基于深度学习的模型
知识体系
主要包括深度学习相关的特征抽取模型,包括卷积网络、循环网络、注意力机制、预训练模型等。
CNN
TextCNN 是 CNN 的 NLP 版本,来自 Kim 的 [1408.5882] Convolutional Neural Networks for Sentence Classification
结构如下:
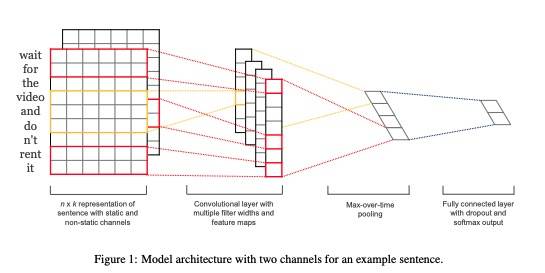
大致原理是使用多个不同大小的 filter(也叫 kernel) 对文本进行特征提取,如上图所示:
- 首先通过 Embedding 将输入的句子映射为一个
n_seq * embed_size大小的张量(实际中一般还会有 batch_size) - 使用
(filter_size, embed_size)大小的 filter 在输入句子序列上平滑移动,这里使用不同的 padding 策略,会得到不同 size 的输出 - 由于有
num_filters个输出通道,所以上面的输出会有num_filters个 - 使用
Max Pooling或Average Pooling,沿着序列方向得到结果,最终每个 filter 的输出 size 为num_filters - 将不同 filter 的输出拼接后展开,作为句子的表征
RNN
RNN 的历史比 CNN 要悠久的多,常见的类型包括:
- 一对一(单个 Cell):给定单个 Token 输出单个结果
- 一对多:给定单个字符,在时间步向前时同时输出结果序列
- 多对一:给定文本序列,在时间步向前执行完后输出单个结果
- 多对多1:给定文本序列,在时间步向前时同时输出结果序列
- 多对多2:给定文本序列,在时间步向前执行完后才开始输出结果序列
由于 RNN 在长文本上有梯度消失和梯度爆炸的问题,它的两个变种在实际中使用的更多。当然,它们本身也是有一些变种的,这里我们只介绍主要的模型。
-
LSTM:全称 Long Short-Term Memory,一篇 Sepp Hochreiter 等早在 1997 年的论文《LONG SHORT-TERM MEMORY》中被提出。主要通过对原始的 RNN 添加三个门(遗忘门、更新门、输出门)和一个记忆层使其在长文本上表现更佳。
[外链图片转存中…(img-jNNwraHK-1713793228695)]
-
GRU:全称 Gated Recurrent Units,由 Kyunghyun Cho 等人 2014 年在论文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》 中首次被提出。主要将 LSTM 的三个门调整为两个门(更新门和重置门),同时将记忆状态和输出状态合二为一,在效果没有明显下降的同时,极大地提升了计算效率。
[外链图片转存中…(img-vxmAzwM8-1713793228695)]
Questions
CNN相关
CNN 有什么好处?
- 稀疏(局部)连接:卷积核尺寸远小于输入特征尺寸,输出层的每个节点都只与部分输入层连接
- 参数共享:卷积核的滑动窗在不同位置的权值是一样的
- 等价表示(输入/输出数据的结构化):输入和输出在结构上保持对应关系(长文本处理容易)
CNN 有什么不足?
- 只有局部语义,无法从整体获取句子语义
- 没有位置信息,丢失了前后顺序信息
卷积层输出 size?
给定 n×n 输入,f×f 卷积核,padding p,stride s,输出的尺寸为:
⌊ n + 2 p − f s + 1 ⌋ × ⌊ n + 2 p − f s + 1 ⌋ \lfloor \frac{n+2p-f}{s} + 1 \rfloor \times \lfloor \frac{n+2p-f}{s} + 1 \rfloor ⌊sn+2p−f+1⌋×⌊sn+2p−f+1⌋
RNN
LSTM 网络结构?
LSTM 即长短时记忆网络,包括三个门:更新门(输入门)、遗忘门和输出门。公式如下:
c ^ < t > = tanh ( W c [ a < t − 1 > , x < t > ] + b c ) Γ u = σ ( W u [ a < t − 1 > , x < t > ] + b u ) Γ f = σ ( W f [ a < t − 1 > , x < t > ] + b f ) Γ o = σ ( W o [ a < t − 1 > , x < t > ] + b o ) c < t > = Γ u ∗ c ^ < t > + Γ f ∗ c < t − 1 > a < t > = Γ o ∗ c < t > \hat{c}^{<t>} = \tanh (W_c [a^{<t-1}>, x^{<t>}] + b_c) \\ \Gamma_u = \sigma(W_u [a^{<t-1}>, x^{<t>}] + b_u) \\ \Gamma_f = \sigma(W_f [a^{<t-1}>, x^{<t>}] + b_f) \\ \Gamma_o = \sigma(W_o [a^{<t-1}>, x^{<t>}] + b_o) \\ c^{<t>} = \Gamma_u * \hat{c}^{<t>} + \Gamma_f*c^{<t-1>} \\ a^{<t>} = \Gamma_o * c^{<t>} c^<t>=tanh(Wc[a<t−1>,x<t>]+bc)Γu=σ(Wu[a<t−1>,x<t>]+bu)Γf=σ(Wf[a<t−1>,x<t>]+bf)Γo=σ(Wo[a<t−1>,x<t>]+bo)c<t>=Γu∗c^<t>+Γf∗c<t−1>a<t>=Γo∗c<t>
如何解决 RNN 中的梯度消失或梯度爆炸问题?
