目录
一、部署
1.1 容量规划
1.2 基础环境配置
1.3 机器配置
1.3.1 FE节点
1.3.2 BE节点
1.4 部署方案
二、建模
2.1 建表规范
2.2 模型选择
2.3 排序列和前缀索引选择
2.4 分区选择
2.5 分桶选择
2.6 字段类型
2.7 索引选择
2.7.1 Bitmap索引
2.7.2 Bloom filter索引
三、数据导入
3.1 使用建议
3.2 数据生命周期
四、数据查询
4.1 高并发场景
4.2 数据精度
4.3 SQL 查询
4.4 使用物化视图加速查询
4.4.1 bitmap_union精确去重
4.4.2异步物化视图最多支持3层嵌套
4.5 利用Cache加速查询
五、监控
文章介绍StarRocks在行业的最佳实践经验,包括部署、建模、导入、查询和监控五个模块。
一、部署
1.1 容量规划
【建议】参考StarRocks集群配置推荐做容量规划,具体参考:StarRocks集群配置推荐 - 经验教程 - StarRocks中文社区论坛
1.2 基础环境配置
【必须】参考检查环境配置,尤其关注 swap 关闭、overcommit 设置为1、ulimit 配置合理等。具体参考:检查环境配置 | StarRocks
1.3 机器配置
1.3.1 FE节点
- 【建议】 8C32GB;
- 【必须】数据盘>=200GB,建议 SSD;
1.3.2 BE节点
- 【建议】CPU:内存比,1:4,生产最小配置必须是 8C32GB+
- 【建议】单节点磁盘容量建议 10TB,数据盘建议最大单盘 2TB,建议 SSD 或者 NVME(如果是 HDD,建议吞吐>150MB/s,IOPS>500)
- 【建议】集群中节点同构(机器规格一样,避免木桶效应)
1.4 部署方案
- 【必须】生产环境必须最小集群规模3FE+3BE(建议FE和BE独立部署),如果混合部署,必须配置be.conf中的mem_limit 为减去其他服务后剩余内存量,例如机器内存40G,上面已经部署了FE,理论上限会用8G,那么配置下mem_limit=34G(40-8-2),2G作为系统预留。
- 【必须】生产必须FE高可用部署,1Leader+2Follower,如果需要提高读并发,可以扩容 Observer 节点。
- 【必须】生产必须使用负载均衡器连接集群进行读写,一般常用 Nginx、Haproxy、F5 等
二、建模
2.1 建表规范
- 仅支持UTF8编码;
- 不支持修改表中的列名;
- VARCHAR最大长度 1048576;
- KEY列不能使用FLOAT、DOUBLE 类型;
- 数据目录名,数据库名,表名,视图名,用户名,角色名大小写敏感,列名和分区名大小写不敏感;
- 主键模型中,主键长度不能超过128字节;
2.2 模型选择
- 如果想要保留明细,建议使用明细模型;
- 如果有明确主键,主键非空,写少读多,非主键列要利用索引,建议使用主键模型;
- 如果有明确主键,主键可能为空,写多读少,建议使用更新模型;
- 如果只想保留聚合数据,建议使用聚合模型;
2.3 排序列和前缀索引选择
duplicate key、aggregate key、unique key 中指定的列,StarRocks3.0 以前版本,主键模型中排序列通过 primary key 指定,StarRocks3.0 以后版本,主键模型中排序列通过 order by指定。
由于StarRocks底层数据是按照排序键排序后存储的,而前缀索引是在key (duplicate key、aggregate key、unique key、primary key)排序的基础上,实现的一种根据给定一定数量(不超过3列,不超过36个字节,遇到字符串会自动截断)前缀列,每间隔一定行数(1024),生成的一个索引项 (稀疏索引)。当查询的过滤条件命中前缀索引时,就能快速定位到数据存储所在的比较精确地址,在使用前缀索引时需注意:
- 经常作为查询条件的列,建议选为排序列,例如经常用user_id 过滤,where user_id=234,可以把 user_id 放在第一列;
