一:系统版本:
二:部署环境:
节点名称
IP
部署组件及版本
配置文件路径
机器CPU
机器内存
机器存储
Log-001
10.10.100.1
zookeeper:3.4.13
kafka:2.8.1
elasticsearch:7.7.0
logstash:7.7.0
kibana:7.7.0
zookeeper:/data/zookeeper
kafka:/data/kafka
elasticsearch:/data/es
logstash:/data/logstash
kibana:/data/kibana
2*1c/16cores
62g
50g 系统
800g 数据盘
Log-002
10.10.100.2
zookeeper:3.4.13
kafka:2.8.1
elasticsearch:7.7.0
logstash:7.7.0
kibana:7.7.0
zookeeper:/data/zookeeper
kafka:/data/kafka
elasticsearch:/data/es
logstash:/data/logstash
kibana:/data/kibana
2*1c/16cores
62g
50g 系统
800g 数据盘
Log-003
10.10.100.3
zookeeper:3.4.13
kafka:2.8.1
elasticsearch:7.7.0
logstash:7.7.0
kibana:7.7.0
zookeeper:/data/zookeeper
kafka:/data/kafka
elasticsearch:/data/es
logstash:/data/logstash
kibana:/data/kibana
2*1c/16cores
62g
50g 系统
800g 数据盘
三:部署流程:
(1)安装docker和docker-compose
apt-get install -y docker wget https://github.com/docker/compose/releases/download/1.29.2/docker-compose-Linux-x86_64 mv docker-compose-Linux-x86_64 /usr/bin/docker-compose(2)提前拉取需要用到的镜像
docker pull zookeeper:3.4.13 docker pull wurstmeister/kafka docker pull elasticsearch:7.7.0 docker pull daocloud.io/library/kibana:7.7.0 docker pull daocloud.io/library/logstash:7.7.0 docker tag wurstmeister/kafka:latest kafka:2.12-2.5.0 docker tag docker.io/zookeeper:3.4.13 docker.io/zookeeper:3.4.13 docker tag daocloud.io/library/kibana:7.7.0 kibana:7.7.0 docker tag daocloud.io/library/logstash:7.7.0 logstash:7.7.0(3)准备应用的配置文件
