文章目录
- NLP中Bert的进展历史
- word embedding
- ELMO
- GPT
- Bert
- AudioLM: a Language Modeling Approach to Audio Generation
- abstract
- intro
- related work
- VALL-E:Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
- abstract
- speech quantization
- training:conditional codec LM
- AR-codec LM:acoustic prompt
- NAR-codec LM:fine acoustic prompt
NLP中Bert的进展历史
- 从Word Embedding到Bert模型——自然语言处理中的预训练技术发展史
word embedding
- word embedding:每个单词one-hot编码的向量矩阵,在大语言训练之后,该矩阵可以直接提取出来,作为word embedding提取器,用于计算单词的相似度等;其中提取word embedding的方式word2vec的训练有两种:(1)提供上下文,预测目标单词,CBOW(continuous bag-of-word model);(2)当前单词预测前后的单词。
- 缺点:当同一单词有不同含义的时候无法区分
ELMO
- 在word embedding的基础上,对上下文信息进行编码,对于当前单词提供出来的是word embedding, 双向LSTM前向编码的结果,反向编码的结果(其中后两项有比较强的语义信息)。
GPT
- 使用transformer结构,长距离编码的能力显著优于BLSTM
- 但是只提供了前向编码的结果,没有考虑上下文信息
Bert
- 使用transformer结构,且使用了双向编码的结果
- 使用了CBOW的方法,训练的时候,对于一个句子,随机mask一定比例的单词,作为预测目标。(为了避免训练把mask映射,部分mask不是替换成【mask】的方式,而是随机换成其他的单词,或者不做mask)
- in-context学习的能力,对于下游任务,只需要对数据结构作一定的修改,仍然使用此结构,在重多任务上都取得比较好的结果。
AudioLM: a Language Modeling Approach to Audio Generation
abstract
- motivation:生成高质量的音频,且具有长时相关性。speech2speech
- speech量化成discrete tokens,然后恢复成音频。
intro
