目录
下载Pytorch
入门尝试
几种常见的Tensor
Scalar
Vector
Matrix
AutoGrad机制
线性回归尝试
使用hub模块
Pytorch是重要的人工智能深度学习框架。既然已经点进来,我们就详细的介绍一下啥是Pytorch
PyTorch
-
希望将其代替 Numpy 来利用 GPUs 的威力;
-
一个可以提供更加灵活和快速的深度学习研究平台。
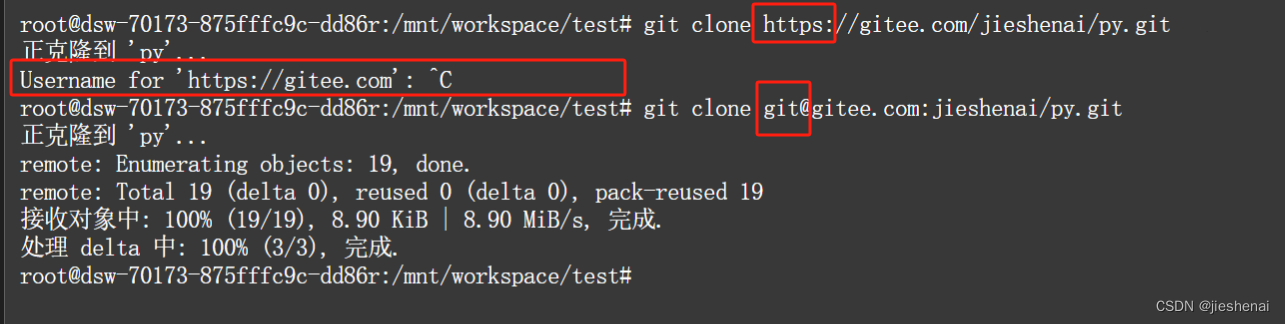
下载Pytorch
不必着急担心我们下啥版本,Pytorch官网已经给出了一个良好的解决方案:

请根据自己的网站给出的方案进行选择!不要抄我的!
可以复制到Pycharm中,确定好自己的虚拟环境之后,就可以愉快的在终端执行网站推介的配置.
可以在Package包中选择自己的包管理:如果你的环境是conda环境,我个人推介使用conda来下(方便管理)
等待半个小时,我们下好了之后,,就可以使用这个代码跑一下:
在Pycharm的Python控制台上
import torch torch.__version__
之后我们将会在控制台上尝试我们的代码,这里就不赘述了
入门尝试
我们随意的试一试一些API:
我们可以很轻松的创建一个矩阵:
torch.empty — PyTorch 2.2 documentation
x = torch.empty(5, 3) x
tensor([[1.4767e+20, 1.6816e-42, 0.0000e+00], [0.0000e+00, 0.0000e+00, 0.0000e+00], [0.0000e+00, 0.0000e+00, 0.0000e+00], [0.0000e+00, 0.0000e+00, 0.0000e+00], [0.0000e+00, 0.0000e+00, 0.0000e+00]])
我们就会创建一个给定大小的torch:他的值是未初始化的(你可以反复执行查看结果,你会发现结果可能每一次都会发生变化)
我们可以很轻松的创建一个随机矩阵:
torch.rand — PyTorch 2.2 documentation
x = torch.rand(5, 3) x
tensor([[0.7140, 0.1131, 0.6945], [0.8082, 0.6078, 0.5954], [0.9646, 0.6500, 0.8988], [0.4161, 0.1819, 0.3053], [0.1953, 0.3988, 0.9033]])
由此可见,他会随机的生成一些介于0和1之间的随机值