mkdir -p /data/zookeeper mkdir -p /data/kafka mkdir -p /data/logstash/conf mkdir -p /data/es/conf mkdir -p /data/es/data chmod 777 /data/es/data mkdir -p /data/kibana(4)编辑各组件配置文件
## es配置文件 ~]# cat /data/es/conf/elasticsearch.yml cluster.name: es-cluster network.host: 0.0.0.0 node.name: master1 ## 每台节点需要更改此node.name,e.g master2,master3 http.cors.enabled: true http.cors.allow-origin: "*" ## 防止跨域问题 node.master: true node.data: true network.publish_host: 10.10.100.1 ## 每台节点需要更改为本机IP地址 discovery.zen.minimum_master_nodes: 1 discovery.zen.ping.unicast.hosts: ["10.10.100.1","10.10.100.2","10.10.100.3"] cluster.initial_master_nodes: ["10.10.100.1","10.10.100.2","10.10.100.3"] ## elasticsearch启动过程会有报错,提前做以下操作 ~]# vim /etc/sysctl.conf vm.max_map_count=655350 ~]# sysctl -p ~]# cat /etc/security/limits.conf * - nofile 100000 * - fsize unlimited * - nproc 100000 ## unlimited nproc for * ## logstash配置文件 ~]# cat /data/logstash/conf/logstash.conf input{ kafka{ topics => ["system-log"] ## 必须和前后配置的topic统一 bootstrap_servers => ["10.10.100.1:9092,10.10.100.2:9092,10.10.100.3:9092"] } } filter{ grok{ match =>{ "message" => "%{SYSLOGTIMESTAMP:timestamp} %{IP:ip} %{DATA:syslog_program} %{GREEDYDATA:message}" } overwrite => ["message"] } date { match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } } output{ elasticsearch{ hosts => ["10.10.100.1:9200","10.10.100.2:9200","10.10.100.3:9200"] index => "system-log-%{+YYYY.MM.dd}" } stdout{ codec => rubydebug } } ~]# cat /data/logstash/conf/logstash.yml http.host: "0.0.0.0" xpack.monitoring.elasticsearch.hosts: [ "http://10.10.100.1:9200","http://10.10.100.2:9200","http://10.10.100.3:9200" ] ## kibana配置文件 ~]# cat /data/kibana/conf/kibana.yml # # ** THIS IS AN AUTO-GENERATED FILE ** # # Default Kibana configuration for docker target server.name: kibana server.host: "0.0.0.0" elasticsearch.hosts: [ "http://10.10.100.1:9200","http://10.10.100.2:9200","http://10.10.100.3:9200" ] monitoring.ui.container.elasticsearch.enabled: true(5)所有组件的部署方式全部为docker-compose形式编排部署,docker-compose.yml文件所在路径/root/elk_docker_compose/,编排内容:
~]# mkdir /data/elk ~]# cat /root/elk_docker_compose/docker-compose.yml version: '2.1' services: elasticsearch: image: elasticsearch:7.7.0 container_name: elasticsearch environment: ES_JAVA_OPTS: -Xms1g -Xmx1g network_mode: host volumes: - /data/es/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml - /data/es/data:/usr/share/elasticsearch/data logging: driver: json-file kibana: image: kibana:7.7.0 container_name: kibana depends_on: - elasticsearch volumes: - /data/kibana/conf/kibana.yml:/usr/share/kibana/config/kibana.yml logging: driver: json-file ports: - 5601:5601 logstash: image: logstash:7.7.0 container_name: logstash volumes: - /data/logstash/conf/logstash.conf:/usr/share/logstash/pipeline/logstash.conf - /data/logstash/conf/logstash.yml:/usr/share/logstash/config/logstash.yml depends_on: - elasticsearch logging: driver: json-file ports: - 4560:4560 zookeeper: image: zookeeper:3.4.13 container_name: zookeeper environment: ZOO_PORT: 2181 ZOO_DATA_DIR: /data/zookeeper/data ZOO_DATA_LOG_DIR: /data/zookeeper/logs ZOO_MY_ID: 1 ZOO_SERVERS: "server.1=10.10.100.1:2888:3888 server.2=10.10.100.2:2888:3888 server.3=10.10.100.3:2888:3888" volumes: - /data/zookeeper:/data/zookeeper network_mode: host logging: driver: json-file kafka: image: kafka:2.12-2.5.0 container_name: kafka depends_on: - zookeeper environment: KAFKA_BROKER_ID: 1 KAFKA_PORT: 9092 KAFKA_HEAP_OPTS: "-Xms1g -Xmx1g" KAFKA_HOST_NAME: 10.10.100.145 KAFKA_ADVERTISED_HOST_NAME: 10.10.100.1 KAFKA_LOG_DIRS: /data/kafka KAFKA_ZOOKEEPER_CONNECT: 10.10.100.1:2181,10.10.100.2:2181,10.10.100.3:2181 network_mode: host volumes: - /data:/data logging: driver: json-file(6)启动服务
#开始部署(三台节点分别修改配置文件和docker-compose配置) ~]# docker-compose up -d #停止运行的容器实例 ~]# docker-compose stop #单独启动容器 ~]# docker-compose up -d kafka(7)验证集群各组件服务状态
