前言
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言。XPath使用路径表达式来选取XML文档中的节点或节点集。这些节点是通过沿着路径(path)或者步(steps)来选取的。XPath不仅可以用于搜寻XML文档,同样适用于HTML文档的搜索。
特点:
- 灵活性:XPath可以用于定位和选择XML文档中的任何节点,无论节点的层次结构如何复杂。它可以根据节点的名称、属性、位置等多种条件来进行选择。
- 简洁性:XPath的语法相对简单明了,路径表达式直观且易于理解。使用XPath可以很容易地定位到所需的节点,而无需编写复杂的代码。
- 强大性:XPath支持大部分的节点选择、轴定位和运算符操作,可以实现更加复杂和精确的节点筛选和处理。XPath还支持函数的使用,可以进行数值计算、字符串处理等操作。
XPath广泛应用于XML解析、XSLT转换、XPath查询等领域,是XML技术中的重要组成部分。它可以用于解析XML文档,并根据节点的层次结构和属性值来定位和选择节点。同时,XPath在各种编程语言中都有应用,如Java、Python、C#等,为开发者提供了灵活且强大的工具来操作和查询XML数据。也是爬虫最常用的工具。
XPath的基本语法
XPath 是一种在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。以下是一些 XPath 最常用的基本语法格式:
选择节点
- 选择所有节点:
/- 选择当前节点:
.- 选择当前节点的父节点:
..- 选择特定元素:
/元素名或元素名- 选择特定属性的值:
元素名/@属性名选择多个节点
- 通过逗号分隔来选择多个元素:
元素1, 元素2, ...- 选择具有特定属性的元素:
元素名[@属性名='属性值']选择子节点
- 选择直接子节点:
父元素名/子元素名- 选择所有后代节点:
父元素名//子元素名选择特定位置的节点
- 选择第一个子节点:
父元素名/子元素名[1]- 选择最后一个子节点:
父元素名/子元素名[last()]- 选择具有特定位置的子节点:
父元素名/子元素名[位置]基于条件选择节点
- 选择满足特定条件的元素:
元素名[条件]- 选择属性值满足特定条件的元素:
元素名[@属性名=值]- 使用逻辑运算符组合条件:
元素名[@属性1='值1' and @属性2='值2']选择文本内容
- 选择元素的文本内容:
元素名/text()选择属性和节点的组合
- 选择元素及其属性的组合:
元素名/@属性名, 元素名/子元素名通配符
- 选择所有元素:
*- 选择具有特定属性的所有元素:
*[@属性名='值']
具体表达式演示
选取节点:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取(取子节点)。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
常用的路径表达式及其结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语(Predicates):
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]//title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点:
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
常用的路径表达式及其结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
基于Python库和数据源来实现XPath匹配和数据提取。
以下是使用lxml、BeautifulSoup、以及xml.etree.ElementTree(Python标准库)来获取数据的示例。
1. 使用 lxml
首先,我们创建一个XML文档并使用lxml来解析和提取数据。
from lxml import etree
# XML内容
xml_content = """
<bookstore>
<book category="fiction">
<title lang="en">Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="biography">
<title lang="en">Steve Jobs</title>
<author>Walter Isaacson</author>
</book>
</bookstore>
"""
# 解析XML
root = etree.fromstring(xml_content)
# 使用XPath提取数据
titles = root.xpath("//book/title/text()")
authors = root.xpath("//book/author/text()")
# 打印提取的数据
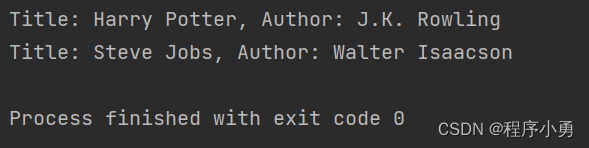
for title, author in zip(titles, authors):
print(f"Title: {title}, Author: {author}")
执行结果:
2. 使用 BeautifulSoup
接下来,我们使用BeautifulSoup和CSS选择器(但是它与XPath非常相似)来解析HTML内容并提取数据。
from bs4 import BeautifulSoup
# HTML内容
html_content = """
<html>
<body>
<div class="book" category="fiction">
<h2 class="title">Harry Potter</h2>
<p class="author">J.K. Rowling</p>
</div>
<div class="book" category="biography">