- 在没有condition的情况下(linguistic features, MIDI seq),即使强如wavenet,也只能生成噪声。
- 之前的方法:使用自监督语言模型方法预训练的模型得到semantic tokens。这些token捕捉了local dependencies(phn, 音乐中局部的旋律),长时特征(speech中的语言句法信息,钢琴曲中的harmony,rhythm)。——重建质量不高。
- 本文:(1)semantic tokens和fine-level acoustic tokens,保证高质量生成和长时依赖。且两部分互为补充(音素信息和生成质量);(2)AudioLM音色复刻:acoustic prompt来自3s unspseech speaker的时候,可以实现音色、韵律以及录制环境的复刻。(3)AudioLM音乐生成:给了prompt之后,可以生成旋律、节奏、乐器音色一致的音乐。(4)为了防止语言延续(speech continuation)滥用,训练一个很高精度的判别器,用于判别语音是否是audioLM生成的。
related work
-
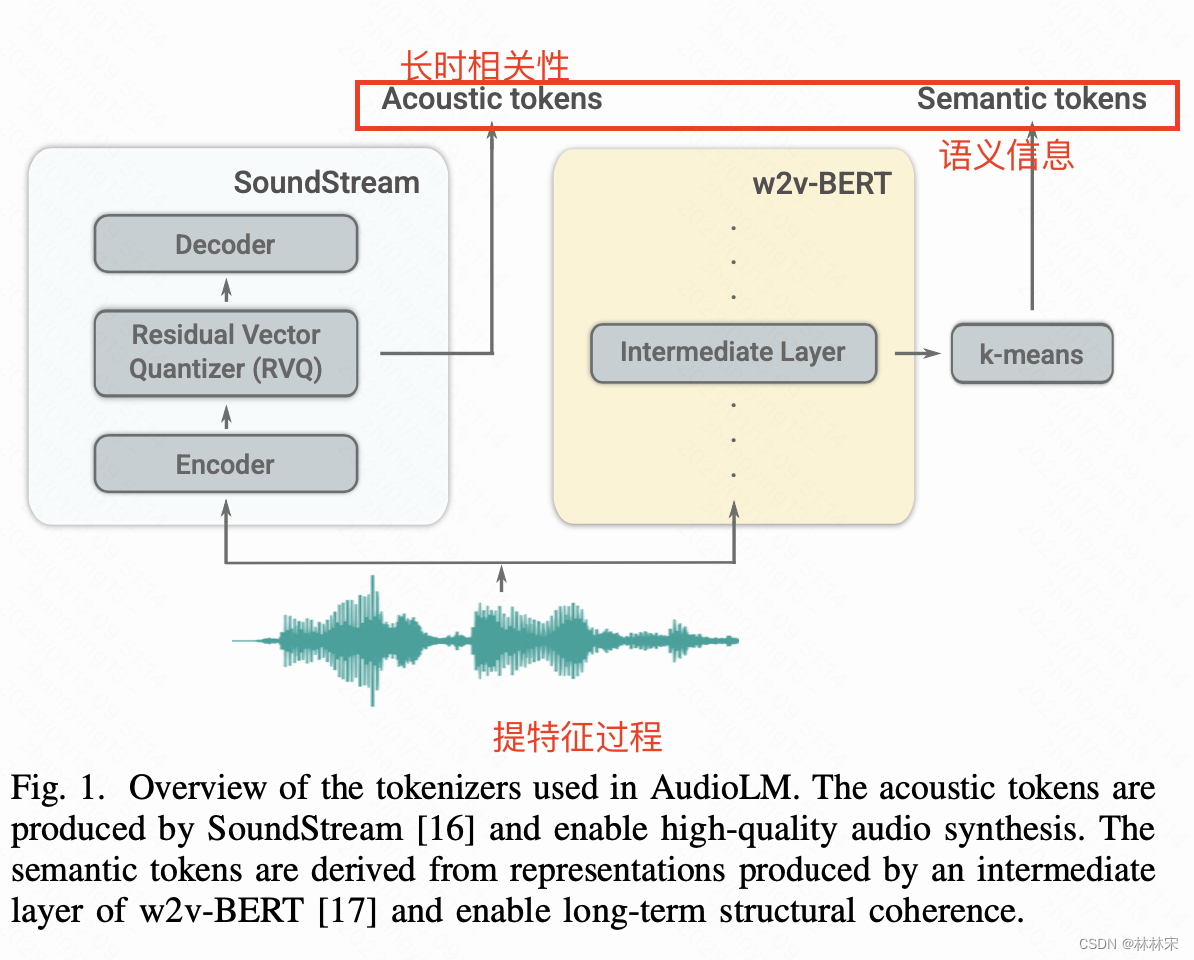
neutral codec:AudioLM使用SoundStream neutral codec提取的tokens(降采样),作为序列建模的target,而且tokens可以被重建为语音。