(1) 验证zookeeper: ]# docker exec -it zookeeper bash bash-4.4# zkServer.sh status ZooKeeper JMX enabled by default Using config: /conf/zoo.cfg Mode: follower (2) 验证kafka: ]# docker exec -it kafka bash bash-4.4# kafka-topics.sh --list --zookeeper 10.10.100.1:2181 __consumer_offsets system-log (3) 验证elasticsearch ]# curl '10.10.100.1:9200/_cat/nodes?v'ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 10.10.100.1 57 81 0 0.37 0.15 0.09 dilmrt * master2 10.10.100.2 34 83 0 0.11 0.10 0.06 dilmrt - master1 10.10.100.3 24 81 0 0.03 0.06 0.06 dilmrt - master3 (4) 验证kibana 浏览器打开http://10.10.100.1:5601
三:日志收集
(1)以nginx日志为例,安装filebeat日志采集器
apt-get install filebeat(2)配置filebeat向kafka写数据
启用 Nginx 模块: sudo filebeat modules enable nginx 配置 Nginx 模块: 编辑 /etc/filebeat/modules.d/nginx.yml,确保日志路径正确。例如: - module: nginxaccess:enabled: truevar.paths: ["/var/log/nginx/access.log*"] error:enabled: truevar.paths: ["/var/log/nginx/error.log*"] 设置输出为 Kafka: 在 filebeat.yml 文件中,配置输出到 Kafka: output.kafka: # Kafka 服务地址 hosts: ["10.10.100.1:9092", "10.10.100.2:9092", "10.10.100.3:9092"] topic: "system-log" partition.round_robin: reachable_only: false required_acks: 1 compression: gzip max_message_bytes: 1000000 重启 Filebeat: sudo systemctl restart filebeat(3)配置验证:使用 Filebeat 的配置测试命令来验证配置文件的正确性:
filebeat test config