<h2 class="title">Steve Jobs</h2>
<p class="author">Walter Isaacson</p>
</div>
</body>
</html>
"""
# 解析HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 使用CSS选择器(与XPath类似)提取数据
titles = [title.text for title in soup.select(".book .title")]
authors = [author.text for author in soup.select(".book .author")]
# 打印提取的数据
for title, author in zip(titles, authors):
print(f"Title: {title}, Author: {author}")
执行结果:
3. 使用 xml.etree.ElementTree
最后,我们使用Python的标准库xml.etree.ElementTree来解析XML并提取数据。
import xml.etree.ElementTree as ET
# XML内容
xml_content = """
<bookstore>
<book category="fiction">
<title lang="en">平凡的世界</title>
<author>路遥</author>
</book>
<book category="biography">
<title lang="en">老人与海</title>
<author>海明威</author>
</book>
</bookstore>
"""
# 解析XML
root = ET.fromstring(xml_content)
# 使用ElementTree提取数据
titles = [book.find('title').text for book in root.findall('book')]
authors = [book.find('author').text for book in root.findall('book')]
# 打印提取的数据
for title, author in zip(titles, authors):
print(f"Title: {title}, Author: {author}")
执行结果:

快速获取XPath数据格式
首先打开需要获取数据的网页:如下
快速获取网页的XPath数据格式有几种方法,这里主要介绍使用浏览器的开发者工具来自动生成XPath的方式。大多数现代浏览器都提供了开发者工具,其中包括XPath查询功能。
使用浏览器的开发者工具获取XPath
以下是使用浏览器的开发者工具快速获取网页XPath的步骤:
打开网页:首先打开你想要获取XPath的网页。
打开开发者工具:
- Chrome:右键点击网页上的元素,选择“检查”或使用快捷键
Ctrl+Shift+I或Cmd+Option+I。- Firefox:右键点击网页上的元素,选择“检查元素”或使用快捷键
Ctrl+Shift+C或Cmd+Option+C。- Safari:右键点击网页上的元素,选择“检查元素”或使用快捷键
Cmd+Option+I。选择元素:在开发者工具的“元素”面板中,使用鼠标左键点击网页上的目标元素。
获取XPath:
- Chrome 和 Firefox:在开发者工具的“元素”面板中,高亮显示的元素将在代码中自动选中。右键点击选中的代码行(通常是
<tag>或<tag class="classname">),在上下文菜单中选择“复制” -> “复制XPath”。- Safari:在开发者工具的“元素”面板中,高亮显示的元素将在代码中自动选中。右键点击选中的代码行(通常是
<tag>或<tag class="classname">),在上下文菜单中选择“复制” -> “XPath”。
通过以上步骤,你将快速获得网页元素的XPath表达式,然后可以将其用于自动化脚本或其他需要XPath的应用中。
要使用XPath获取网页数据,首先需要使用Python的HTTP库获取网页内容,然后使用XPath来解析和提取数据。以下是一个示例,我们将使用requests库获取网页内容,并使用lxml来解析和提取数据。
假设我们要获取的网页是https://www.baidu.com,我们想要获取XPath为/html/body/div[4]/div/div[2]/div/div[3]/div/h3[1]的元素内容。
首先,确保你已经安装了requests和lxml库,如果没有,可以使用以下命令进行安装:
pip install requests lxml
实现代码:
import requests
from lxml import etree
# 目标网页URL
url = 'https://www.baidu.com'
# 发送HTTP请求获取网页内容
response = requests.get(url)
response.raise_for_status() # 如果HTTP请求返回了错误码,会抛出异常
# 使用lxml解析网页内容
html_content = response.text
tree = etree.HTML(html_content)
# 使用XPath提取数据
result = tree.xpath("/html/body/div[4]/div/div[2]/div/div[3]/div/h3[1]/text()")
# 打印提取的数据
if result:
print("提取的数据:", result[0])
else:
print("未找到匹配的数据")
![[论文笔记] EcomGPT:COT扩充数据的电商大模型](https://img-blog.csdnimg.cn/direct/83033b9b062b42af9649618027df68fa.png)