1.为什么学习mysql
mysql是当今最主流且开放源码的关系型数据库,开发者为瑞典 MySQL AB 公司。目前 MySQL 被广泛地应用在 Internet 上的中小型网站中。由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,许多中小型网站为了降低网站总体拥有成本而选择了 MySQL 作为网站数据库。
2. mysql有什么作用?
主要就是数据存储,可以根据对于数据的需求,存储不同类型的数据,诸如下面这几种:
- 用户信息:可以存储诸如用户名、密码等常见的用户信息。
- 库存清单:可以存储商品类别、剩余数量、销售数量等。
- 代码日志:将日志以某种格式存入,方便对日后排查问题做好准备。
- ERP报表:诸如风、水、电能消耗,可存储于数据库中,方便日后做数据分析。
3. 如何使用mysql?
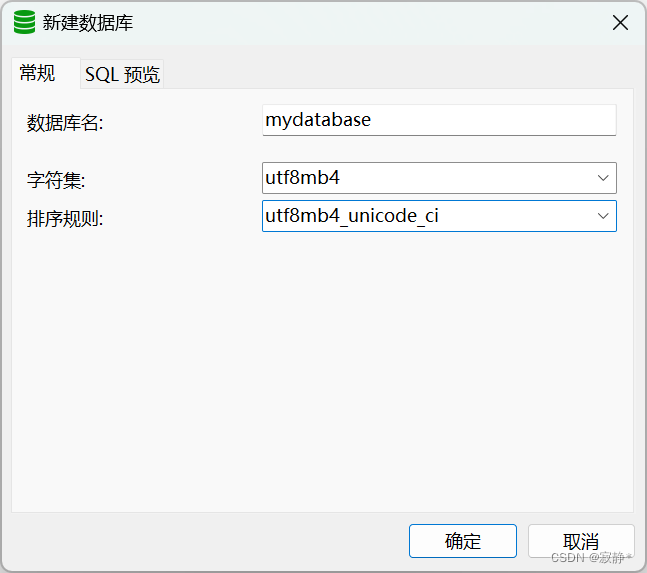
3.1 创建数据库
- 字符集选择utf8mb4:大小写不敏感,支持Unicode字符,可存储表情,适用于多语言环境。
- 排序规则选择utf8mb4_unicode_ci:大小写不敏感,支持Unicode字符,适用于多语言环境。
可使用sql或数据库工具直接创建
CREATE DATABASE
mydatabaseCHARACTER SET ‘utf8mb4’ COLLATE ‘utf8mb4_unicode_ci’;
3.2 创建表
3.2.1 创建最经典的学生表、课程表、选课表
CREATE TABLE students (
student_id INT PRIMARY KEY COMMENT '学生ID',
name VARCHAR(50) COMMENT '姓名',
age INT COMMENT '年龄',
gender INT COMMENT '性别',
email VARCHAR(50) COMMENT '邮箱'
);
CREATE TABLE courses (
course_id INT PRIMARY KEY COMMENT '课程ID',
course_name VARCHAR(50) COMMENT '课程名称',
instructor VARCHAR(50) COMMENT '授课教师',
credits INT COMMENT '学分'
);
CREATE TABLE student_courses (
student_id INT COMMENT '学生ID',
course_id INT COMMENT '课程ID',
PRIMARY KEY (student_id, course_id)
);
3.2.2 插入数据
-- 学生表插入语句
INSERT INTO students (student_id, name, age, gender, email) VALUES (1, 'Alice', 20, 1, 'alice@example.com');
INSERT INTO students (student_id, name, age, gender, email) VALUES (2, 'Bob', 22, 0, 'bob@example.com');
INSERT INTO students (student_id, name, age, gender, email) VALUES (3, 'Charlie', 21, 1, 'charlie@example.com');
INSERT INTO students (student_id, name, age, gender, email) VALUES (4, 'David', 23, 0, 'david@example.com');