torch.zeros — PyTorch 2.2 documentation
x = torch.zeros(5, 3, dtype=torch.long) x
将返回给我们一个全0的矩阵
我们还可以升级已有的数组结构:
torch.tensor — PyTorch 2.2 documentation
x = torch.tensor([5.5, 3]) x
tensor([5.5000, 3.0000])
当然可以使用size查看torch的大小
x.size()
还可以对之进行简单的操作:
y = torch.rand(5, 3) x + y # 等价操作:torch.add(x, y)
tensor([[1.1685, 1.4813, 1.1385], [1.4541, 1.4664, 1.4721], [1.5987, 1.1817, 1.3344], [1.2923, 1.8951, 1.8134], [1.8740, 1.7830, 1.7349]], dtype=torch.float64)
还可以同一般的Python那样进行索引
print(x) x[:, 1]
tensor([[1., 1., 1.], [1., 1., 1.], [1., 1., 1.], [1., 1., 1.], [1., 1., 1.]], dtype=torch.float64) tensor([1., 1., 1., 1., 1.], dtype=torch.float64)
还可以变换维度
torch.Tensor.view — PyTorch 2.2 documentation
PyTorch中的view( )函数相当于numpy中的resize( )函数,都是用来重构(或者调整)张量维度的,用法稍有不同。
x = torch.randn(4, 4) y = x.view(16) z = x.view(-1, 8) print(x.size(), y.size(), z.size())
还支持同其他库的协同操作:
a = torch.ones(5) b = a.numpy() b
array([1., 1., 1., 1., 1.], dtype=float32)
import numpy as np a = np.ones(5) b = torch.from_numpy(a) b
tensor([1., 1., 1., 1., 1.], dtype=torch.float64)
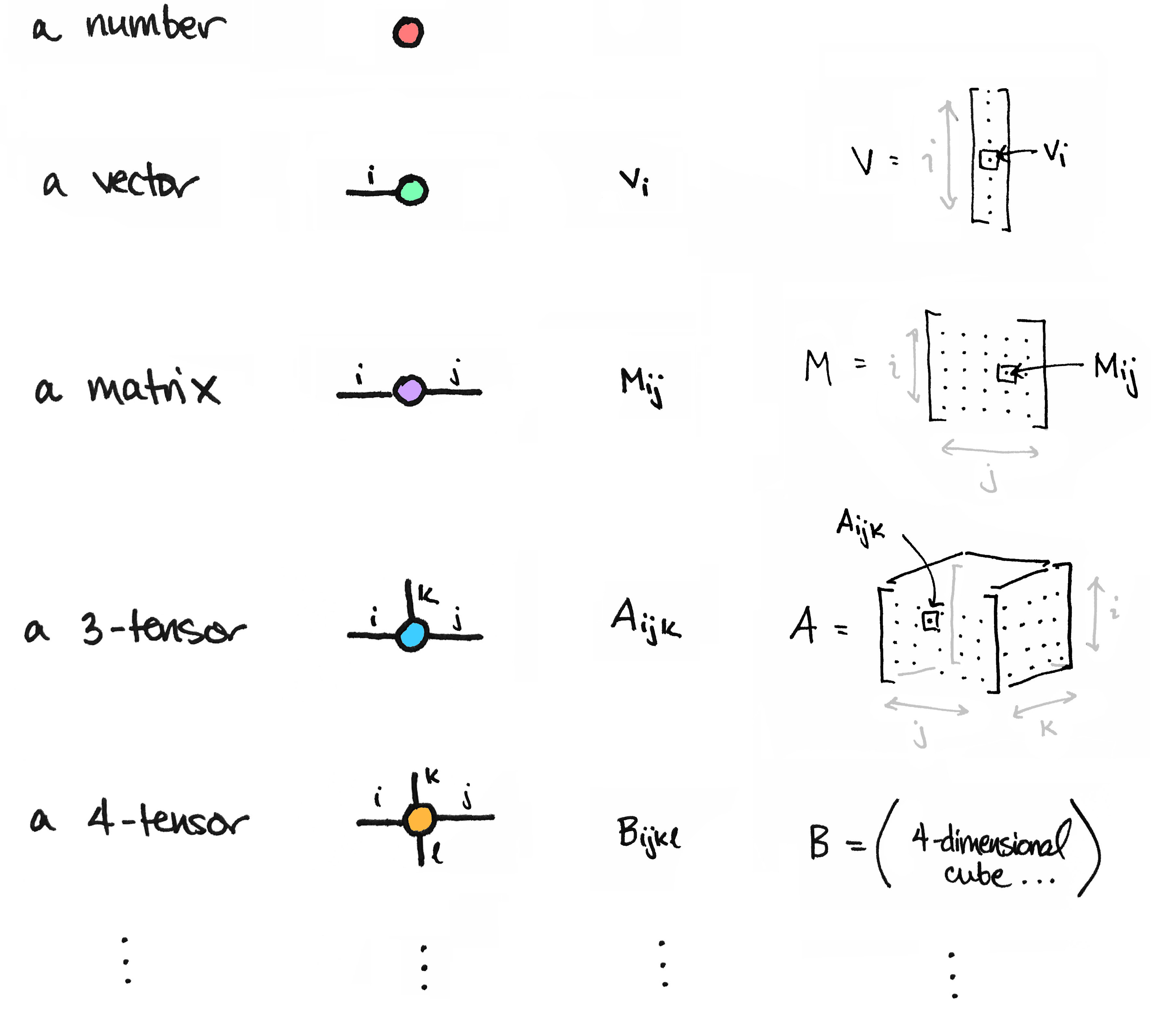
几种常见的Tensor
