作者:来自 Elastic Panagiotis Bailis
在这篇博客文章中,我们将深入探讨我们为了使 KNN 搜索的入门体验变得更加简单而做出的努力!
向量搜索
向量搜索通过在 Elasticsearch 中引入一种新的专有的 KNN 搜索类型,已经可以使用一段时间了,而我们还在 8.12.0 版本中引入了 KNN 作为一种查询方式(关于这个话题,我们最近发布了一篇精彩的博客文章!)。
尽管每种方法的执行流程和应用有所不同,但进行基本 KNN 检索的语法大体相似。因此,典型的 KNN 搜索请求看起来是这样的:
GET products/_search
{
"knn": {
"field": "my_vector",
"query_vector": [1, 2, 3],
"k": 5,
"num_candidates": 10
}
}前几个参数相当直观:我们指定数据存储的位置(field)和我们想要比较的对象(query_vector)。
另一方面,k 和 num_candidates 参数稍微有些晦涩,需要一定的理解才能进行精细调整。这些参数特定于我们使用的算法和数据结构,即 HNSW,并主要用于控制我们希望进行的图探索量。
Elasticsearch 文档是关于搜索的所有事务的绝佳资源,因此我们可以查看 KNN 部分:
k:要返回的最近邻居的数量作为顶部结果。该值必须小于 num_candidates。
num_candidates:每个分片考虑的最近邻居候选数。需要大于 k,或者如果 k 被省略,则大于 size,并且不能超过 10,000。Elasticsearch 从每个分片收集 num_candidates 结果,然后将它们合并以找到前 k 个结果。增加 num_candidates 往往会提高最终 k 结果的准确性。
然而,当你第一次遇到这样的设置时,这些值应该是多少并不明显,正确配置它们可能会成为一个挑战。这些值越大,我们将探索的向量就越多,但这将带来性能成本。我们再次遇到了准确性与性能之间永恒的权衡。
为了使 KNN 搜索更简单、更直观,我们决定使这些参数成为可选的,这样你只需要提供你想搜索的位置和内容,如果真的需要,还可以调整这些参数。虽然看似是一个较小的改变,但它使事情变得更加清晰!因此,上面的查询现在可以简单地重写为:
GET products/_search
{