VALL-E:Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
abstract
- motivation:将大数据训练语言模型的方法引入到TTS中,通过极大的数据量进行in-context learning,使用prompt-based approaches方法做zero-shot TTS
- 效果demo
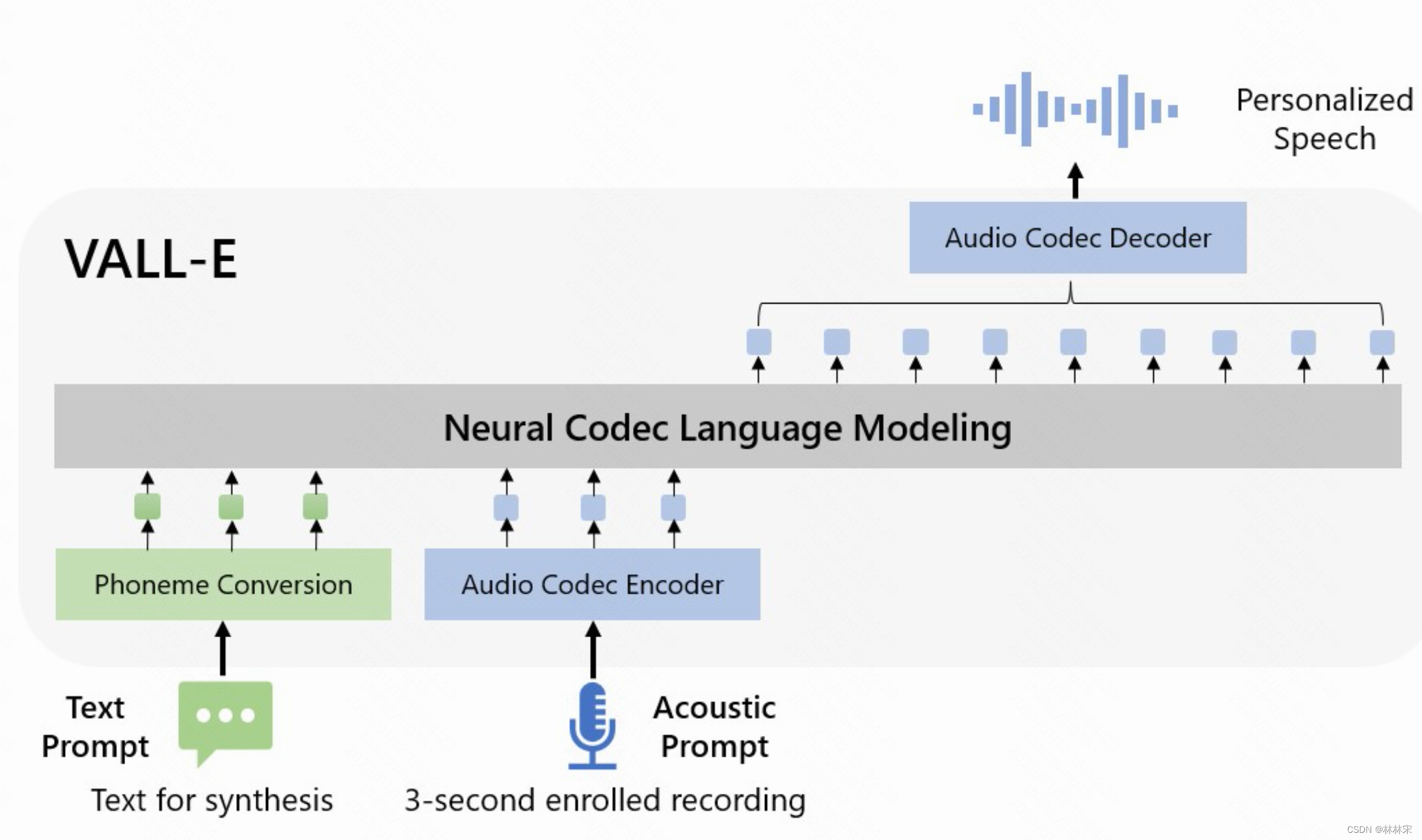
speech quantization
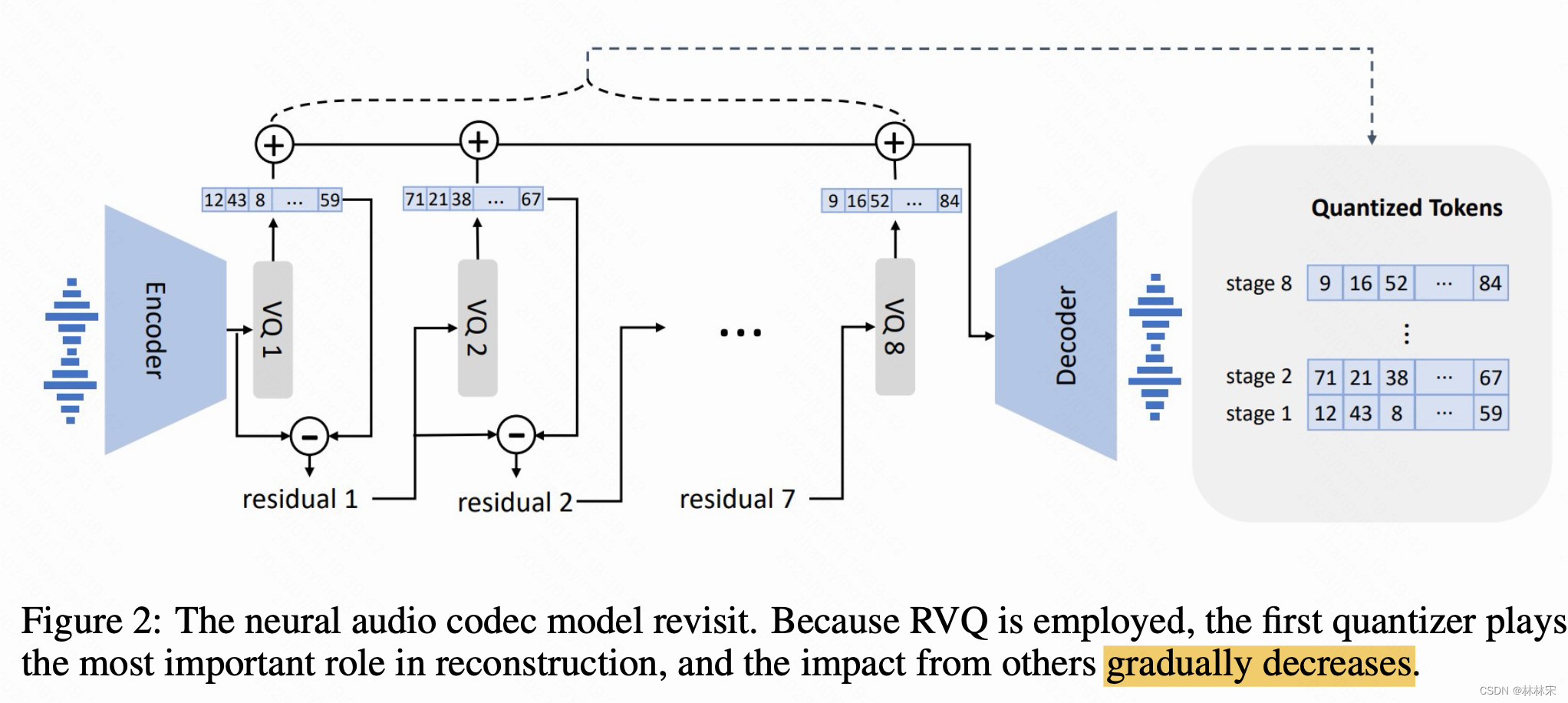
- 使用neutral codec对speech进行量化成离散的tokens,此过程可逆,也可以将discrete tokens反变换成高质量音频。neutral codec相比于其他量化方法优点在于:(1)包含充分的说话人信息和声学信息。(2)有现成的codec decoder,不需要重新训练;(3)相比于 μ − l a w \mu-law μ−law变换,所需的steps更少,效率更高。
