目录
-
- 一、摘要
- 二、正文
-
- 2.1 环境说明
- 2.2 网络拓扑
- 2.3 Hadoop副本放置策略介绍
- 2.4 解析EditLog和Fsimage镜像文件
- 三、小结
一、摘要
通过解析存储于NameNode节点上的日志文件EditLog和镜像文件(元数据)Fsimage来反向验证HDFS的数据块副本存放策略,其目的是希望加深对Hadoop的数据块放置策略的理解以及掌握如何查看日志文件及镜像文件的方法和理解其内容。
二、正文
2.1 环境说明
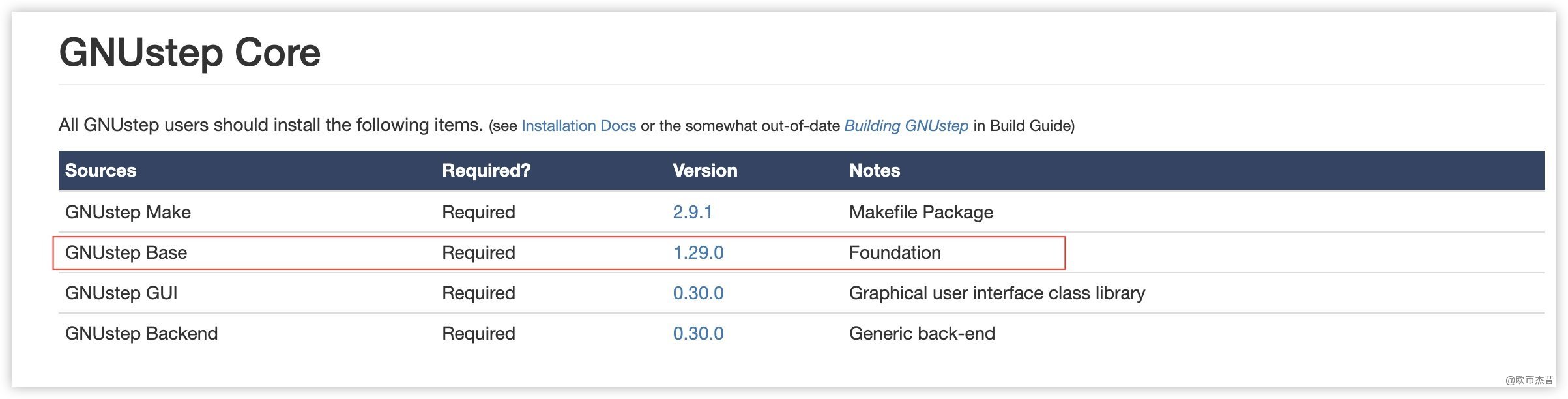
| 软件 | 说明 |
|---|---|
| VMWareWorkstation | 版本16.2.+ |
| MobXterm | 远程连接工具 |
| Hadoop | 版本3.3.6 |
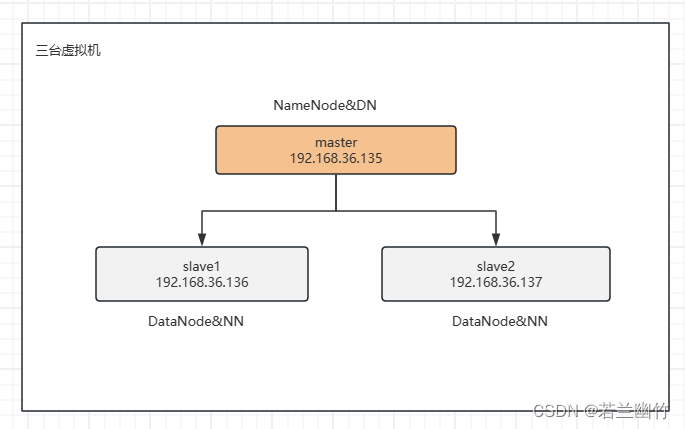
2.2 网络拓扑
2.3 Hadoop副本放置策略介绍
-
副本放置机制的意义
复制副本的放置对HDFS的可靠性和性能至关重要。优化复制副本放置将HDFS与大多数其他分布式文件系统区别开来。这是一个需要大量调整和经验的功能。机架感知复制副本放置策略的
目的是提高数据的可靠性、可用性和网络带宽利用率。复制副本放置策略的当前实现是朝着这个方向迈出的第一步。实施此策略的短期目标是在生产系统上对其进行验证,了解更多关于其行为的信息,并为测试和研究更复杂的策略奠定基础。
大型HDFS实例在通常分布在许多机架上的计算机集群上运行。不同机架中的两个节点之间的通信必须通过交换机。在大多数情况下,同一机架中机器之间的网络带宽大于不同机架中机器间的网络带宽。
NameNode通过Hadoop rack Awareness中概述的过程确定每个DataNode所属的机架id。一个简单但非最优的策略是将复制副本放置在唯一的机架上。这样可以防止整个机架出现故障时丢失数据,并允许在读取数据时使用多个机架的带宽。此策略在群集中均匀分布复制副本,从而可以轻松平衡组件故障时的负载。但是,此策略增加了写入成本,因为写入需要将块传输到多个机架。 -
副本放置机制原理
对于常见情况,
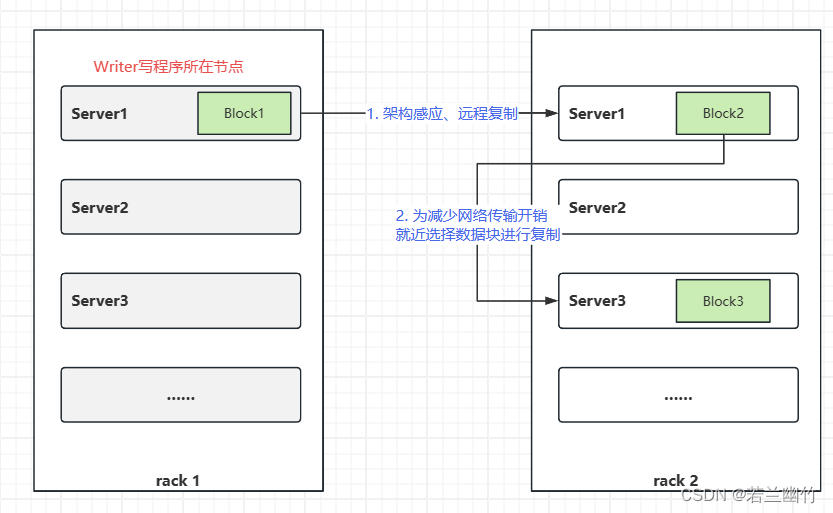
当复制因子为3时,HDFS的放置策略是,如果写入程序位于数据节点上,则将一个副本放置在本地机器上,否则放置在与写入程序位于同一机架中的随机数据节点上、另一个副本放在不同(远程)机架中的节点上,最后一个副本则放在同一远程机架中的不同节点上。此策略可减少机架间写入流量,这通常会提高写入性能。机架故障的几率远小于节点故障的几率;此策略不会影响数据的可靠性和可用性保证。然而,它并没有减少读取数据时使用的聚合网络带宽,因为块只放置在两个唯一的机架中,而不是三个。使用此策略,块的副本不会均匀分布在机架上。两个复制副本位于一个机架的不同节点上,其余复制副本位于其他机架之一的节点上。此策略在不影响数据可靠性或读取性能的情况下提高了写入性能。如果复制系数大于3,则随机确定第4个和以下复制副本的位置,同时将每个机架的复制副本数量保持在上限以下
(基本上为(复制副本-1)/机架+2)。因为NameNode不允许DataNodes具有同一块的多个副本,所以创建的最大副本数是当时DataNodes的总数。在HDFS中添加了对存储类型和存储策略的支持后,除了上述机架意识之外,NameNode还考虑了复制副本放置的策略。NameNode首先根据机架感知来选择节点,然后检查候选节点是否具有与文件相关联的策略所需的存储空间。如果候选节点没有存储类型,则NameNode会查找另一个节点。如果在第一个路径中找不到足够的节点来放置副本,则NameNode会在第二个路径中查找具有后备存储类型的节点。