- 排序列建议选择3-5列,过多会增大排序开销,降低导入效率;
- 前缀索引不超过36字节,不能超过3列,遇到 VARCHAR 会截断,前缀索引中不能包含 FLOAT 或 DOUBLE 类型的列;
因此可以结合实际业务查询场景,在确定Key列以及字段顺序时,要充分考虑前缀索引带来的优势。尽可能将经常需要查询的Key列字段,放置在前面,字段数据类型尽量选择date日期类型或者int等整数类型。
前缀索引的详细介绍见:
Doris存储层设计介绍1——存储结构设计解析(索引底层结构)_doris底层结构-CSDN博客
举例:
CREATE TABLE site_access
(
site_id BIGINT DEFAULT '10',
city_code INT,
site_name VARCHAR(50),
pv BIGINT DEFAULT '0'
)
DUPLICATE KEY(site_id,city_code,site_name)
DISTRIBUTED BY HASH(site_id);在 site_access 表中,前缀索引为 site_id( 8 Bytes ) + city_code( 4 Bytes ) + site_name(前 24 Bytes)
-
如果查询条件只包含
site_id和city_code两列,如下所示,则可以大幅减少查询过程中需要扫描的数据行:
select sum(pv) from site_access where site_id = 123 and city_code = 2;-
如果查询条件只包含
site_id一列,如下所示,可以定位到只包含site_id的数据行:
select sum(pv) from site_access where site_id = 123;-
如果查询条件只包含
city_code一列,则需要扫描所有数据行,排序效果大打折扣:
select sum(pv) from site_access where city_code = 2;反面案例:
CREATE TABLE site_access_bad
(
site_name VARCHAR(20),
site_id BIGINT DEFAULT '10',
city_code INT,
pv BIGINT DEFAULT '0'
)
PRIMARY KEY(site_id)
DISTRIBUTED BY HASH(site_id)
ORDER BY(site_id,city_code);
## 在site_access_bad表中前缀索引只有site_name2.4 分区选择
- 【建议】值不会变化的时间列经常用于 WHERE 过滤,使用该列创建分区;
- 【建议】有数据淘汰需求的场景建议选择动态分区;
- 【必须】数据更新有明显的冷热特征的,必须创建分区,例如经常更新最近一周的数据,可以按天分区;
- 【必须】单个分区数据量必须不能超过100GB;
- 【必须】超过50G或者5KW的表建议创建分区;
- 【建议】按需创建分区,不需要提前创建大量空分区,避免元数据太多占用FE的内存;
- 当前支持时间类型(Range 分区、表达式分区)、字符串(List 分区)、数字(Range 分区、List 分区);
- 默认最大支持1024个分区,可以通过参数调整,但是一般情况下不需要调整;
2.5 分桶选择
(1)生产必须使用3副本;
(2)分桶个数判断;
- 【必须】单个桶按照1GB预估,原始数据按照10GB(导入StarRocks后,压缩比 7:1 ~ 10:1)预估;
- 当按照以上策略估算出来的分桶个数小于 BE 个数的时候,最终分桶个数以 BE 个数为准,例如6个BE节点,按照1GB每个桶预估分桶个数为1,最终分桶个数取6;
- 【必须】非分区表不要使用动态分桶,按照实际数据量估算分桶个数;
- 【必须】如果分区表的各个分区的数据差异很大,建议不要使用动态分桶策略
(3)分桶裁剪和数据倾斜如何抉择?