INSERT INTO students (student_id, name, age, gender, email) VALUES (5, 'Eve', 19, 1, 'eve@example.com');
-- 课程表插入语句
INSERT INTO courses (course_id, course_name, instructor, credits) VALUES (1, 'Mathematics', 'Smith', 3);
INSERT INTO courses (course_id, course_name, instructor, credits) VALUES (2, 'Physics', 'Johnson', 4);
INSERT INTO courses (course_id, course_name, instructor, credits) VALUES (3, 'Chemistry', 'Williams', 3);
INSERT INTO courses (course_id, course_name, instructor, credits) VALUES (4, 'Biology', 'Jones', 4);
INSERT INTO courses (course_id, course_name, instructor, credits) VALUES (5, 'History', 'Brown', 3);
INSERT INTO courses (course_id, course_name, instructor, credits) VALUES (6, 'English', 'Davis', 3);
INSERT INTO courses (course_id, course_name, instructor, credits) VALUES (7, 'Computer Science', 'Miller', 4);
-- 学生选择课程关联表插入语句
INSERT INTO student_courses (student_id, course_id) VALUES (1, 1);
INSERT INTO student_courses (student_id, course_id) VALUES (1, 2);
INSERT INTO student_courses (student_id, course_id) VALUES (1, 3);
INSERT INTO student_courses (student_id, course_id) VALUES (2, 2);
INSERT INTO student_courses (student_id, course_id) VALUES (2, 4);
INSERT INTO student_courses (student_id, course_id) VALUES (2, 6);
INSERT INTO student_courses (student_id, course_id) VALUES (3, 1);
INSERT INTO student_courses (student_id, course_id) VALUES (3, 3);
INSERT INTO student_courses (student_id, course_id) VALUES (3, 5);
INSERT INTO student_courses (student_id, course_id) VALUES (4, 4);
INSERT INTO student_courses (student_id, course_id) VALUES (4, 5);
INSERT INTO student_courses (student_id, course_id) VALUES (4, 6);