- 使用预训练的EnCodec作为tokenizer。输入speech采样率24kHz,经过模型将采样320倍,变成75Hz。模型是8个层级结构的CNN-residualVQ。第一维是global信息(音色,声道),后7维是细粒度的phn以及其他相关的信息,这么说是与使用的预训练模型自己训练时候的8维target提取方式有关(audioLM图,SoudnStream+wav2vecBERT)
- 输入10s的音频,输出是75*10=750 * 8的离散特征矩阵
training:conditional codec LM
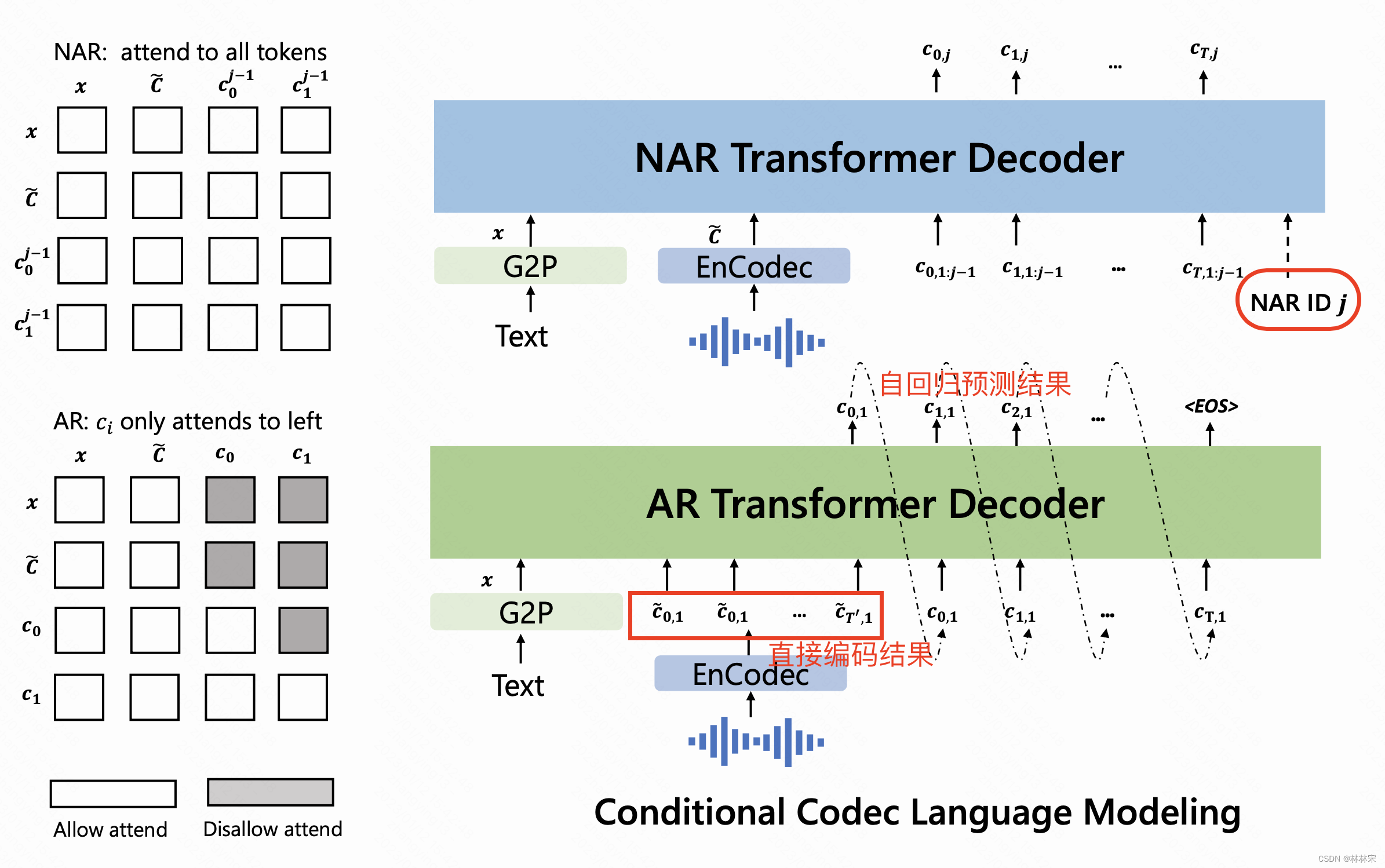
AR-codec LM:acoustic prompt

- phn序列和acoustic prompt拼接,经过AR-transformer序列化的预测 c t c_t ct,时长对齐也是在这个阶段完成的。类似于tacotron。
NAR-codec LM:fine acoustic prompt
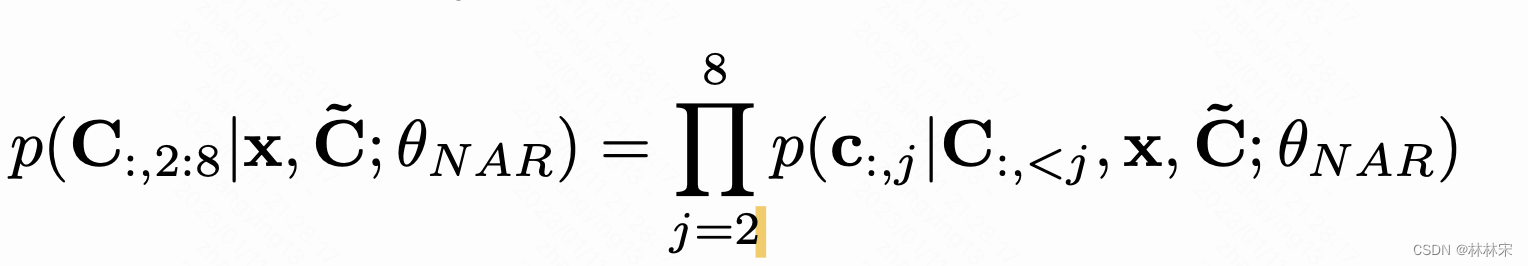
-
对于第i个codec,输入是
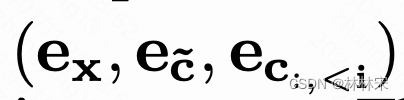
-
其中, e c e_c ec是前(i-1) c i c_i ci和project weight乘积的累加和。

-
预测好的8维codec,送入decodec中,用于波形重建。