- 梯度截断
- ReLU、LeakReLU、Elu 等激活函数
- Batch Normalization
- 残差连接
- LSTM、GRU 等架构
假设输入维度为 m,输出为 n,求 GRU 参数?
输入 W:3nm,隐层 W:3nn,隐层 b:3n,合计共:3*(nn+nm+n)。当然,也有的实现会把前一时刻的隐层和当前时刻的输入分开,使用两个 bias,此时需要再增加 3n 个参数。
LSTM 和 GRU 的区别?
- GRU 将 LSTM 的更新门、遗忘门和输出门替换为更新门和重置门
- GRU 将记忆状态和输出状态合并为一个状态
- GRU 参数更少,更容易收敛,但数据量大时,LSTM 效果更好
Attention
Attention 机制
Attention 核心是从输入中有选择地聚焦到特定重要信息上的一种机制。有三种不同用法:
- 在 encoder-decoder attention 层,query 来自上一个 decoder layer,memory keys 和 values 来自 encoder 的 output
- encoder 包含 self-attention,key value 和 query 来自相同的位置,即前一层的输出。encoder 的每个位置都可以注意到前一层的所有位置
- decoder 与 encoder 类似,通过将所有不合法连接 mask 以防止信息溢出
自注意力中为何要缩放?
维度较大时,向量内积容易使得 SoftMax 将概率全部分配给最大值对应的 Label,其他 Label 的概率几乎为 0,反向传播时这些梯度会变得很小甚至为 0,导致无法更新参数。因此,一般会对其进行缩放,缩放值一般使用维度 dk 开根号,是因为点积的方差是 dk,缩放后点积的方差为常数 1,这样就可以避免梯度消失问题。
另外,Hinton 等人的研究发现,在知识蒸馏过程中,学生网络以一种略微不同的方式从教师模型中抽取知识,它使用大模型在现有标记数据上生成软标签,而不是硬的二分类。直觉是软标签捕获了不同类之间的关系,这是大模型所没有的。这里的软标签就是缩放的 SoftMax。
至于为啥最后一层为啥一般不需要缩放,因为最后输出的一般是分类结果,参数更新不需要继续传播,自然也就不会有梯度消失的问题。
Transformer
Transformer 中为什么用 Add 而不是 Concat?
在 Embedding 中,Add 等价于 Concat,三个 Embedding 相加与分别 One-Hot Concat 效果相同。
ELMO
简单介绍下ELMO
使用双向语言模型建模,两层 LSTM 分别学习语法和语义特征。首次使用两阶段训练方法,训练后可以在下游任务微调。
Feature-Based 微调,预训练模型作为纯粹的表征抽取器,表征依赖微调任务网络结构适配(任务缩放因子 γ)。
ELMO的缺点
ELMO 的缺点主要包括:不完全的双向预训练(Bi 是分开的,仅在 Loss 合并);需要进行任务相关的网络设计(每种下游任务都要特定的设计);仅有词向量无句向量(没有句向量任务)。
GPT
简单介绍下GPT
使用 Transformer 的 Decoder 替换 LSTM 作为特征提取器。
Model-Based 微调,预训练模型作为任务网络的一部分参与任务学习,简化了下游任务架构设计。
GPT的缺点
GPT 的缺点包括:单项预训练模型;仅有词向量无句向量(仅学习语言模型)。
BERT
简单介绍下BERT
使用 Transformer Encoder 作为特征提取器,交互式双向语言建模(MLM),Token 级别+句子级别任务(MLM+NSP),两阶段预训练。
Feature-Based 和 Model-Based,实际一般使用 Model-Based。
BERT缺点
BERT 的缺点是:字粒度难以学到词、短语、实体的完整语义。
ERNIE
ERNIE对BERT进行了哪些优化?
对 BERT 的缺点进行了优化,Mask 从字粒度的 Token 修改为完整的词或实体。ERNIE2.0 引入更多的预训练任务以捕捉更丰富的语义知识。
![[ICCV2023]DIR-用于从单个RGB图像重建交互手部的解耦迭代细化框架](https://img-blog.csdnimg.cn/direct/f8ea54a8e7d144a9bd88c5f506d914c4.png)