- 【建议】如果分桶列是 WHERE 中经常用到的列,且分桶列的重复度比较低(例如用户ID,事物ID等),则可以利用该列作为分桶列;
-
【建议】当查询条件包含 city_id 和 site_id 时,若 city_id 的取值仅有几十个,简单地只使用 city_id 作为分桶可能导致某些桶数据量过大,引发数据倾斜问题。在这种情况下,可以考虑将 city_id 和 site_id 联合作为分桶字段。不过这样做的缺点是当查询条件中只包含 city_id 时,无法利用分桶进行数据裁剪;
-
【建议】如何没有合适的字段作为分桶字段打散数据,可以利用Random分桶,不过这样的话没办法利用分桶裁剪的属性;
-
【必须】2 个或多个超过KW 行以上的表Join,建议使用 Colocate,具体参考:Colocate Join | StarRocks
2.6 字段类型
- 【建议】不要使用 null属性;
- 【必须】确保时间类型和数字类型的列选择正确的数据类型。若使用不正确的数据类型,计算开销会大大增加。例如,时间类型的数据如 "2024-01-01 00:00:00" 不应该使用 VARCHAR 存储,这样做将无法利用 StarRocks 内部的 Zonemap 索引,也无法加速过滤操作。
2.7 索引选择
2.7.1 Bitmap索引
-
适合基数在10000-100000 左右的列;
- 适合等值条件(=)查询或[NOT] IN 范围查询的列;
-
不支持为 FLOAT、DOUBLE、BOOLEAN 和 DECIMAL 类型的列创建 Bitmap 索引;
-
城市、性别这些基数在 255 以下的列不需要创建 Bitmap 索引,因为 StarRocks 内部有低基数字典,会针对这些 case 自动创建低基数字典用于加速;
-
明细模型和主键模型,所有列可以创建Bitmap 索引;聚合模型和更新模型,只有 Key 列支持创建Bitmap 索引;
2.7.2 Bloom filter索引
- 适合基数在 100000+ 的列,列的重复度很低;
- 适合
in和=过滤条件的查询; - 不支持为 TINYINT、FLOAT、DOUBLE 和 DECIMAL 类型的列创建 Bloom filter 索引;
- 主键模型和明细模型中所有列都可以创建 Bloom filter 索引;聚合模型和更新模型中,只有维度列(即 Key 列)支持创建 Bloom filter 索引;
三、数据导入
3.1 使用建议
- 【必须】生产禁止使用 insert into values() 导数据;
- 【必须】建议导入批次间隔 5s+,也就是攒批写入,尤其是实时场景;
- 【建议】主键模型更新场景,建议开启索引落盘,磁盘强制SSD、NVME或更高性能的磁盘;
- 【建议】比较多 ETL(insert into select)场景,建议开启Spill 落盘功能避免内存超出限制;
3.2 数据生命周期
- 【建议】使用truncate删除数据,不要使用 delete;
- 【必须】完整的update 语法只能用于 3.0 版本以后的主键模型,禁止高并发 update,建议每次 update 操作需要间隔分钟以上;
- 【必须】如果使用 delete 删除数据,需要带上 where 条件,并且禁止并发执行 delete,例如要删除 id=1,2,3,4,……1000,禁止 delete xxx from tbl1 where id=1 这样的语句执行1000条,建议 delete xxx from tbl1 where id in (1,2,3...,1000);
- 【必须】drop操作默认会进入 FE 回收站,并保留 86400 秒(即 1 天),在这段时间内可以 recover 进行恢复,以防误操作。此行为受 catalog_trash_expire_second 参数控制。超过 1 天后,文件会移至 BE 的 trash 目录,默认保留 259200 秒(即 3 天);
版本2.5.17、3.0.9 和 3.1.6之后版本开始,BE 的默认保留时间已调整为86400 秒( 1 天),这一设置受 trash_file_expire_time_sec 参数影响。如果需要在 drop 操作后迅速释放磁盘空间,可以适当减少FE和 BE 的 trash保留时间。
四、数据查询
4.1 高并发场景