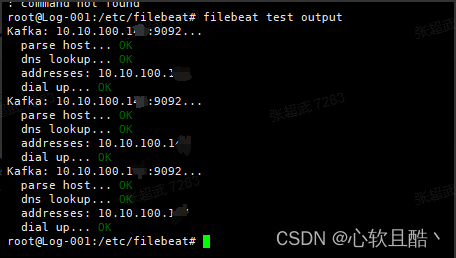
(4)连接测试:可以测试 Filebeat 到 Kafka 的连接:
filebeat test output
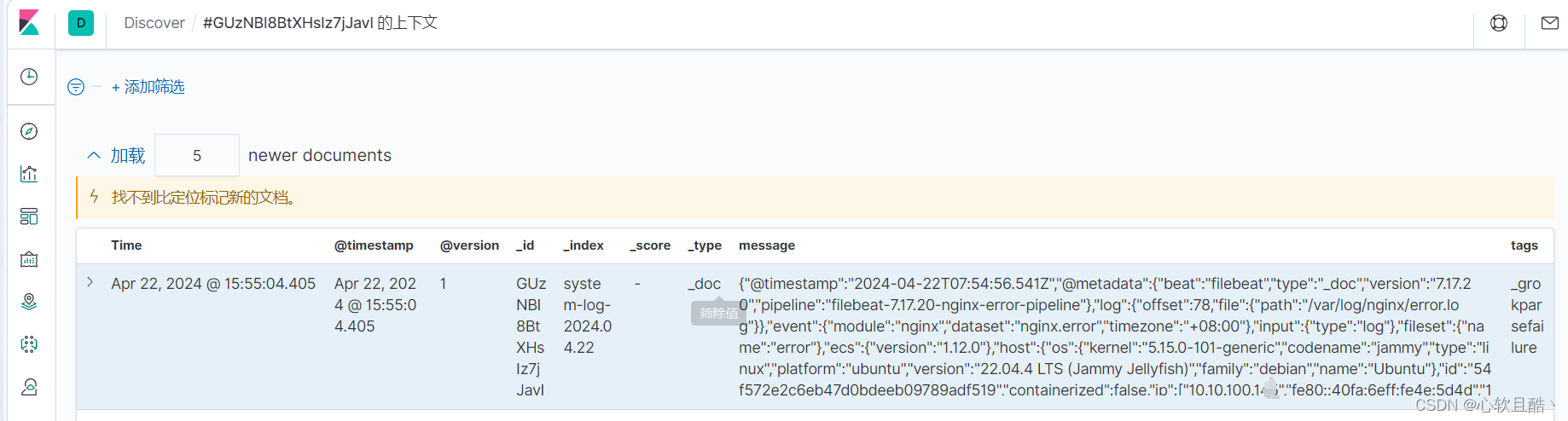
(5)登录kibana控制台查看nginx日志是否已正常收集到
3节点ubuntu24.04服务器docker-compose方式部署高可用elk+kafka日志系统并接入nginx日志
news2026/2/15 19:22:24


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1619107.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

贪心算法在单位时间任务调度问题中的应用
贪心算法在单位时间任务调度问题中的应用 一、引言二、问题描述与算法设计三、算法证明四、算法实现与效率分析五、C语言实现示例六、结论 一、引言
单位时间任务调度问题是一类经典的优化问题,旨在分配任务到不同的时间槽中,使得某种性能指标达到最优。…
【JAVA】UDP与TCP套接字编程
目录
一、UDP数据报套接字编程
1、DatagramSocket API
2、DatagramPacket API
3、InetSocketAddress API
4、示例一
5、示例二
二、TCP流套接字编程
1、ServerSocket API
2、Socket API
3、TCP中的长短连接
4、示例一
5、示例二 一、UDP数据报套接字编程
1、Datag…

《ElementPlus 与 ElementUI 差异集合》el-select 显示下拉列表在 Cesium 场景中无法监听关闭
前言
仅在 Element UI 时有此问题,Element Plus 由于内部结构差异较大,不存在此问题。详见《el-select 差异点,如:高、宽、body插入等》;
问题
点击空白处,下拉列表可监听并关闭;但在 Cesium…
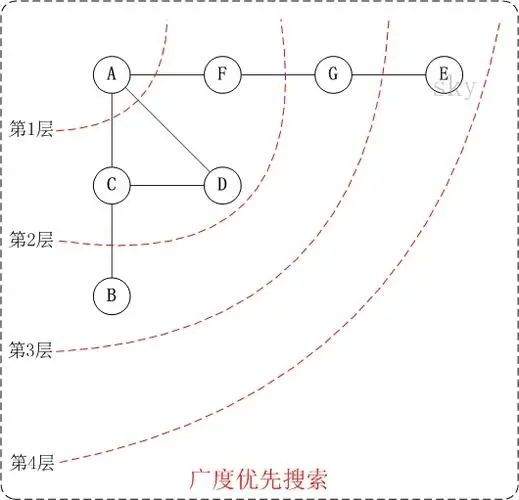
图解《图搜索算法》及代码实现
关注我,持续分享逻辑思维&管理思维; 可提供大厂面试辅导、及定制化求职/在职/管理/架构辅导; 有意找工作的同学,请参考博主的原创:《面试官心得--面试前应该如何准备》,《面试官心得--面试时如何进行自…
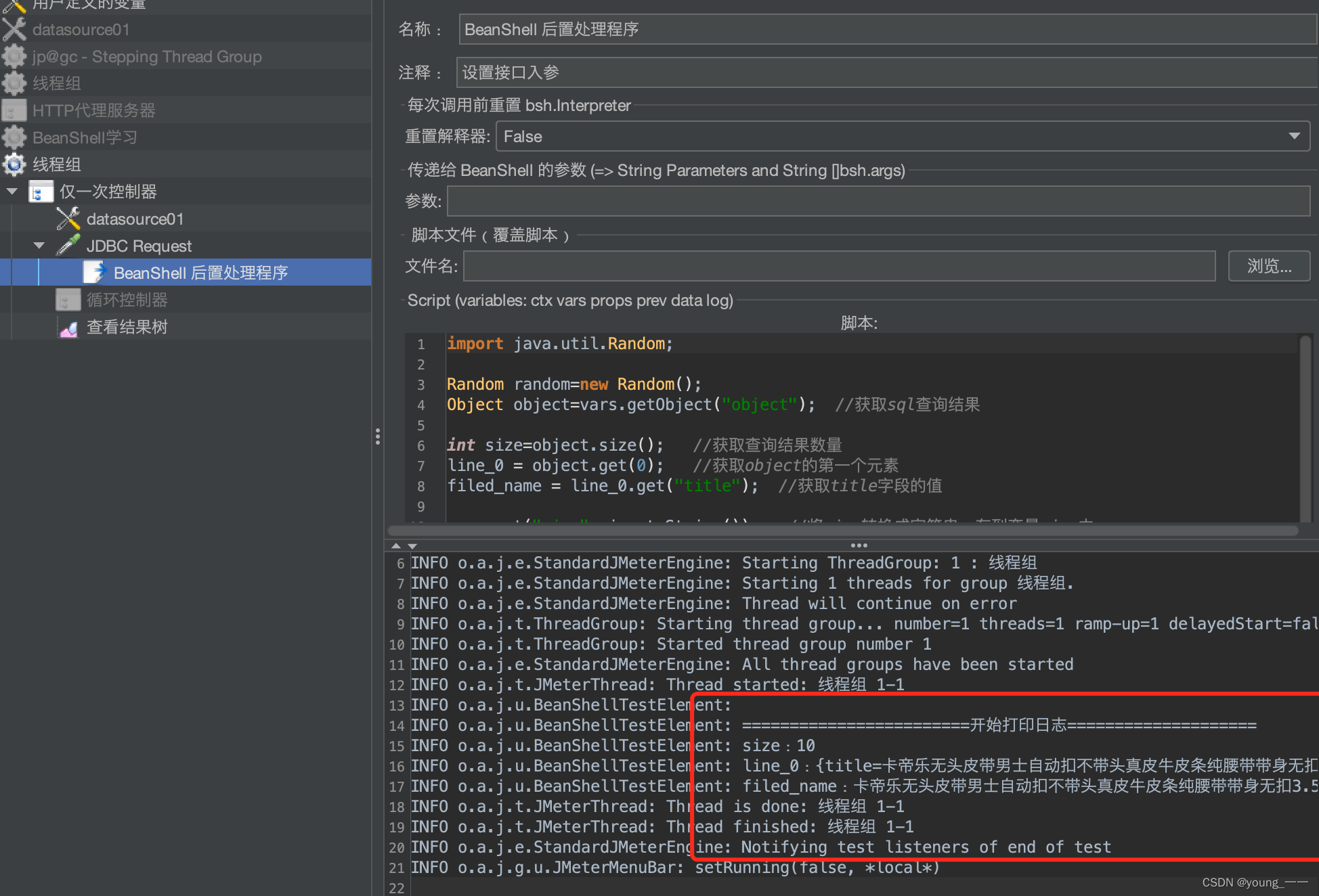
Jmeter之Beanshell详解
一、 Beanshell概念 Beanshell: BeanShell是一种完全符合Java语法规范的脚本语言,并且又拥有自己的一些语法和方法;BeanShell是一种松散类型的脚本语言(这点和JS类似);BeanShell是用Java写成的,一个小型的、免费的、可以下载的、嵌入式的Java源代码解释器,具有对象脚本语言特性…
LayuiMini使用时候初始化模板修改(下载源码)