总之,当复制因子为3时,HDFS的放置策略是,如果写入程序位于数据节点上,则将一个副本放置在本地机器上,否则放置在与写入程序相同机架中的随机数据节点上、另一个副本放在不同(远程)机架中的节点上,最后一个副本则放置在同一远程机架中的不同节点上。如果复制系数大于3,则随机确定第4个和以下复制副本的位置,同时将每个机架的复制副本数量保持在上限以下(基本上为(复制副本-1)/机架+2)。除此之外,HDFS还支持4种不同的可插拔块放置策略。用户可以根据其基础结构和用例选择策略。
以下为3副本策略时的副本放置策略示例图:
-
副本的选择
为了最大限度地减少全局带宽消耗和读取延迟,HDFS尝试满足来自最接近服务器读取副本的请求。如果在与该节点相同的机架上存在复制副本,则首选该复制副本来满足读取请求。如果HDFS集群跨越多个数据中心,那么驻留在本地数据中心的复制副本优先于任何远程复制副本。
2.4 解析EditLog和Fsimage镜像文件
-
EditLog文件:
editlog主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。该文件记录了集群运行期间所有对HDFS的相关操作。
-
Fsimage文件:
fsimage保存了最新的元数据检查点,在HDFS启动时加载fsimage的信息,包含了整个HDFS文件系统的所有目录和文件的信息。
对于文件来说包括了数据块描述信息、修改时间、访问时间等。
对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。 -
EditLog和Fsimage的主要作用:
Fsimage,editlog主要用于在集群启动时将集群的状态恢复到关闭前的状态。为了达到这个目的,集群启动时将Fsimage、editlog加载到内存中,进行合并,合并后恢复完成。
-
实验与解析
为了测试方便,以下是在新安装的hadoop3.3.6全分布式环境上(具体安装请参考博文:Hadoop3.3.6全分布式环境搭建)所在的操作:-
登录到NameNode所在节点
-
创建HDFS的目录testdatas
hdfs dfs -mkdir /testdatas -
上传hadoop-3.3.6.tar.gz到testdatas目录下
上传前先查看hadoop-3.3.6.tar.gz文件大小
[root@master ~]# ls -lh -rw-r--r--. 1 root root 697M Apr 20 21:33 hadoop-3.3.6.tar.gz [root@master ~]#以数据块128M来计算下数据块总数:697M/128M = 5.4,即该文件上传到HDFS上时会被分成6个数据块。执行如下命令开始上传:
hdfs dfs -put hadoop-3.3.6.tar.gz /testdatas -
解析EditLog文件
由于EditLog是二进制文件无法直接打开查看和阅读,需要使用hdfs命令将其转换成可阅读的文件格式再进行阅读,具体执行如下命令进行文件格式的转换:[root@master ~]# cd /opt/software/hadoop-3.3.6/tmp/dfs/name/current/ hdfs oev -i edits_inprogress_0000000000000000008 -o ./edits_inprogress.xml查看转换后的文件
edits_inprogress.xml
文件内容如下:<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <EDITS> <EDITS_VERSION>-66</EDITS_VERSION> <RECORD> <OPCODE>OP_START_LOG_SEGMENT</OPCODE> <DATA> <TXID>8</TXID> </DATA> </RECORD> <RECORD> <OPCODE>OP_MKDIR</OPCODE> <DATA> <TXID>9</TXID> <LENGTH>0</LENGTH> <INODEID>16386</INODEID> <PATH>/testdatas</PATH> <TIMESTAMP>1713672689223</TIMESTAMP> <PERMISSION_STATUS> <USERNAME>root</USERNAME> <GROUPNAME>supergroup</GROUPNAME> <MODE>493</MODE> </PERMISSION_STATUS> </DATA> </RECORD> <RECORD> <OPCODE>OP_ADD</OPCODE> <DATA> <TXID>10</TXID> <LENGTH>0</LENGTH> <INODEID>16387</INODEID> <PATH>/testdatas/hadoop-3.3.6.tar.gz._COPYING_</PATH> <REPLICATION>3</REPLICATION> <MTIME>1713672994012</MTIME> <ATIME>1713672994012</ATIME> <BLOCKSIZE>134217728</BLOCKSIZE> <CLIENT_NAME>DFSClient_NONMAPREDUCE_268238562_1</CLIENT_NAME> <CLIENT_MACHINE>192.168.85.128</CLIENT_MACHINE> <OVERWRITE>true</OVERWRITE> <PERMISSION_STATUS> <USERNAME>root</USERNAME> <GROUPNAME>supergroup</GROUPNAME> <MODE>420</MODE> </PERMISSION_STATUS> <ERASURE_CODING_POLICY_ID>0</ERASURE_CODING_POLICY_ID> <RPC_CLIENTID>4b339db6-64fe-4703-8e53-6a510784e347</RPC_CLIENTID> <RPC_CALLID>3</RPC_CALLID> </DATA> </RECORD> <RECORD> <OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE> <DATA> <TXID>11</TXID> <BLOCK_ID>1073741825</BLOCK_ID> </DATA> </RECORD> <RECORD> <OPCODE>OP_SET_GENSTAMP_V2</OPCODE> <DATA> <TXID>12</TXID> <GENSTAMPV2>1001</GENSTAMPV2> </DATA> </RECORD> <RECORD> <OPCODE>OP_ADD_BLOCK</OPCODE> <DATA> <TXID>13</TXID> <PATH>/testdatas/hadoop-3.3.6.tar.gz._COPYING_</PATH> <BLOCK> <BLOCK_ID>1073741825</BLOCK_ID> <NUM_BYTES>0</NUM_BYTES> <GENSTAMP>1001</GENSTAMP> </BLOCK> <RPC_CLIENTID/> <RPC_CALLID>-2</RPC_CALLID> </DATA> </RECORD> <RECORD> <OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE> <DATA> <TXID>14</TXID> <BLOCK_ID>1073741826</BLOCK_ID> </DATA> </RECORD> <RECORD> <OPCODE>OP_SET_GENSTAMP_V2</OPCODE> <DATA> <TXID>15</TXID> <GENSTAMPV2>1002</GENSTAMPV2> </DATA> </RECORD> <RECORD>
-