《A Neural Span-Based Continual Named Entity Recognition Model》------------AAAI’23
论文链接:https://arxiv.org/abs/2302.12200
代码:https://github.com/Qznan/SpanKL
当前问题:
1.现有的NER模型在适应新的实体类型时往往表现不佳,同时还需要保持对旧实体类型的识别能力。
2.尽管NER的学习范式已经发展到了基于跨度(span-based)的方法等新模式,但这些新方法在持续学习方面的潜力尚未得到充分探索。
解决方法:
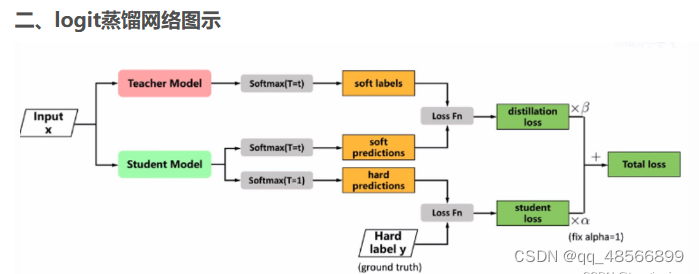
提出的解决方法是SpanKL,这是一个简单而有效的基于跨度的模型,结合了知识蒸馏(KD)和多标签预测来分别解决记忆保持和冲突避免的问题。
知识蒸馏(KD):
用于保留记忆。知识蒸馏是一种模型压缩技术,它允许从一个大型、复杂的模型(教师模型)中提取知识,并将其转移到一个较小、更简单的模型(学生模型)中。在SpanKL中,知识蒸馏被用来保留在先前学习步骤中获得的关于旧实体类型的知识,从而在学习新实体类型时避免遗忘。
多标签预测:
用于防止冲突。在持续学习的场景中,新的实体类型可能与旧的实体类型存在重叠或混淆。多标签预测允许模型为每个输入预测多个可能的标签,从而减少了由于标签冲突导致的错误。
此外,SpanKL还在跨度和实体级别上进行了独立建模,并通过设计的连贯优化来促进每个增量步骤的学习,从而减轻遗忘问题。
实验结果表明,SpanKL在多个方面显著优于先前的最先进模型(SoTA),并且在从持续学习到上限的差距方面获得了最小的差距,显示了其在实际应用中的高价值。
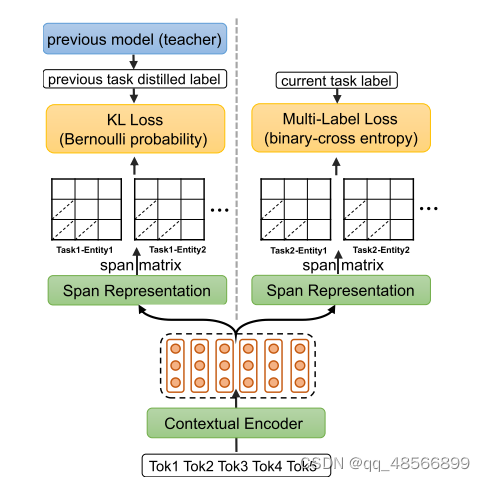
这段文字描述了一个名为“Span Representation Layer”的层,它用于处理自然语言处理中的实体识别任务,特别是针对那些需要识别多个实体类型的场景。以下是该段文字的详细解释:
Span Modeling:
hsij = SpanRep(hi, hi+1, …, hj): 这里描述了一个函数SpanRep,它接受一系列的token表示(从hi到hj)并生成一个span的表示hsij。Span是指文本中的一个连续片段。
不同设计:
文章提到了多种关于如何生成span表示的设计。其中,有些方法特别关注实体的边界token(即实体的开始和结束位置),因为这些token通常包含大量的有用信息。
具体的模型方法:
- Yu, Bohnet, 和 Poesio (2020) 的方法使用biaffine interaction来建模span的开始和结束特征空间。
- Xu et al. (2021) 进一步将实体类型的特征空间建模为多头注意力机制中的“头”。
- Su (2021) 使用多头点积注意力。
本文采用的方法:
本文采用了Su (2021)中的多头点积注意力方法,但在此基础上进行了简化,并在三个特征空间(开始、结束和实体类型)中完全分离了权重。
对于每个实体类型,使用两个独立的单层前馈神经网络(FFN)来分别建模开始和结束位置。总共有2K个不同的FFN(K是实体类型的数量)。
hsij_k = FFNs_k(hi) ⊺ FFNe_k(hj) × (do)^-0.5