忘记加了 下载 地址 : layui-mini: layuimini,后台admin前端模板,基于 layui 编写的最简洁、易用的后台框架模板。只需提供一个接口就直接初始化整个框架,无需复杂操作。 LayuiMini使用时候初始化模板官网给的是: layu…
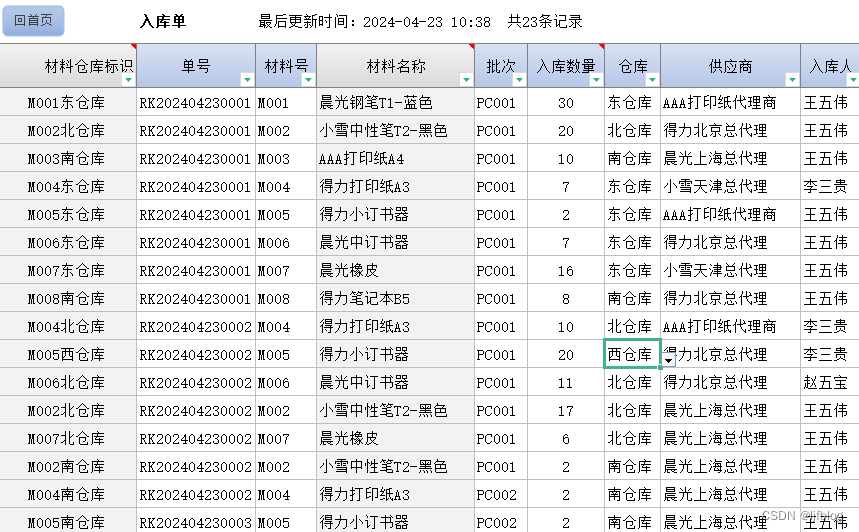
用Excel做一个功能完备的仓库管理系统
1 基本设计思路
用到的Excel技术:sumif, vlookup, 表格(table)。基本思路:在有基础的商品、仓库等信息的情况下,对商品的每一个操作都有对应的单据,然后再汇总统计。标识:为了在不同的维度统计数量,各单据…

国产FTP文件传输服务器需要具备哪些关键特性?
国产FTP文件传输服务器是指根据中国国内信息技术创新(信创)的要求和标准,自主研发的文件传输服务器软件。这类软件旨在替代传统的FTP服务器,以更好地适应国产化和信息安全的需要。国产FTP文件传输服务器通常需要具备以下要求&…

图书租赁系统-扣费服务
resources中添加moment.js文件。 然后引入moment.js文件: <script src"/js/moment.js"></script>借阅结束时间选完后changeDate事件:
$("input[nameendTime]").datetimepicker({format: "yyyy-mm-dd hh:ii",…

Linux:进程与计划任务
文章目录 Linux:进程与计划任务一、进程1、进程是什么2、进程状态 二、列出进程命令1、查看静态的进程统计信息——“ps”Play1:“ps aux”Play2:ps -elf 2、查看静态的进程统计信息——“top”段首解析进程信息区解释 三、运行与终止进程3.1、运行进程3…

为什么要写技术方案?
技术方案是为研究解决各类技术问题,有针对性,系统性的提出的方法、应对措施及相关对策。技术方案设计是一个技术开发者必备的能力,特别是对于高级、资深、架构师等角色。技术方案设计不仅能够帮助我们明确需求,规划架构࿰…
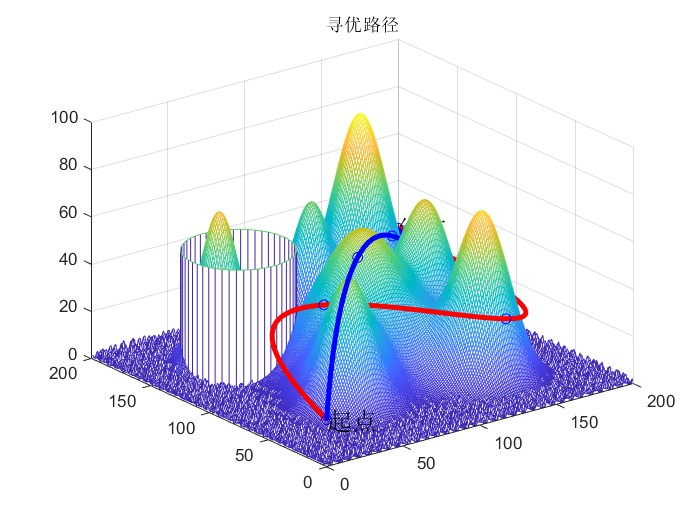
2024新算法爱情进化算法(LEA)和经典灰狼优化器(GWO)进行无人机三维路径规划设计实验
简介:
2024新算法爱情进化算法(LEA)和经典灰狼优化器(GWO)进行无人机三维路径规划设计实验。 无人机三维路径规划的重要意义在于确保飞行安全、优化飞行路线以节省时间和能源消耗,并使无人机能够适应复杂环…
windows系统下python开发工具安装
一. 简介
前一篇文章学习了安装 python解释器,文章如下:
windows系统下python解释器安装-CSDN博客
本文来学习如何下载安装 python开发工具 PyCharm。 二. python开发工具 PyCharm下载安装
1. PyCharm官网 PyCharm开发工具
PyCharm为 python代码…
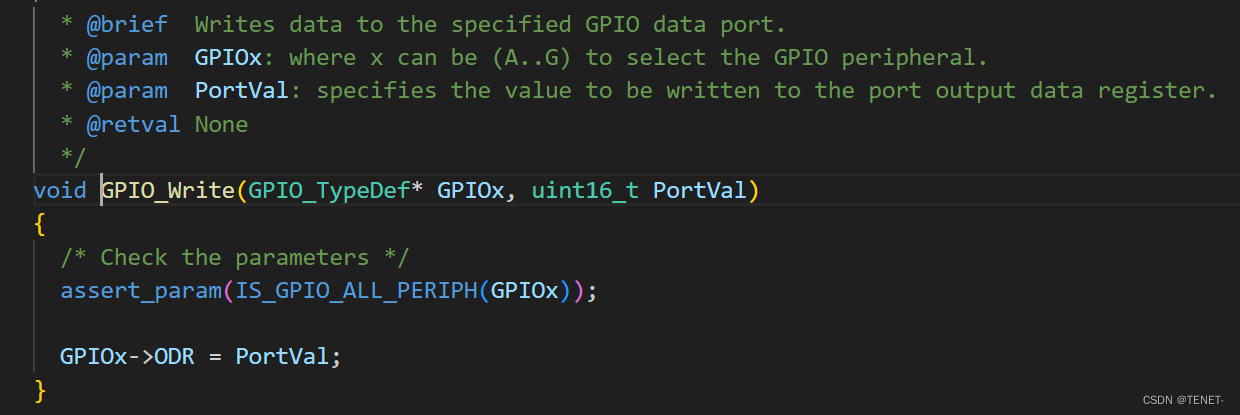
STM32的GPIO输入和输出函数详解