"knn": {
"field": "my_vector",
"query_vector": [1, 2, 3]
}
}使 k 和 num_candidates 成为可选项
我们想要将 k 和 num_candidates 设为可选项。太好了!但是默认值应该设置为多少呢?

此时有两个选项。选择看起来不错的选项,发布并希望一切顺利,或者做出艰苦的努力,进行广泛的评估以让数据驱动我们的决策。在 Elastic,我们喜欢这样的挑战,并希望确保任何决定都是有充分理由的!
刚刚我们提到,KNN 搜索中的 k 是每个分片返回的结果数,因此一个明显的默认值是使用 size。因此,每个分片将返回 size 个结果,然后我们将它们合并并排序以找到全局前 size 个结果。这也非常适用于 KNN 查询,其中根本没有 k 参数,而是基于请求的 size 进行操作(请记住,KNN 查询的行为就像任何其他查询,如 term、prefix 等)。因此,size 看起来是一个合理的默认值,可以涵盖大多数用例(或者至少在入门体验期间足够好!)。
另一方面,num_candidates 则大不相同。这个参数特定于 HNSW 算法,控制着我们将考虑的最近邻队列的大小(对于感兴趣的人来说:这相当于原始论文中的 ef 参数)。
在这里,我们可以采取多种方法:
- 我们可以考虑每个图的大小,并制定一个函数,用于计算适当的 num_candidates,以匹配 N 个索引向量。
- 我们可以查看底层数据分布,并尝试估算所需的探索(也许还可以考虑 HNSW 的入口点)。
- 我们可以假设 num_candidates 与索引数据无直接关系,而与搜索请求相关,并确保我们将进行必要的探索,以提供足够好的结果。
作为一个起点,并且为了保持简单,我们研究了将 num_candidates 值设置为与 k(或 size)相关的值。因此,你实际想要检索的结果越多,我们就会对每个图执行更高的探索,以确保我们摆脱局部最小值。我们主要关注的候选者如下:
- num_candidates = k
- num_candidates = 1.5 * k
- num_candidates = 2 * k
- num_candidates = 3 * k
- num_candidates = 4 * k
- num_candidates = Math.max(100, k)
