文章目录
- LLM API 开发
- LLM入门基本概念
- LLM API使用
- 实名认证
- 创建应用
- 使用API
- Prompt Engineering
- 思考
- 总结
参考文章
什么是提示工程(Prompt Engineering)?
ChatGPT Prompt 最佳指南一
LLM API 开发
LLM入门基本概念
-
Prompt
Prompt 最初是 NLP(自然语言处理)研究者为下游任务设计出来的一种任务专属的输入模板,类似于一种任务(例如:分类,聚类等)会对应一种 Prompt。在 ChatGPT 推出并获得大量应用之后,Prompt 开始被推广为给大模型的所有输入。即,我们每一次访问大模型的输入为一个 Prompt,而大模型给我们的返回结果则被称为 Completion。 -
Temperature
LLM 生成是具有随机性的,在模型的顶层通过选取不同预测概率的预测结果来生成最后的结果。我们一般可以通过控制 temperature 参数来控制 LLM 生成结果的随机性与创造性。Temperature 一般取值在 0~1 之间,当取值较低接近 0 时,预测的随机性会较低,产生更保守、可预测的文本,不太可能生成意想不到或不寻常的词。当取值较高接近 1 时,预测的随机性会较高,所有词被选择的可能性更大,会产生更有创意、多样化的文本,更有可能生成不寻常或意想不到的词。
-
System Prompt
System Prompt 是随着 ChatGPT API 开放并逐步得到大量使用的一个新兴概念,事实上,它并不在大模型本身训练中得到体现,而是大模型服务方为提升用户体验所设置的一种策略。具体来说,在使用 ChatGPT API 时,你可以设置两种 Prompt:一种是 System Prompt,该种 Prompt 内容会在整个会话过程中持久地影响模型的回复,且相比于普通 Prompt 具有更高的重要性;另一种是 User Prompt,这更偏向于我们平时提到的 Prompt,即需要模型做出回复的输入。
我们一般设置 System Prompt 来对模型进行一些初始化设定,例如,我们可以在 System Prompt 中给模型设定我们希望它具备的人设如一个个人知识库助手等。System Prompt 一般在一个会话中仅有一个。在通过 System Prompt 设定好模型的人设或是初始设置后,我们可以通过 User Prompt 给出模型需要遵循的指令。例如,当我们需要一个幽默风趣的个人知识库助手,并向这个助手提问我今天有什么事时,可以构造如下的 Prompt:
{
“system prompt”: “你是一个幽默风趣的个人知识库助手,可以根据给定的知识库内容回答用户的提问,注意,你的回答风格应是幽默风趣的”,
“user prompt”: “我今天有什么事务?”
}
通过如上 Prompt 的构造,我们可以让模型以幽默风趣的风格回答用户提出的问题。
LLM API使用
API 申请指引
DataWhale的API申请指南中很清楚描述了OPEN AI、文心一言、讯飞星火、智谱 GLM的API权限申请和API使用示例,大家可以移步观看。
下面小节记录了文心一言的使用过程~
实名认证
首先点击千帆大模型平台进行登录,初次登录的用户需要实名认证,这里推荐扫码登录。
创建应用
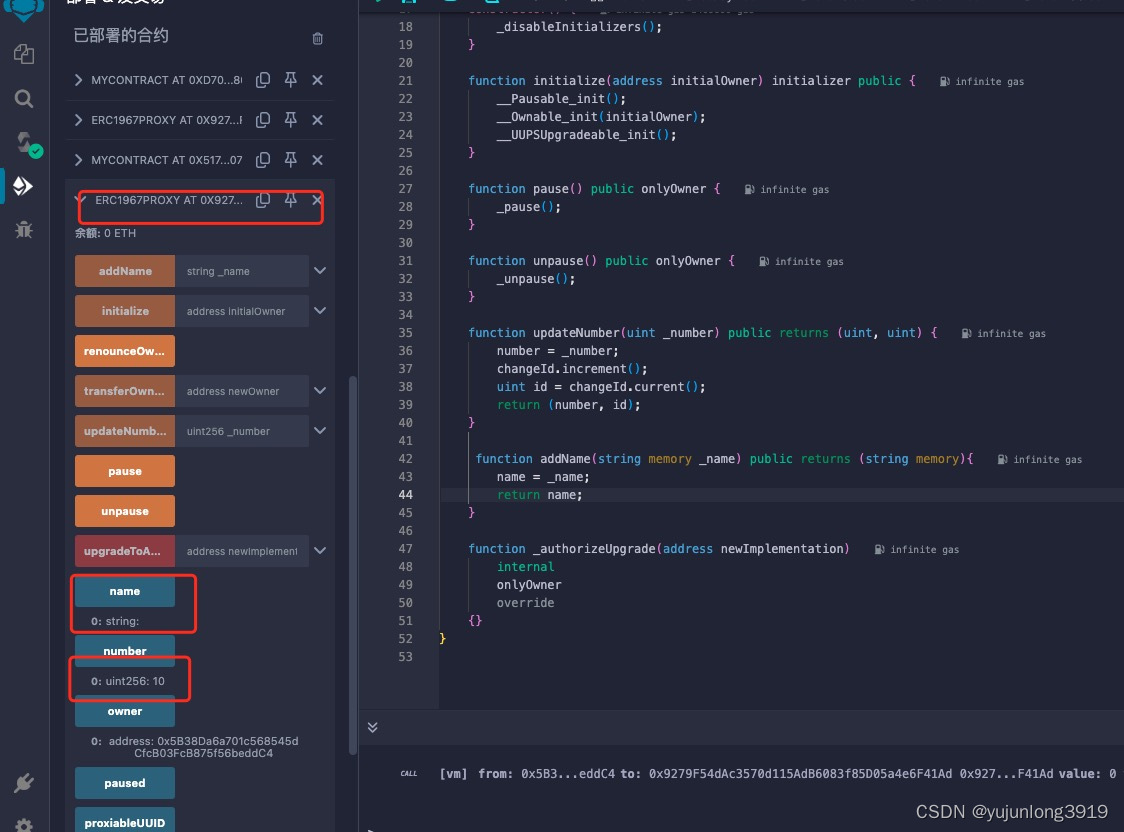
实名认证后,可以看到一下界面,点击应用接入,选择初始化的模型服务,点击确认后会生成应用相关的信息,

从下图中可以看到创建的应用的 API Key、Secret Key。