系列文章目录
STM32单片机系列专栏
C语言术语和结构总结专栏 文章目录 1. GPIO模式
2. GPIO输出
2.1 RCC
2.2 GPIO
3. 代码示例
3.1 RCC时钟
3.2 GPIO初始化
3.3 GPIO输出函数
3.4 推挽输出和开漏输出
4. GPIO输入
4.1 输入模式
4.2 数据读取函数
5. C语言语法 1…
Mudem,打造私密安全、高效稳定的私人空间
Mudem 是 Codigger 平台中的一个关键组件,它提供基础通讯服务,确保不同类型的机器之间可以进行安全和高效的连接。它其设计理念在于将本地机器、公有云以及私有云上的设备无缝地整合为一个可远程在线访问的工作站(Workstation)。这…
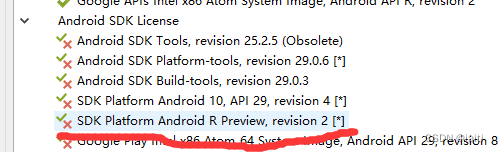
Android SDK Manager安装Google Play Intel x86 Atom_64 System Image依赖问题
Package Google Play Intel x86 Atom_64 System Image,Android API R, revision 2 depends on SDK Platform Android R Preview, revision 2 问题 一开始以为网络还有依赖包没有勾选,尝试了很多次,勾选这边报错对应的license即可。此时点击一下其他licen…
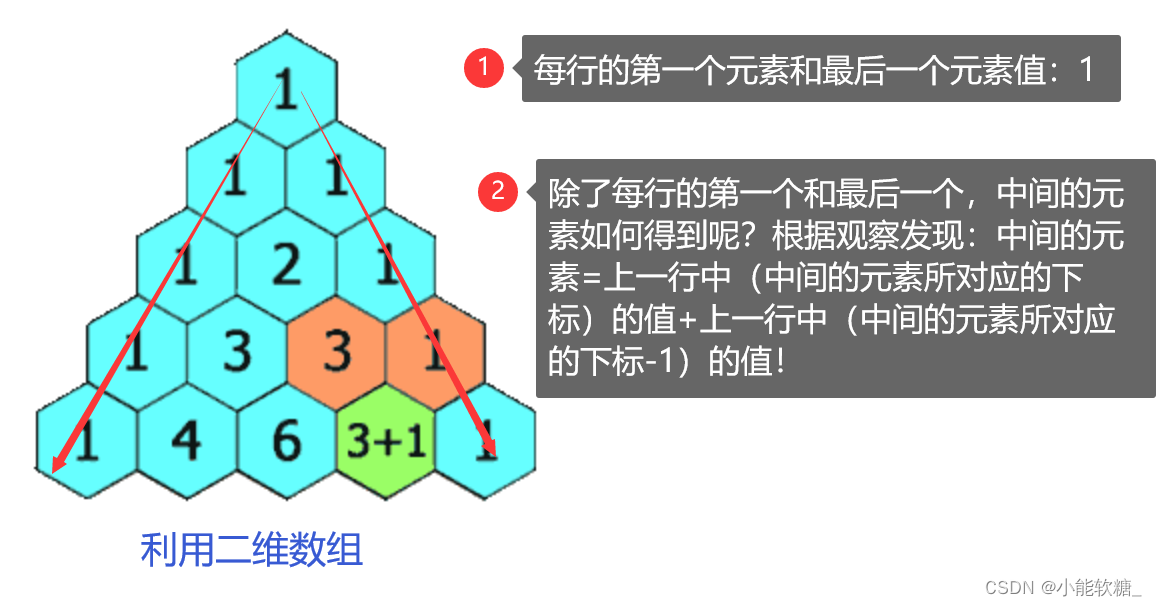
【LeetCode】---118.杨辉三角
一、题目解析: 二、知识回顾:
1.二维数组: 2. C语言中的二维数组访问方式和vector二维数组的访问, 不同区别: (1)表面是一样的,但底层不同! (2)静…
“PowerInfer:消费级GPU上的高效大语言模型推理引擎“
PowerInfer是由上海交通大学IPADS实验室开发的一个高效大语言模型(LLM)推理引擎,专为个人电脑(PC)上的消费者级GPU设计。它通过利用LLM推理中的高局部性,实现了快速且资源消耗低的模型推理,这一…
【插件】IDEA 热部署插件 JRebel
1 搜索安装插件 JRebel 2 选中Team URL 1、在上面的框中输入激活的url地址
https://jrebel.qekang.com/{GUID} http://jrebel-license.jiweichengzhu.com/{GUID} GUID生成工具
Create GUID online (guidgen.com)
备用
404 Not Found (ofmonkey.com) 如果上述激活地址不能…

蓝桥杯2024年第十五届省赛真题-小球反弹
以下两个解法感觉都靠谱,并且网上的题解每个人答案都不一样,目前无法判断哪个是正确答案。
方法一:模拟 代码参考博客
#include <iostream>
#include <cmath>
#include <vector>using namespace std;int main() {const i…