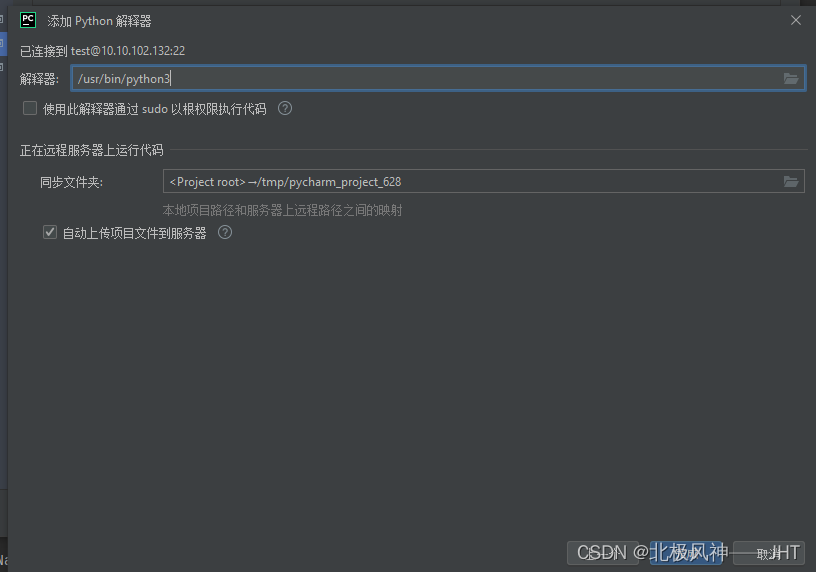
正向索引和倒排索引:
正向索引:
比方说我这里有一张数据库表,那我们知道对于数据库它一般情况下都会基于i d去创建一个索引,然后形成一个b+树。
那么你根据i d进行检索的速度,就会非常的快,那么这种方式的所以就是一个正向索引。但是如果我现在搜索的字段不是i d,而是一个普通的标题字段,标题字段一般它内容比较长,你不会给他加索引,对吧?
即便你给他加索引,那现在我想的不是确的标题值。我想其中的一部分:
搜索'手机"
select *from tb_goods where title like'%手机%'
这里你一旦使用了这样的模糊匹配,那么即便这个字段有索引,将来是不是也不生效了?那这种情况下没有索引,我们数据库该怎么去比较和查询?它就会采用逐条扫描的方式来判断每一行数据中是否包含手机。
判断以后,如果发现不包含,那就直接把它丢。如果包含,则把它放到我们的结果集当中。
逐行去扫描,最终一定能够拿到完整的结果集,没错吧。但是你想想看,如果你这张表有一千万的数据,那也就意味着你要扫描多少次了,是不是一千万次,那么它的性能可想而知是比较差的。
所以这是正向索引,它在做这种局部内容检索的时候,效率就比较差了。
倒排索引:
倒排索引,它在存储时,它会先先把文档中的内容分成词条去存。并且这些词条肯定会有大量的重复,没错吧?那因为中文的词语可能就那么多,但是我们不能重复记录,而是记录唯一的一个。如果有重复词条出现在后边,记录文档i d即可
这样可以确保倒排索引当中,词条字段这里是绝对不会出现重复的,保证它的唯一性, 因为它的唯一性,我们就可以给它创建索引了,你可以数据较少的时候使用哈希法,也可以使用b+数,去给词条创建唯一索引,那将来我们根据词条查找的速度是不是就非常的快了
比方说现在我来搜索华为手机,那这个搜索的方式比刚才那个是不是还要复杂了,那么我们的倒排索引它会怎么做?它第一步:会对用户输入的这一段内容: “华为手机”做一个分词。
因为搜索的时候给你的是一句话,华为手机”,这不行,要分词。那会分出两个词语,一个是“华为”,一个是”手机“,没错吧?
下一步该干嘛了?下一步拿着这两个词条去倒排索引中进行一个查询:
因为所有词条建立了索引,所以我根据这俩词条来查询的速度如何,是不是非常的快。
这个时候,我去一查,我就能够查到谁呀。华为这不是2、3吗?手机是不是1、2么,那我就能够得到两组文档id没错吧? 这个时候,我就可以通过文档id从而知道包含华为、手机的所有的文档了
其中的二号文档两个词都包含”华为“、”手机“这两个词儿。所以从关联度来讲,谁的关联度更高一点?是不是二号文档?那么将来我还给你排个序,二号我排在最前边,然后一和三再往后排。
那然后,我拿着这个三个id我就可以去查询文档了呀,是不是根据id建立了索引,那么拿着i d找,是不是快速的就能定位到文档了,最后把它放到我们的结果集当中就行了:

那么我们这个倒排索引的过程,同学们可以看到它其实经过了两次检索:
第一次是根据用户输入内容的词条去词条列表中进行一个寻找,找到对应的文档i d、
而第二次是拿着文档i d找具体文档。 虽然是两次,但每一次他都经历了索引进行查询,所以总的查询效率是比刚才那种逐条扫描要高的多的多的。
倒排索引为什么叫倒排索引?
倒排索引为什么叫倒排索引?因为在正向索引当中,我要去找到包含”华为“、”手机“,我得一行一行的先看这条文档,找到这条文档了,看一下:你包含手机吗?,包含的话存入结果集、再看下一条包不包含这个词语、再看下一条包不包含这个词语..... :是先找到文档,然后看文档是否符合我们的词条要求。
而倒排索引是反过来的,它是基于词条创建索引,然后去关联到文档:查找的时候,是先找词条,再根据词条找到对应的文档,是根据词条找文档。而正向是根据文档找的词条,是不是反过来的一个过程,所以叫倒排索引,就是这个原因。
我们主要是了解了一下正向索引和倒排索引, 了解了两个概念,一个是文档,一个是词条。
什么是文档?文档其实就是我们的每一行数据,无论是商品也好,还是订单也好,用户也好,还是这个网页也好,这些都是文档,每一条数据就是一个文档。那词条就是对文档中的内容做分词,按照语义:中文就按照中文含义分,英文就按照空格分,分出来的这些词语就是词条了
什么是正向索引,正向索引其实就类似于数据库那种,基于id创建的索引。那他在检索的时候,如果你是搜索非索引字段,你必须得逐行扫描去进行检索,然后进行匹配,先找文档,那根据文档判断是否包含词条。
而倒排索引是反过来一个过程。那它先相对内容分层得到词条,是给词条创建索引,然后记录词条所在的文档信息,查询的时候,是先根据词条找到文档i d,然后再根据id找到文档,是这么一个过程。




![[论文笔记] EcomGPT:COT扩充数据的电商大模型](https://img-blog.csdnimg.cn/direct/83033b9b062b42af9649618027df68fa.png)