torch.Tensor — PyTorch 2.2 documentation
我们的Tensor叫张量,回忆线性代数,我们的张量有维度,我们的维度可以从0上升到:
0: scalar # 标量 1: vector # 向量 2: matrix 3: n-dim tensor
Scalar
通常就是一个数值:
x = tensor(42.) x
你就会发现结果实际上就是封装起来的一个数字:
tensor(42.)
使用dim方法可以查看这个张量的维度:
x.dim()
0
可以简单使用标量乘法,跟线性代数定义的乘法完全一致:
2 * x
tensor(84.)
对于标量,我们可以使用item方法提取里面的值
x.item()
但是建议判断item的维度选用这个方法,因为对于向量,这个方法会抛error
y = torch.tensor([3, 4]) y.item() --------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) Cell In[9], line 2 1 y = torch.tensor([3, 4]) ----> 2 y.item() RuntimeError: a Tensor with 2 elements cannot be converted to Scalar
Vector
例如: [-5., 2., 0.],在深度学习中通常指特征,例如词向量特征,某一维度特征等
Matrix
我们深度学习的计算多涉及矩阵:
M = tensor([[1., 2.], [3., 4.]]) M
tensor([[1., 2.], [3., 4.]])
矩阵可以进行矩阵乘法,但是要求满足线性代数下矩阵的乘法规则:
N = tensor([1, 2, 3]) M.matmul(N)
--------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) Cell In[12], line 2 1 N = tensor([1, 2, 3]) ----> 2 M.matmul(N) RuntimeError: size mismatch, got input (2), mat (2x2), vec (3)
AutoGrad机制
深度解析 PyTorch Autograd:从原理到实践 - 知乎 (zhihu.com)
Pytorch autograd,backward详解 - 知乎 (zhihu.com)
参考这两个博客,我来写写我的理解。我们构建的是基于张量的函数算子:
$$
f = f(X, Y, Z, ...)