值得注意的是,最初考虑了更多的替代方案,但更高的值提供的好处很小,因此在博客的剩余部分,我们将主要关注上述内容。
现在我们有了一组 num_candidates 候选者(无意中的双关!),接下来我们将关注 k 参数。我们选择同时考虑标准搜索以及非常大的 k 值(以查看我们所做探索的实际影响)。因此,我们决定更加关注的值是:
- k = 10(考虑到指定了 no size 的请求)
- k = 20
- k = 50
- k = 100
- k = 500
- k = 1000
数据
鉴于没有放之四海而皆准的解决方案,我们希望测试具有不同属性的各种数据集。因此,这些数据集具有不同的总向量数、维度,并且来自不同的模型,因此具有不同的数据分布。同时我们也可以使用 rally,这是一个很棒的基准测试工具(https://github.com/elastic/rally),它已经支持运行一系列查询并为多个向量数据集提取指标。
在 rally 上运行基准测试就像运行以下命令一样简单:
pip3 install esrally && esrally race --track=dense-vector为此,我们稍微修改了轨迹(即 rally 的测试场景),以包括额外的度量配置,添加了一些新的配置,最终得到了以下一组轨迹:
dense-vector(2M docs, 96dims): https://github.com/elastic/rally-tracks/tree/master/dense_vectorso-vector(2M docs, 768 dims): https://github.com/elastic/rally-tracks/tree/master/so_vectorcohere-vector(3M docs, 768 dims): rally-tracks/cohere_vector at master · elastic/rally-tracks · GitHubopenai-vector(2.5M docs, 1536dims): https://github.com/elastic/rally-tracks/tree/master/openai_vectorGlove 200d(1.2M, 200dims) new track created based on GitHub - erikbern/ann-benchmarks: Benchmarks of approximate nearest neighbor libraries in Python repo