- 【建议】尽可能利用分区分桶裁剪,具体参考上文的分区和分桶选择部分
- 【必须】调大客户的并发限制,可以设置为 1000,默认 100,SET PROPERTY FOR 'jack' 'max_user_connections' = '1000';
- 【必须】开启Page Cache、Query Cache
4.2 数据精度
- 【必须】如果需要精确结果的,强制使用DECIMAL类型,不要使用FLOAT、DOUBLE 类型
4.3 SQL 查询
- 【必须】避免select * , 建议指定需要查询的列,例如select col0,col1 from tb1
- 【必须】避免全表扫描,建议增加过滤的谓词,例如select col0,col1 from tb1 where id=123,select col0,col1 from tb1 where dt>'2024-01-01'
- 【必须】为防止大量数据的一次性下载,建议强制采用分页查询。例如,使用以下分页查询语句来限制结果集中的列数和记录数:SELECT col0, col1, col2, ..., col50 FROM tb ORDER BY id LIMIT 0, 50000。这样可以有效地管理和减少单次查询返回的数据量;
- 【必须】分页操作需要加上order by,要不然是无序的;
- 【建议】避免使用一些不必要的函数或表达式;
-
Join
- 【必须】关联的字段类型匹配,虽然StarRocks 已经在内部做了隐式转换来达到最优的性能,但是建议使用类型一致的字段Join,避免使用FLOAT、DOUBLE 类型 Join,可能会导致结果不准确;
- 【必须】关联的字段建议不要使用函数或者表达式,例如 join on DATE_FORMAT(tb1.col1,'%Y-%m-%d') = DATE_FORMAT(tb2.col1,'%Y-%m-%d')
- 【必须】2个或多个KW行以上的表Join,推荐Colocate Join
- 【建议】避免笛卡尔积
4.4 使用物化视图加速查询
4.4.1 bitmap_union精确去重
以下示例基于一张广告业务相关的明细表 advertiser_view_record,其中记录了点击日期 click_time、广告代码 advertiser、点击渠道 channel 以及点击用户 ID user_id。
CREATE TABLE advertiser_view_record(
click_time DATE,
advertiser VARCHAR(10),
channel VARCHAR(10),
user_id INT) distributed BY hash(click_time);该场景需要频繁使用如下语句查询点击广告的UV。
SELECT advertiser, channel, count(distinct user_id)FROM advertiser_view_record
GROUP BY advertiser, channel;如需实现精确去重查询加速,可以基于该明细表创建一张物化视图,并使用bitmap_union()函数预先聚合数据。
CREATE MATERIALIZED VIEW advertiser_uv AS SELECT advertiser, channel, bitmap_union(to_bitmap(user_id))FROM advertiser_view_record
GROUP BY advertiser, channel; 物化视图创建完成后,后续查询语句中的子查询 count(distinct user_id) 会被自动改写为 bitmap_union_count(to_bitmap(user_id)) 以便查询命中物化视图。
4.4.2异步物化视图最多支持3层嵌套
4.5 利用Cache加速查询
- 【建议】Page Cache:建议开启,可以加速数据扫描场景,如果内存有冗余,可以尽可能调大限制,默认是mem_limit*20%;
- 【建议】Query Cache,建议开启,可以加速单表或者多表Join的聚合场景