这里描述了如何计算span i到j对于第k个实体类型的表示。它首先通过两个FFN处理开始和结束token的表示,然后取它们的点积,并通过do(所有2K个FFN的输出维度)的平方根的倒数进行缩放。
为什么这种设计有效:
文章认为,这种为每个实体类型在每个span上都进行明确分离的建模方式(即在span级别和实体类型级别)有助于学习和蒸馏,并可以减少多个任务之间的干扰。
当任务增加时,只需为新的任务添加更多的span表示层(本质上是内部的FFN)。
总的来说,这段文字描述了一个针对多标签实体识别任务的span建模方法,该方法通过明确分离不同实体类型的权重,旨在提高模型的学习和蒸馏能力,并减少任务之间的干扰。
多标签预测是一种机器学习技术,它允许模型为单个输入样本预测多个类别标签。这在处理复杂问题时特别有用,尤其是当样本可以同时属于多个类别或标签时。
在持续学习(Continual Learning)的场景中,随着新数据的到来,模型需要不断学习新的知识和能力。然而,新的实体类型(如新的类别或概念)可能与之前学习过的旧的实体类型存在重叠或混淆。这可能导致标签冲突,即同一个输入样本根据新的知识和旧的知识可能被赋予不同的标签。
使用多标签预测,模型可以为每个输入预测多个可能的标签。这有助于减少由于标签冲突导致的错误,因为模型可以同时考虑多个可能的解释或分类。例如,如果一个输入样本既可能属于“动物”类别也可能属于“宠物”类别(这两个类别在某种意义上是重叠的),多标签预测允许模型同时为这两个标签赋予较高的预测概率。
在持续学习的上下文中,这意味着当新的实体类型出现时,模型可以更加灵活地处理它们,而不会完全推翻或遗忘之前学习到的关于旧实体类型的知识。这有助于减少灾难性遗忘(Catastrophic Forgetting),这是持续学习中的一个重要挑战。
总之,多标签预测用于防止冲突,在持续学习的场景中允许模型为每个输入预测多个可能的标签,从而减少了由于标签冲突导致的错误,提高了模型的灵活性和适应性。
多教师蒸馏学习是一种特殊的知识蒸馏技术,其核心思想是将多个教师模型的知识结合并传递给学生模型。在这种方法中,不是只有一个教师模型来指导学生模型,而是有多个教师模型共同参与,每个教师模型都为学生模型提供不同的知识和指导。
这种方法可以类比于人类学习的真实场景,比如有两个数学老师,一个擅长微积分问题,另一个擅长立体几何问题。对于一道微积分相关的题目,擅长微积分的老师所传授的知识会更有用;而对于一道立体几何相关的题目,擅长立体几何的老师传授的知识则更为关键。在多教师蒸馏学习的上下文中,不同的教师模型可能擅长处理不同类型的数据或解决不同的子问题,因此它们可以为学生模型提供更为全面和丰富的知识。
为了实现多教师蒸馏学习,需要设计合适的策略来整合多个教师模型的输出,并将其作为学生模型的学习目标。这通常涉及到设计特定的损失函数来衡量学生模型与教师模型之间的差异,并优化学生模型的参数以最小化这种差异。通过这种方式,学生模型可以从多个教师模型中学习到不同的知识,从而提高其性能。
多教师蒸馏学习在多个领域都有应用,特别是在处理复杂任务或需要多样化知识的场景中。它不仅可以提高模型的性能,还可以帮助学生模型更好地适应不同类型的数据和任务。
为了更好地理解持续学习命名实体识别(CL-NER)任务中传统序列标注方法存在的问题以及提出的解决方案,我们可以举一些具体的例子。
传统序列标注方法的问题
假设我们有一个持续学习的NER任务序列,其中第一个任务学习识别组织名称(ORG),第二个任务学习识别人名(PER)。
例子1:
任务1(ORG):文本“小明在北京大学学习”中,“北京大学”是组织名称(ORG)。
任务2(PER):文本“小明在北京大学获得奖学金”中,“小明”是人名(PER)。
在传统序列标注方法中,对于任务1,“小明”会被标注为非实体(O),因为在这个任务中它不属于任何实体类型。然而,在任务2中,“小明”需要被标注为人名(PER)。这种标注的不一致性会导致模型在连续学习过程中频繁更新参数,增加遗忘旧知识的风险。
提出的解决方案
例子2(使用提出的解决方案):
任务1(ORG):文本“小明在北京大学学习”中,“北京大学”被标注为ORG,而“小明”被标注为某种非特定实体的标签,比如O-NON-ORG,表示它当前不是组织名称,但可能是其他类型的实体或仅仅是非实体。
任务2(PER):当处理到任务2时,模型已经知道了“小明”可能是某种实体,现在只需要将其具体化为人名(PER)。因此,模型可以更容易地适应这种变化,而不需要完全重新学习“小明”的标注。
通过这种方式,模型在连续学习过程中能够更好地保留对先前知识的记忆,同时适应新任务的学习。这有助于减少灾难性遗忘的问题,并提高CL-NER任务的性能。
这些例子展示了传统序列标注方法在CL-NER任务中的局限性,以及提出的解决方案如何通过更灵活的标注方式来解决这些问题。
这段文本描述了在持续学习(continual learning)或增量学习(incremental
learning)场景下,如何使用Span Matrix来更好地描述和处理文本中的实体,并如何利用知识蒸馏(Knowledge Distillation)来避免遗忘之前学习到的实体。以下是这段文本的详细解释:
Span Matrix的概念引入:
为了更好地描述,作者引入了Span Matrix的概念。
对于第k个实体类型,所有与之相关的hsij_k(span表示)被组织到矩阵Mk的上三角区域,其中Mk是一个n×n的矩阵。
在矩阵Mk中,行和列分别表示实体的开始和结束位置。
多标签损失层(Multi-Label Loss Layer):
为了确保前向传播的兼容性,作者将最终的span分类制定为多标签预测问题。
对Span Matrix中的预测logits进行sigmoid激活后,计算二元交叉熵(Binary Cross Entropy, BCE)损失与真实标签(golden label)进行比较。
与常用的多分类方法(即使用softmax激活的交叉熵损失)相比,这种方法在将logits归一化为概率时,可以区分不同的实体类型,无论是单个任务还是多个任务。
每个实体类型都进行独立的二分类,BCE损失计算如式(5)所示。
知识蒸馏(Knowledge Distillation):
为了确保后向传播的兼容性,作者使用知识蒸馏来防止忘记旧的实体。
在第l个增量步骤(l > 1)时,首先使用先前学习的模型(教师模型)Ml-1对整个当前训练集Dl进行一次性预测,针对之前步骤学习到的实体类型。
这会产生每个span对于每个旧实体类型的伯努利分布作为软蒸馏标签(soft distilled label)˜p。
这些伪标签用于计算当前模型(学生模型)Ml与伯努利KL散度损失,如式(6)所示。
文本最后提到的“LKD is comp”似乎是一个不完整的句子,可能是指LKD(知识蒸馏损失)的计算方式。
总的来说,这段文本描述了在处理文本实体时,如何使用Span Matrix和多标签损失层来提高模型的准确性和效率,并如何利用知识蒸馏来防止在增量学习过程中忘记之前学习到的知识。