值得注意的是,对于前几个数据集,我们还希望考虑到是否只有一个段或多个段,因此我们包含了每种情况的两个变体:
- 一个变体,我们执行 force_merge 并获得单个段,
- 一个变体,我们依赖底层的 MergeScheduler 来执行其工作,以得到合适数量的段。
指标
针对上述每个轨迹,我们计算了标准的召回率和精确度指标、延迟,以及我们在图上实际进行的探索,通过报告我们访问的节点。前面几个指标是针对真实最近邻进行评估的,因为在我们的情况下,这是黄金标准数据集(请记住,我们评估的是近似搜索的好坏,而不是向量本身的质量)。nodes_visited 属性最近已添加到 knn 的配置文件输出中(https://github.com/elastic/elasticsearch/pull/102032),因此,通过对轨迹定义进行一些微小的更改以提取所有所需的指标,我们应该可以进行评估了!
开始动手操作
现在我们知道我们想要测试什么,要使用哪些数据集,以及如何评估结果,是时候真正运行基准测试了!
为了获得标准化的环境,对于每个测试,我们使用了一个干净的 n2-standard-8(8 vCPU,4 核心,32 GB 内存)云节点。Elasticsearch 配置,以及必要的映射和其他所有内容,都是通过 rally 进行配置和部署的,因此对于所有类似的测试都是一致的。
上述每个数据集都执行了多次,收集了所有候选集定义的可用指标,确保没有结果是偶然的。
结果
每个指定数据集和参数组合的召回率 - 延迟图可以在下面找到(越高且越靠左越好):

将范围缩小到 dense_vector 和 openai_vector 轨迹,我们有关于 latency@50th 和召回率的绝对值数据如下:




类似地,每个场景的 HNSW 图节点访问的第 99 百分位数如下(数值越小越好):




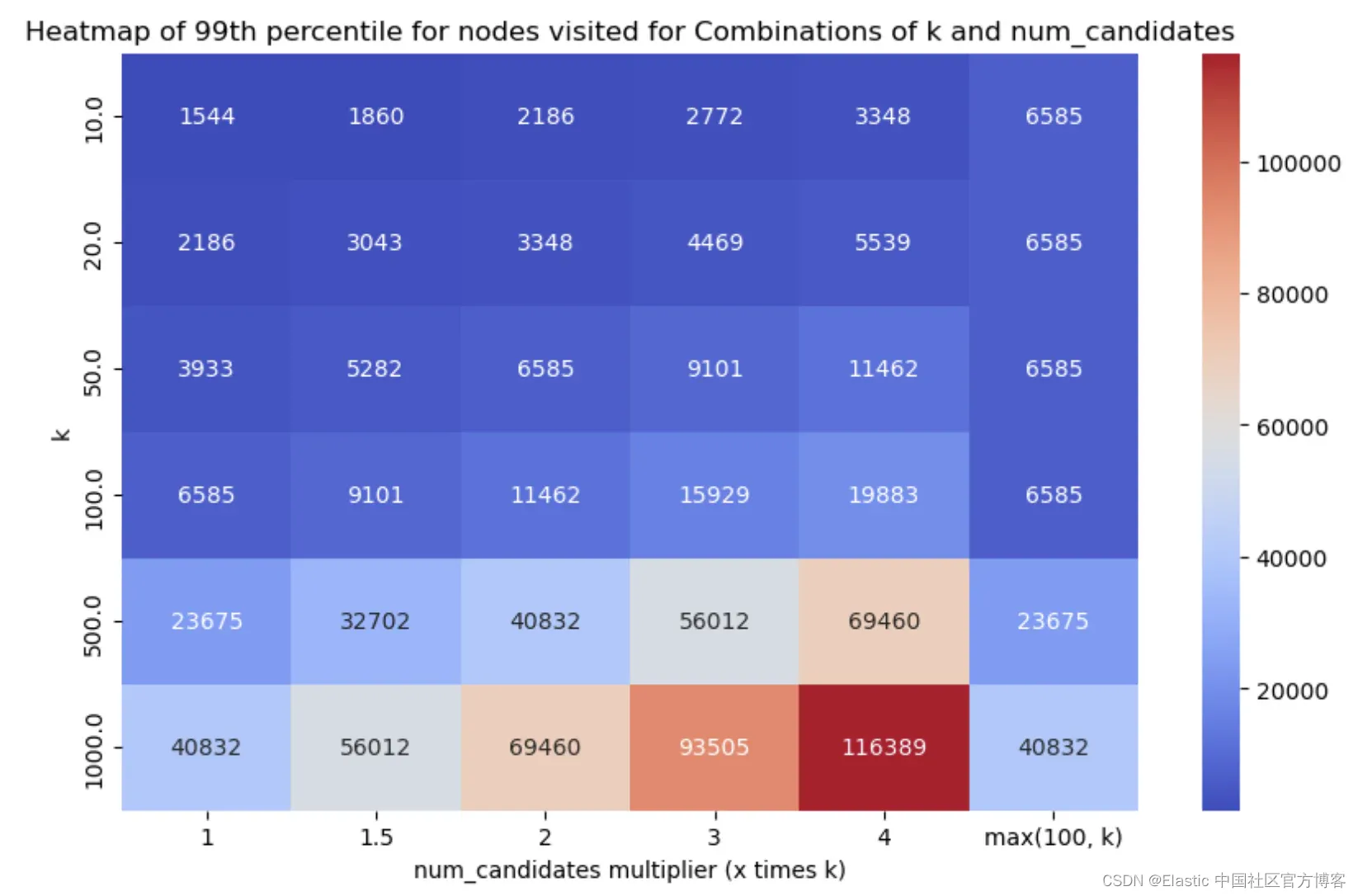
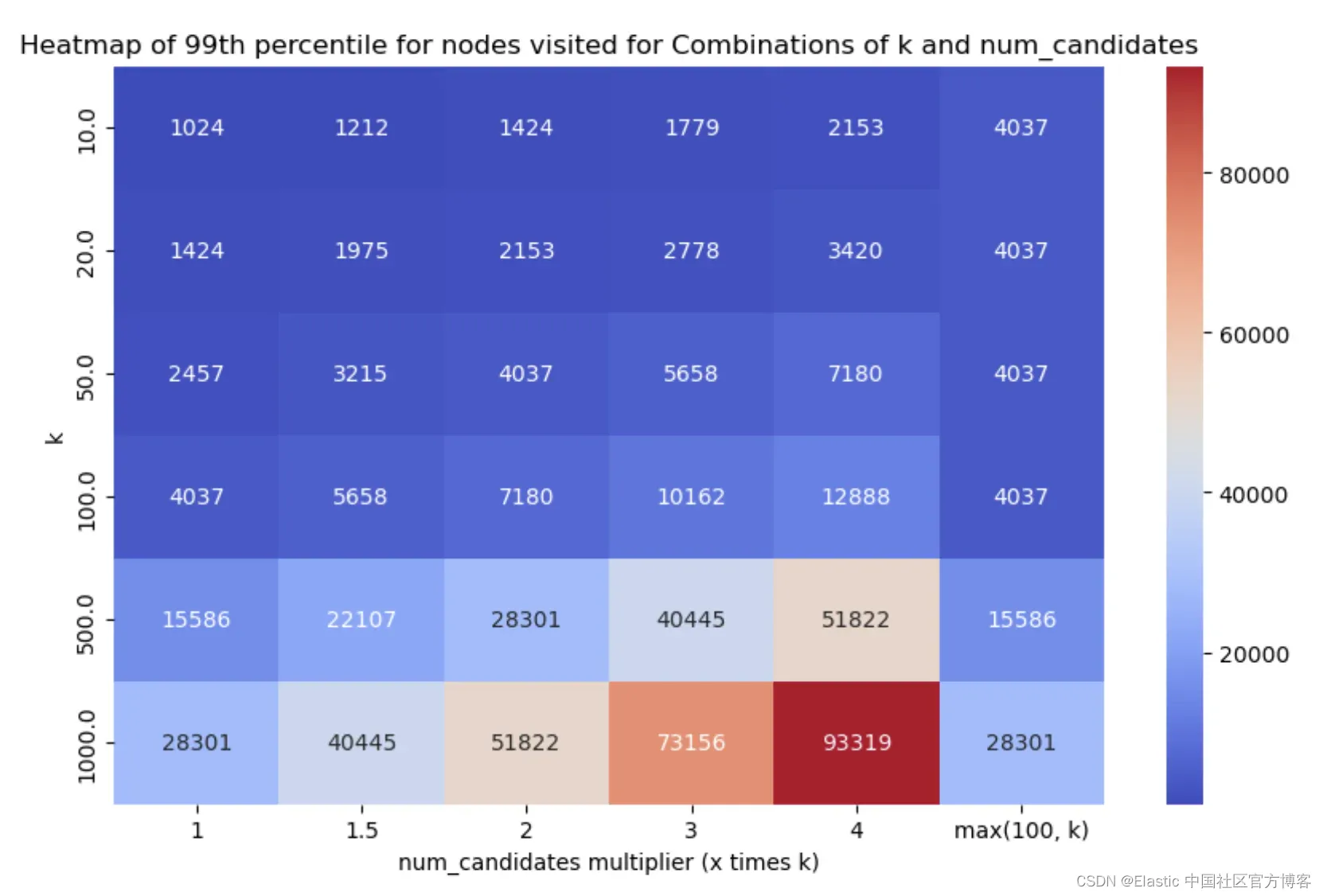
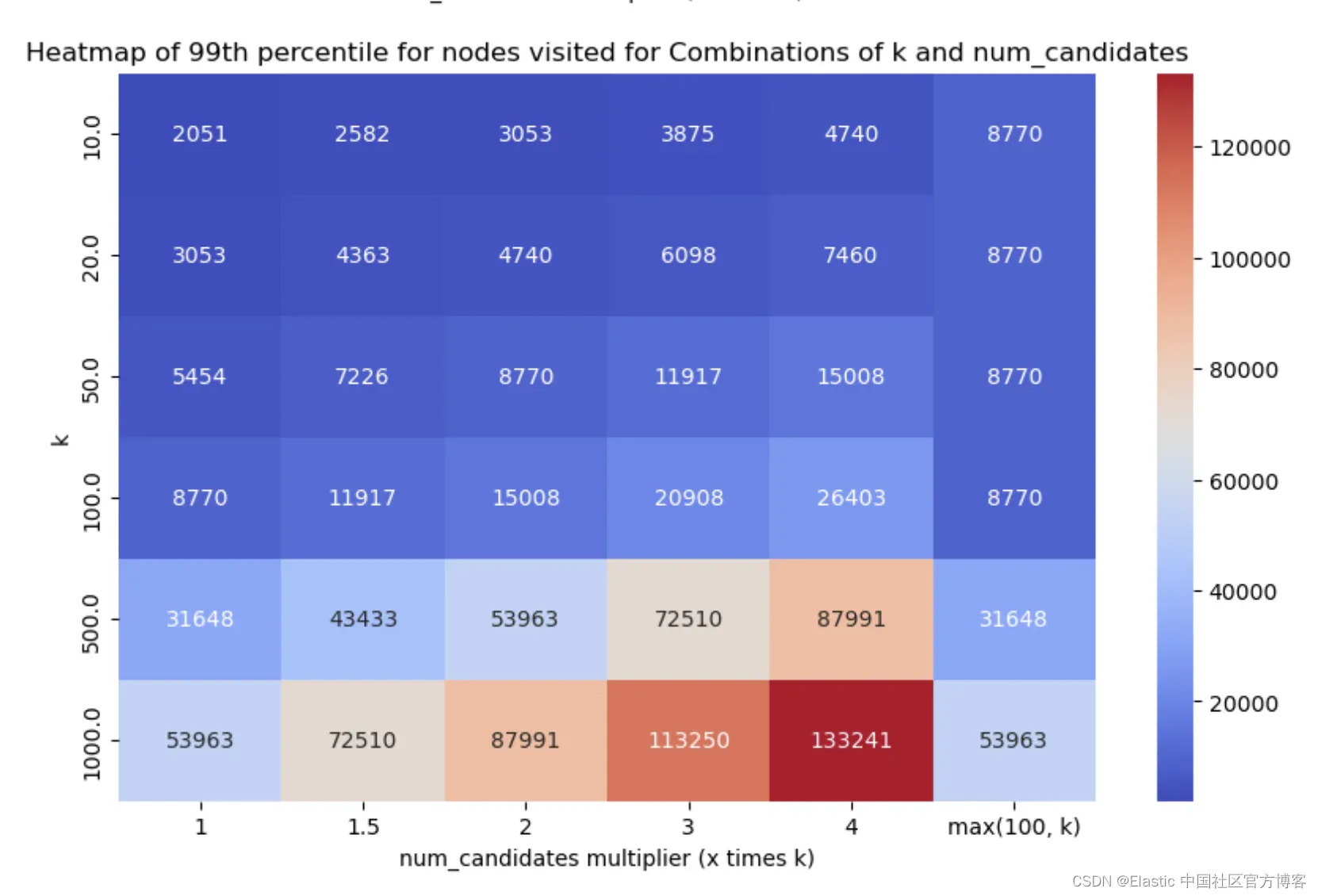
少即是多*
