().setAppName("Spark shell").setMaster("local[*]")
val sc = new SparkContext(conf)
准备一个词频统计的文件样本 word.txt
hadoop,spark,hive
spark,hive,hbase,kafka
hadoop,hive,spark
执行如下 Scala 语句
sc
.textFile("file:///home/spark/testFile/word.txt")
.flatMap(_.split(","))
.map((_, 1))
.reduceByKey(_ + _)
.saveAsTextFile("file:///home/spark/testFile/wordCount")
词频统计的结果
[root@master wordCount]# cat /home/spark/testFile/wordCount/part-00000
(hive,3)
(kafka,1)
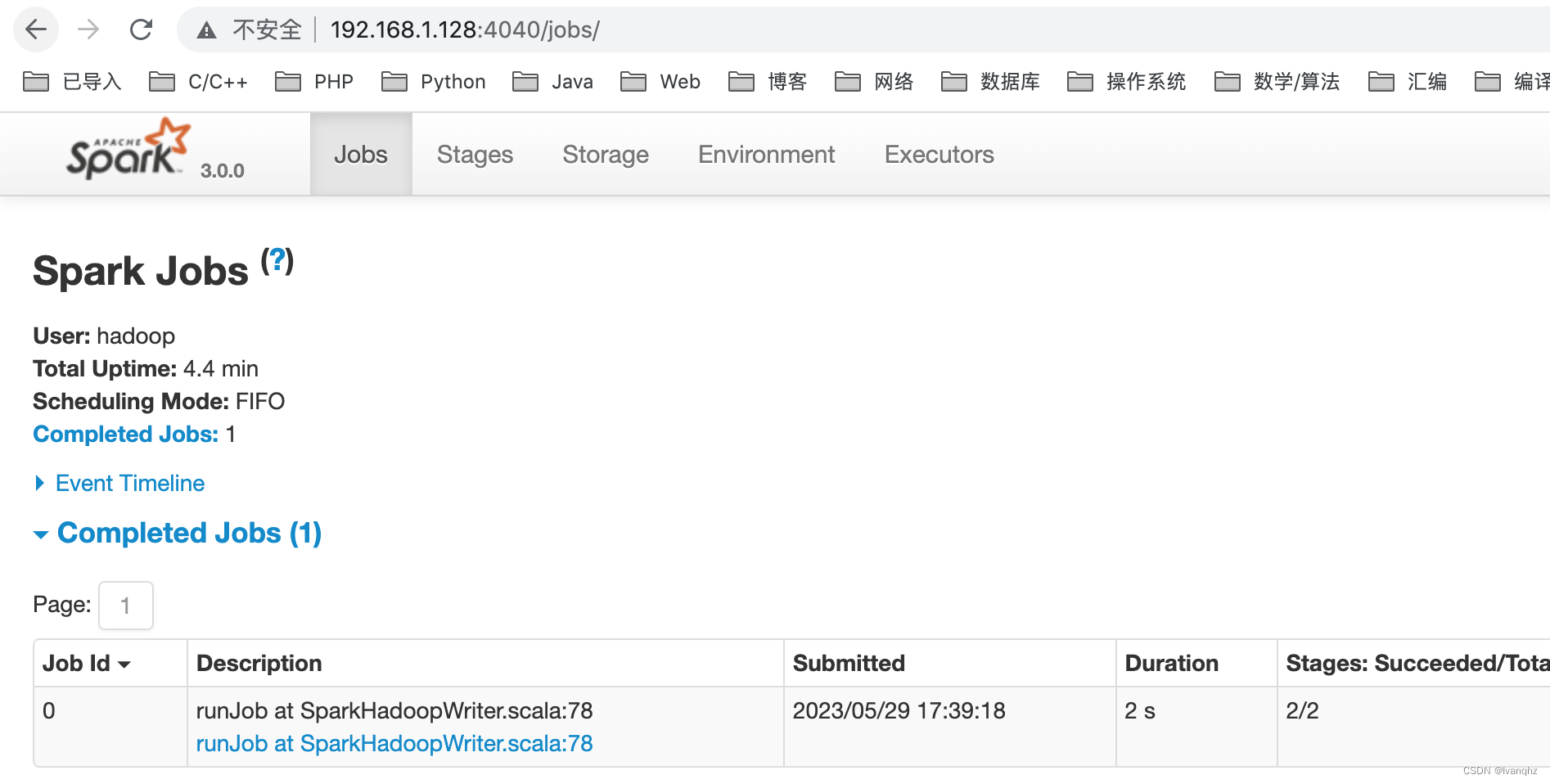
通过 Web UI 查看作业的执行情况, 访问端口为 4040
参考资料
- CentOS7下Hadoop3.2.1的安装与部署(单机模式)
- Spark【环境搭建 01】spark-3.0.0-without 单机版