INSERT INTO student_courses (student_id, course_id) VALUES (5, 1);
INSERT INTO student_courses (student_id, course_id) VALUES (5, 2);
INSERT INTO student_courses (student_id, course_id) VALUES (5, 7);
3.3 查询
3.3.1 关键字的执行顺序
FROM:指定要从哪张表查询数据。
WHERE:对表中的数据进行筛选。
GROUP BY:将数据按指定列进行分组。
HAVING:对分组后的数据进行筛选,与聚合函数连用,可针对group by的列或是聚合函数的列。
SELECT:选择要查询的列。
DISTINCT:去除重复的行。
ORDER BY:对查询结果进行排序。
LIMIT:限制返回的行数。
注:having后面不可以跟普通的列,可以跟group by的列或是聚合函数的列,且having必须和group by连用。
3.3.2 关键字书写顺序
SELECT:指定要查询的列或表达式。
FROM:指定要查询的表。
JOIN:指定要连接的表。
WHERE:对行级数据进行条件筛选。
GROUP BY:按指定列对结果进行分组。
HAVING:对分组后的数据进行条件筛选。
ORDER BY:指定结果的排序方式。
LIMIT:限制返回的行数。
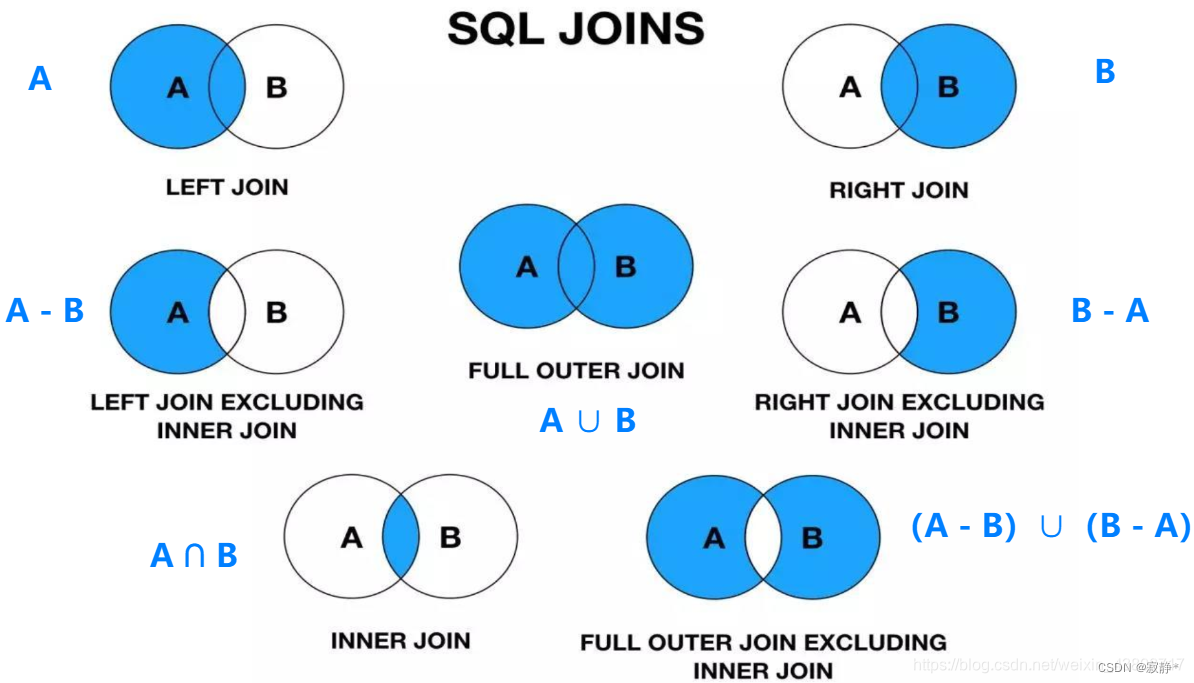
3.3.3 mysql的join
3.3.4. DISTINCT
DISTINCT : 去重,从上至下扫描,找到第一条不同的数据进行返回,而我们主要根据某一列进行操作。
原表:
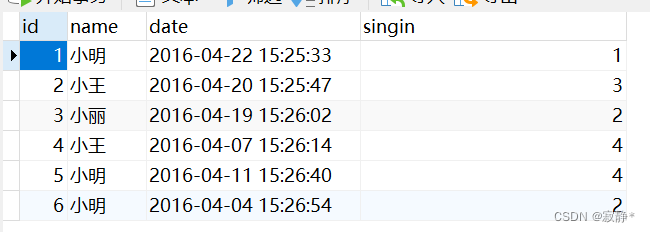
执行去重sql
SELECT DISTINCT singin
FROM employee_tbl

注意:这样写distinct会失效
SELECT DISTINCT singin , id,name,date
FROM employee_tbl
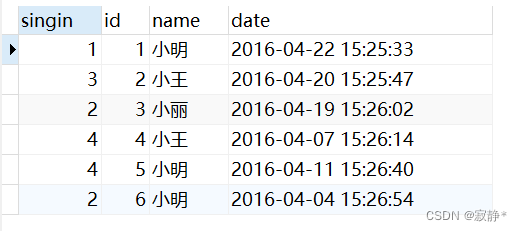
3.4.5 ORDER BY
根据指定的列对结果集进行排序,默认升序 ORDER BY 列名 ASC(asc可以不写),降序 ORDER BY 列名 DESC(des也可)
可以单独使用,不需要与group by连用
3.4.6 GROUP BY
针对某一列进行分组,从上至下扫描,找到符合条件的行返回,只返回第一条不同的数据
原表:
执行分组
SELECT *
FROM employee_tbl
GROUP BY singin
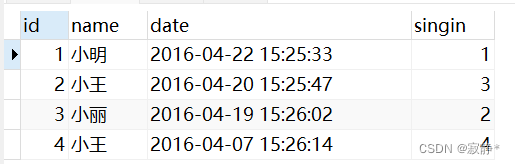
3.4.7 LIMIT
LIMIT m, n : 从第 m + 1 行开始取 n 条记录(m从0开始)
Limit m :取几条数据
Limit m offset n:取m条数据,但需从0行开始向后偏移n行
原表:
执行limit
SELECT *
FROM employee_tbl
LIMIT 1,3
SELECT *
FROM employee_tbl
LIMIT 3 OFFSET 1
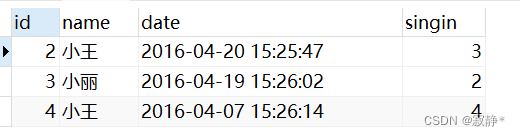
3.4.8 in和exist
in : 子查询的到一部分数据,在主查询中是否有数据能和子查询匹配
exist:判断某些数据是否存在与子查询中
in是将外表和内表做hash连接,适用于外表大内表小的情况
exist是对外表做loop循环,每次都会对内表重新查询,所以适用于外表小内表大的情况
注意:对于not in 和 not exist而言,not in 的内表需要全表扫描,而not exist还可以走索引,所以使用not exist更佳。