*嗯,并非在所有情况下都是如此,但嘿 :) 从结果中可以看出两点:
- 单个段与多个段明显影响召回率和延迟指标呈反比关系。段数较少会降低延迟(因为我们要遍历的图较少,即运行的搜索较少),这很好,但它也以相反的方式影响了召回率,因为由于 num_candidates 列表较少,可能会漏掉一些好的候选项。
- 即使探索量很少,我们在几乎所有情况下都可以达到足够好的召回率,这很棒!
我们一直致力于改进多段搜索(这篇文章中有一个很好的例子),因此我们预计这种权衡在未来将不再是一个问题(这里报告的数字不包括这些改进)。
综合考虑所有因素,我们讨论的两个主要选项如下:
- num_candidates = 1.5 * k - 这几乎在所有情况下都能达到足够好的召回率,并且延迟得分非常好。
- num_candidates = Math.max(100, k) - 这在特别是较低的 k 值时达到了稍微更好的召回率,但权衡之处在于增加了图探索和延迟。
经过认真考虑和(漫长的!)讨论,我们决定采用前一种默认设置,即设置 num_candidates = 1.5 * k。我们需要进行的探索要少得多,而且召回率始终在 75% 以上,大多数情况下在 90% 以上,这应该能够提供足够好的入门体验。
结论
我们在 Elastic 处理 knn 搜索的方式在不断进化,我们持续引入新功能和改进,因此这些参数和整体评估很可能很快就会过时!我们总是在密切关注,一旦发生变化,我们将确保跟进并相应调整我们的配置!
需要记住的一件重要事情是,这些值仅作为简化入门体验和非常通用用例的合理默认值。用户可以轻松地在自己的数据集上进行实验,并根据自己的需求进行相应调整(例如,在某些情况下,召回率可能比延迟更重要)。
快乐调优 😃
准备在你的应用中构建 RAG 吗?想尝试使用向量数据库的不同 LLM 吗? 查看 Github 上的 LangChain、Cohere 等示例笔记本,并加入即将开始的 Elasticsearch 工程师培训!
原文:Simplifying knn search — Elastic Search Labs






![收集统计信息报错ora-00600[16515]问题处理](https://img-blog.csdnimg.cn/img_convert/0a79ddbc7a18e1e0ca3b8ebdeb7982ef.png)