StarRocks 提供的 Query Cache 特性,可以帮助极大地提升聚合查询的性能。开启 Query Cache后,每次处理聚合查询时,StarRocks 都会将本地聚合的中间结果缓存于内存中。这样,后续收到相同或类似的聚合查询时,StarRocks 就能够直接从 Query Cache 获取匹配的聚合结果,而无需从磁盘读取数据并进行计算,大大节省查询的时间和资源成本,并提升查询的可扩展性。在大量用户同时对复杂的大数据集执行相同或类似查询的高并发场景下,Query Cache 的优势尤为明显。
在 2.5 版本,Query Cache 仅支持宽表模型下的单表聚合查询。自 3.0 版本起,除宽表模型下的单表聚合查询外,Query Cache还支持星型模型下简单多表 JOIN 的聚合查询。
-
【建议】Data Cache,用于存算分离和湖分析场景,建议这两个场景下默认开启
五、监控
- 【必须】通过审计插件把fe.audit.log的数据导入一个表方便进行分析慢查询;通过 Audit Loader 管理 StarRocks 中的审计日志,具体参考:通过 AuditLoader 管理 StarRocks 中的审计日志 | StarRocks
-
【必须】参考 “https://docs.starrocks.io/zh/docs/2.5/administration/Monitor_and_Alert/ ” 部署 prometheus+grafana
-
【建议】利用资源隔离进行大查询熔断(避免大查询将集群资源打满),小查询保底
# shortquery_group 资源组用于核心业务重保
CREATE RESOURCE GROUP shortquery_group
TO
(user='rg1_user1', role='rg1_role1', db='db1', query_type in ('select'), source_ip='192.168.x.x/24'),
WITH (
'type' = 'short_query',
'cpu_core_limit' = '10',
'mem_limit' = '20%'
);
# bigquery_group 用于大查询熔断,避免大查询将集群资源打满
CREATE RESOURCE GROUP bigquery_group
TO
(user='rg1_user2', role='rg1_role1', query_type in ('select')),
WITH (
"type" = 'normal',
'cpu_core_limit' = '10',
'mem_limit' = '20%',
'big_query_cpu_second_limit' = '100',
'big_query_scan_rows_limit' = '100000',
'big_query_mem_limit' = '1073741824'
);- 大查询定位
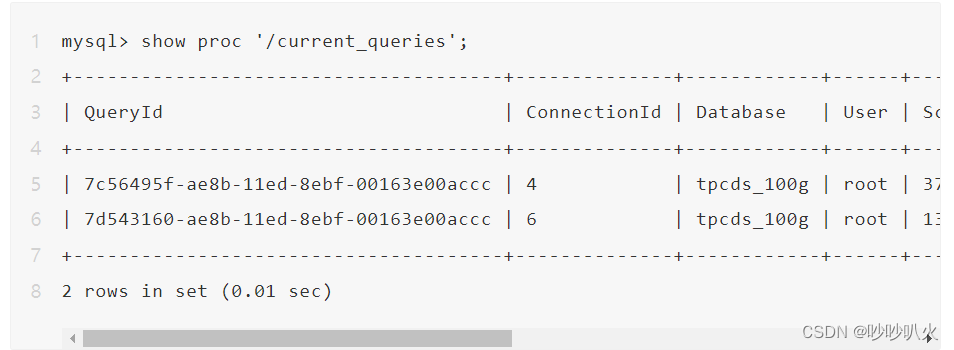
1)查看当前FE上正在运行的查询SQL命令:
show proc '/current_queries'返回结果包括以下几列:
- QueryId
- ConnectionId
- Database:当前查询的 DB
- User:用户
- ScanBytes:当前已扫描的数据量,单位 Bytes
- ProcessRow:当前已扫描的数据行数
- CPUCostSeconds:当前查询已使用的 CPU 时间,单位秒。此为多个线程累加的 CPU 时间,举个例子,如果有两个线程分别占用 1 秒和 2 秒的 CPU 时间,那么累加起来的 CPU 时间为3秒;
- MemoryUsageBytes:当前占用的内存。如果查询涉及到多个BE节点,此值即为该查询在所有 BE 节点上占用的内存之和;
- ExecTime:查询从发起到现在的时长,单位为毫秒;
2)查看某个查询在每个BE节点上的资源消耗 SQL 命令:
show proc '/current_queries/${query_id}/hosts'返回结果有多行,每行描述该查询在对应BE节点上的执行信息,包括以下几列:
- Host:BE 节点信息
- ScanBytes:已经扫描的数据量,单位 Bytes
- ScanRows:已经扫描的数据行数
- CPUCostSeconds:已使用的 CPU 时间
- MemUsageBytes:当前占用的内存

参考文章:
StarRocks 实战指南:100+ 大型企业背后的最佳实践经验