$$
现在,我们需要求导,首先就要思考,对于多张量的函数,跟多变量函数一样,一些变量是我们这次运算中需要被求导的,一些不是,这样,我们就需要使用Tensor的required_grad参数机制:
x = torch.randn(3,4,requires_grad=True) x
这样我们的x在后续参与函数运算的时候,在我们反向传播的时候就会参与求导运算。
一些参数的解释
-
data: 即存储的数据信息 -
requires_grad: 设置为True则表示该Tensor需要求导 -
grad: 该Tensor的梯度值,每次在计算backward时都需要将前一时刻的梯度归零,否则梯度值会一直累加,这个会在后面讲到。 -
grad_fn: 叶子节点通常为None,只有结果节点的grad_fn才有效,用于指示梯度函数是哪种类型。例如上面示例代码中的y.grad_fn=<PowBackward0 at 0x213550af048>, z.grad_fn=<AddBackward0 at 0x2135df11be0> -
is_leaf: 用来指示该Tensor是否是叶子节点。
现在我们引入函数算子:
b = torch.randn(3,4,requires_grad=True) # print(b) t = x + b t
我们实际上完成的是两个张量的相加,现在我们就知道,t作为一个结果,发生了两个张量的相加:
tensor([[ 1.2804, -1.8381, 0.0068, -0.3126], [-0.4901, 1.5733, -1.1383, 1.4996], [ 1.9931, -0.7548, -1.1527, -1.1703]], grad_fn=<AddBackward0>)# 看后面这个,这个说明稍后我们反向传播的时候使用AddBackward算子
使用y.backward()进行反向传播,这个时候,我们如何查看参与运算的张量的梯度呢,答案是:
print(x.grad) print(b.grad)
可以注意到:我们求一次y.backward(),这个结果就会累加一次。
注意到,一些张量不是我们定义出来的而是算出来的,代表性的就是t,反之剩下的是参与基础运算的x和b
print(x.is_leaf, b.is_leaf, t.is_leaf) True True False
这样我们就不会对叶子向量求导了!他们就是基础的变量。
线性回归尝试
啥是线性回归呢,我的理解是:使用线性的函数(如果不理解,那就是y = kx + b)拟合数据。我们从简单的线性拟合来。
生成一组(x, y)对
import numpy as np x_values = [i for i in range(11)] x_train = np.array(x_values, dtype=np.float32) x_train = x_train.reshape(-1, 1) x_train.shape x_train
array([[ 0.], [ 1.], [ 2.], [ 3.], [ 4.], [ 5.], [ 6.], [ 7.], [ 8.], [ 9.], [10.]], dtype=float32)
y_values = [2*i + 1 for i in x_values] y_train = np.array(y_values, dtype=np.float32) y_train = y_train.reshape(-1, 1) y_train.shape y_train
array([[ 1.], [ 3.], [ 5.], [ 7.], [ 9.], [11.], [13.], [15.], [17.], [19.], [21.]], dtype=float32)
现在我们使用torch框架下的线性回归:
import torch import torch.nn as nn
class LinearRegressionModel(nn.Module): def __init__(self, input_dim, output_dim): super(LinearRegressionModel, self).__init__() self.linear = nn.Linear(input_dim, output_dim) def forward(self, x): out = self.linear(x) # 向前传播 return out
这样我们就完成了一个最简单的模型
input_dim = 1 output_dim = 1 model = LinearRegressionModel(input_dim, output_dim) model
LinearRegressionModel( (linear): Linear(in_features=1, out_features=1, bias=True) )
epochs = 1000 # 训练论数 learning_rate = 0.01 # 学习速率 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) # 随机梯度下降 criterion = nn.MSELoss() # 正则化惩罚系数
在这里我们进行训练
for epoch in range(epochs):
epoch += 1
# 注意转行成tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
# 梯度要清零每一次迭代
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 返向传播
loss.backward()
# 更新权重参数
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