需要注意的是,千帆目前只有 Prompt模板、Yi-34B-Chat 和 Fuyu-8B公有云在线调用体验服务这三个服务是免费调用的,如果你想体验其他的模型服务,需要在计费管理处开通相应模型的付费服务才能体验。

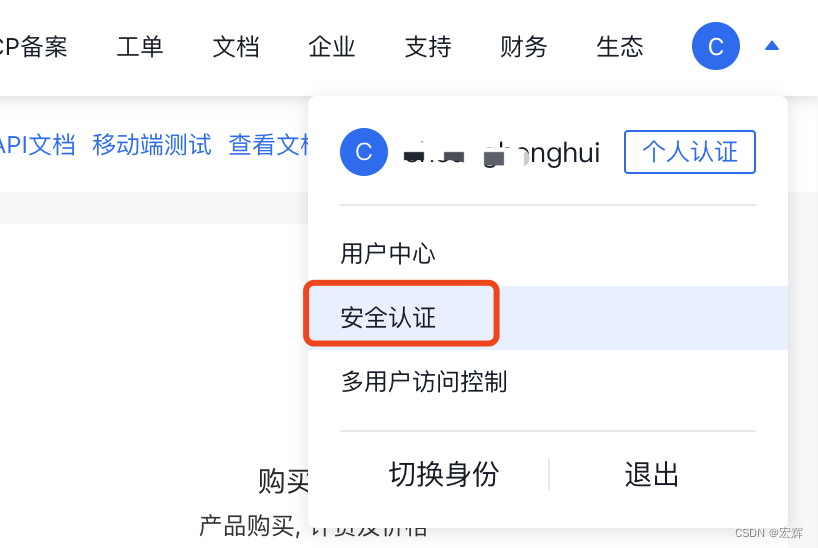
我们将这里获取到的 API Key、Secret Key 填写至 .env 文件的 QIANFAN_AK 和 QIANFAN_SK 参数。如果你使用的是安全认证的参数校验,需要在百度智能云控制台-用户账户-安全认证页,查看 Access Key、Secret Key,并将获取到的参数相应的填写到 .env 文件的 QIANFAN_ACCESS_KEY、QIANFAN_SECRET_KEY。
( .env 文件见代码示例
然后执行以下代码,将密钥加载到环境变量中。
from dotenv import load_dotenv, find_dotenv
# 读取本地/项目的环境变量。
# find_dotenv() 寻找并定位 .env 文件的路径
# load_dotenv() 读取该 .env 文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())
使用API
import qianfan
def gen_wenxin_messages(prompt):
'''
构造文心模型请求参数 messages
请求参数:
prompt: 对应的用户提示词
'''
messages = [{"role": "user", "content": prompt}]
return messages
def get_completion(prompt, model="ERNIE-Bot", temperature=0.01):
'''
获取文心模型调用结果
请求参数:
prompt: 对应的提示词
model: 调用的模型,默认为 ERNIE-Bot,也可以按需选择 Yi-34B-Chat 等其他模型
temperature: 模型输出的温度系数,控制输出的随机程度,取值范围是 0~1.0,且不能设置为 0。温度系数越低,输出内容越一致。
'''
chat_comp = qianfan.ChatCompletion()
message = gen_wenxin_messages(prompt)
resp = chat_comp.do(messages=message,
model=model,
temperature = temperature,
system="你是一名个人助理-小鲸鱼")
return resp["result"]
调用get_completion获取大模型的回答
get_completion("你好,介绍一下你自己", model="Yi-34B-Chat")
至此,已将上手体验了LLM的API。
Prompt Engineering
提示工程(Prompt Engineering)是指通过提示(Prompt)的开发和优化,与LLM进行交互,以引导其产生所期望的结果,而无需对模型进行更新。
提示工程可以帮助研究人员提升大型语言模型在处理复杂任务时的能力,比如问答和算术推理,或者提升生成式AI模型在特定任务场景下的性能和效果。通过合理设计和使用提示工程,可以赋能大模型,获得更加符合期待的结果,使其更好地适应各种任务和应用场景。
提示工程的基础要素
由于提示工程是通过对提示进行修改来达到目标,我们首要需要了解的就是提示。提示的写法多种多样,其中有四个重要要素:
提示工程中的提示可以包含以下要素:
- 指令:明确说明希望语言模型执行的特定任务或指令。
- 上下文:提供外部信息或额外的上下文,以引导语言模型更好地理解和响应。
- 输入数据:包括用户输入的内容或问题,作为模型生成输出的依据。
- 输出指示:指定所期望的输出类型或格式。
需要注意的是,提示的具体格式取决于所需任务类型,不是所有上述要素都是必需的。根据任务的不同,您可以选择包含适当的要素来指导语言模型的行为和输出结果。
for example:
- 写清晰的说明:GPT 没有读心术,因此如果你想要一个简短的输出,可以直接告诉它在100字左右。如果你想要一个小朋友能听懂的解释,可以直接告诉它讲给10岁的小朋友听,尽量浅显易懂些。
- 提供参考文本:GPT 比最能侃的人还能侃,回答可能会胡编乱造,可能会南辕北辙。就像一些练习册可以帮助学生在考试中做得更好一样,你可以向GPT提供参考文本,帮助它回答的更精准可靠。
将复杂任务分解为更简单的子任务:太复杂的任务,目前的 GPT4 处理起来还有点费劲儿,出错率比较高。因此需要你把任务拆分到 GPT4 可以处理的粒度,自己再组装每一步的结果。 - 给GPT时间“思考”:如果被问到 17 乘以 28,人们不会立即知道答案,但可以花时间算出来。同样你需要 GPT 用推理链来一步步思考,而不是立马给出一个错误的答案。
- 使用外部工具:人之所以成为万物主宰,很大原因就是会用工具。同样,你可以通过将其他工具的输出提供给 GPT4,来补偿 GPT4 的弱点。例如,代码执行引擎可以帮助 GPT4 做数学和运行代码。
- 系统地测试变化:如果你能够系统地评估 GPT4 的能力,那么就能逐渐优化提高它的能力了。某些情况下,对 prompt 的修改可能会在某些个别的例子上提高表现,但在更具代表性的例子上导致整体表现下降。因此,为了确保 prompt 的改变效果是正面的,需要定义一个全面的测试套件。OpenAI开源了 evals 评测工具,
思考
1、System Prompt的妙用
每次在新建chatgpt对话时,都可以先定义System Prompt,及向gpt定义用户想要的领域、回答风格、回答模版等,这样够帮助AI更准确地理解我们的需求,并给出满足我们需求的答案。
例如需要快速解决es分组查询的问题,可以先定义好chatgpt的System Prompt:
你是有经验的es开发工程师,下面将会对你请教有关es的dsl问题。请充分思考,结合es官方文档XXX后给出回答,出现不会的问题可以回答不清楚,谢谢。
在上面的System Prompt中,用户主要对LLM说明了三个特征
1、es开发工程师
2、解决有关es的dsl
3、结合es官方文档
4、出现未知问题回答不清楚
这样LLM会在Completion中给出用户制定想要的答案(起码出现幻觉的机率变低)
总结
主要了解了LLM中的基础知识,包括输入提示词prompt、temperature(模型输出的温度系数,控制输出的随机程度,取值范围是 0~1.0,且不能设置为 0。温度系数越低,输出内容越一致。)以及Prompt Engineering中常用的调优技术,如:写清晰的说明、给LLM充足的思考时间…,只要prompt写得好,LLM回答才会更快返回符合用户的答案。
本次以百度的千帆大模型为载体,体验了LLM API的使用,从代码层面了解到LLM回答问题的过程,认识到LLM的基本输入参数:prompt、model、temperature。
偷瞄了第三节内容,知识库的搭建,选用的框架是我没接触过的Chroma,嘿嘿~期待一下吧