我们可以这样得到预测的值:
predicted = model(torch.from_numpy(x_train).requires_grad_()).data.numpy() predicted
如何存取模型呢:
torch.save(model.state_dict(), 'model.pkl')
model.load_state_dict(torch.load('model.pkl'))
也可以使用GPU训练
import torch
import torch.nn as nn
import numpy as np
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
input_dim = 1
output_dim = 1
model = LinearRegressionModel(input_dim, output_dim)
# 在这里,直接扔到GPU就行
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = nn.MSELoss()
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 1000
for epoch in range(epochs):
epoch += 1
inputs = torch.from_numpy(x_train).to(device)
labels = torch.from_numpy(y_train).to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
使用hub模块
torch.hub — PyTorch 2.2 documentation
Pytorch Hub是一个帮助研究者实现模型再现、快速推理验证的预训练模型库与一套相关的API框架。支持远程从github上下载指定模型、上传与分享训练好的模型、支持从本地加载预训练模型、自定义模型。支持模型远程加载与本地推理、当前Pytorch Hub已经对接到Torchvision、YOLOv5、YOLOv8、pytorchvideo等视觉框架
人话:我们可以直接在操作这些API直接嫖设置好的模型直接用。
我们可以前往Pytorch Hub尝试,搜索你感兴趣的模型:来个例子,我们对deeplabv3_resnet101,就可以搜索到Tutorial:
Deeplabv3 | PyTorch
import torch
model = torch.hub.load('pytorch/vision:v0.10.0', 'deeplabv3_resnet50', pretrained=True)
# or any of these variants
# model = torch.hub.load('pytorch/vision:v0.10.0', 'deeplabv3_resnet101', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.10.0', 'deeplabv3_mobilenet_v3_large', pretrained=True)
model.eval()
这个时候他会下载模型(默认保存在用户文件夹下的C:/User/.cache/torch/下)
之后下载数据集:
# Download an example image from the pytorch website
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/deeplab1.png", "deeplab1.png")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
如果网络不好,请手动到地址下载!放到指定位置
然后处理它:
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
# 定义transform算子
input_image = Image.open(filename)
input_image = input_image.convert("RGB")
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 预处理
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)['out'][0]
output_predictions = output.argmax(0)
查看效果如何
# create a color pallette, selecting a color for each class
palette = torch.tensor([2 ** 25 - 1, 2 ** 15 - 1, 2 ** 21 - 1])
colors = torch.as_tensor([i for i in range(21)])[:, None] * palette
colors = (colors % 255).numpy().astype("uint8")
# plot the semantic segmentation predictions of 21 classes in each color
r = Image.fromarray(output_predictions.byte().cpu().numpy()).resize(input_image.size)
r.putpalette(colors)
import matplotlib.pyplot as plt
plt.imshow(r)
plt.show()
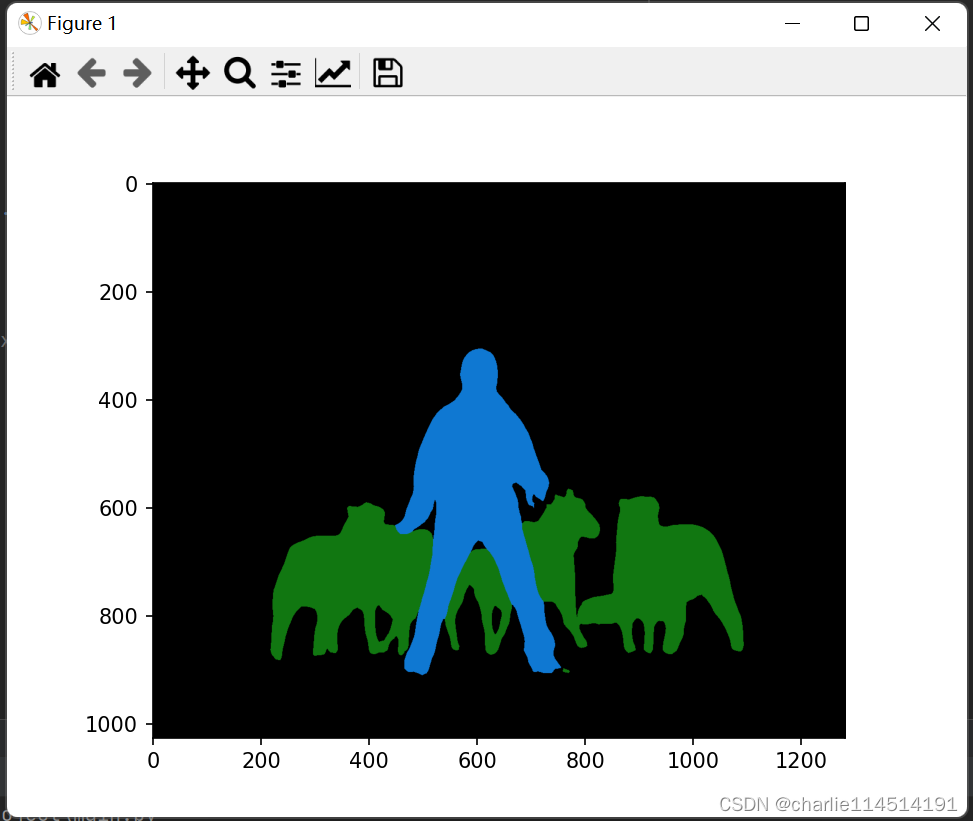
分类成功。