文章目录
- 问题分析
- 所需环境
- 代码实现
-
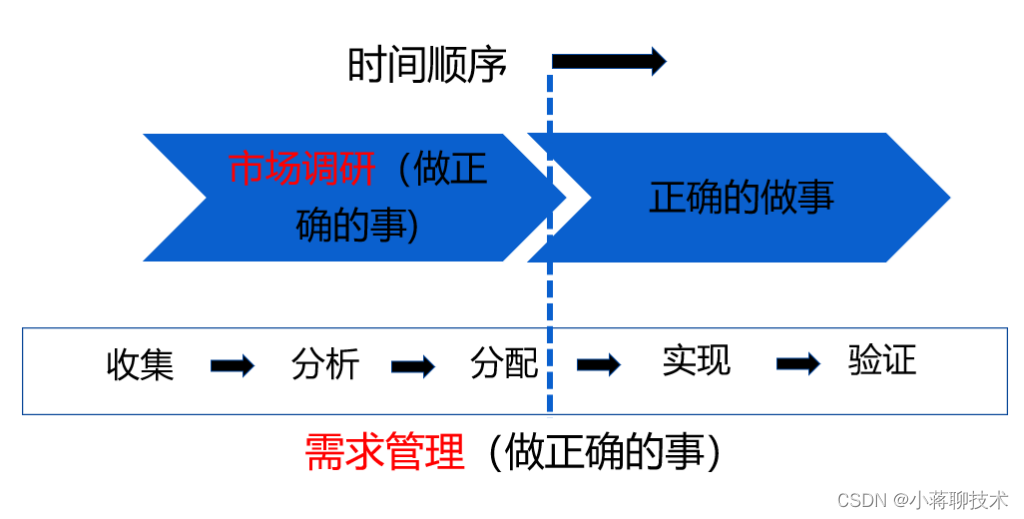
- 1. 相关性分析及可视化
- 2. 房价分析及可视化
- 3. 构建房价预测模型
问题分析
波士顿房价数据集包含美国人口普查局收集的美国马萨诸塞州波士顿住房价格的有关信息, 数据集很小,只有506个案例。
数据集都有以下14个属性,具体含义如下
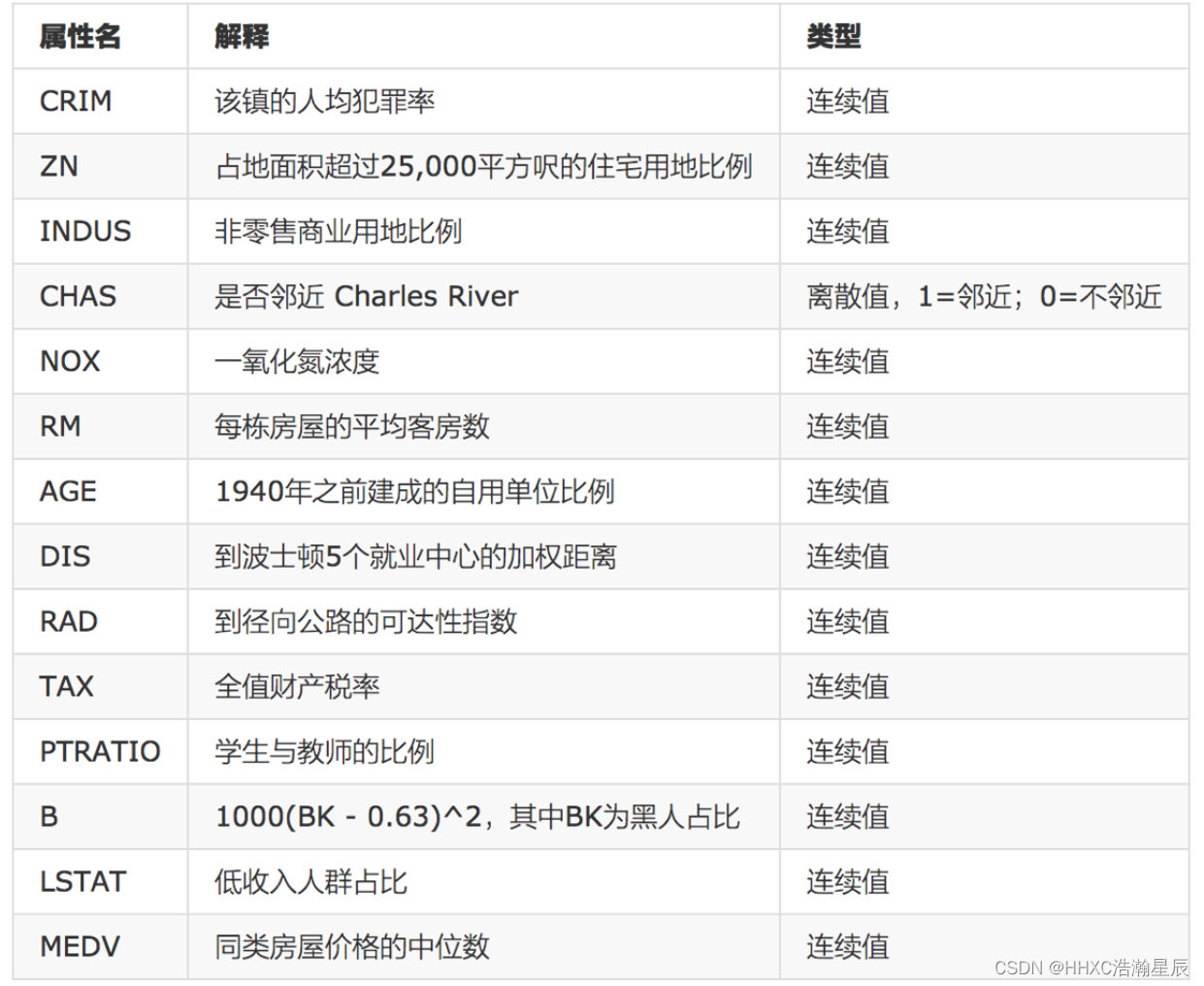
现在需要分析各变量与房价之间的相关性,找到影响房价的主要变量,并剔除异常房价数据,最后基于以上数据建立房价预测模型。
所需环境
- numpy
- pandas
- matplotlib
- sklearn
代码实现
1. 相关性分析及可视化
- 以
CRIM变量为例
from sklearn.datasets import load_boston # 导入数据集
import matplotlib.pyplot as plt
boston = load_boston()
x = boston['data'] # 影响房价的特征信息
y = boston['target'] # 房价
name = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
plt.figure(figsize=(10, 7))
plt.grid()
# 注 x 数据中的第一列数据就是CRIM
plt.scatter(x[:, 0], y, s=8) # 横纵坐标和点的大小 # 这里的x[:,1] 就是ZN数据
plt.title(name[0])
plt.show()
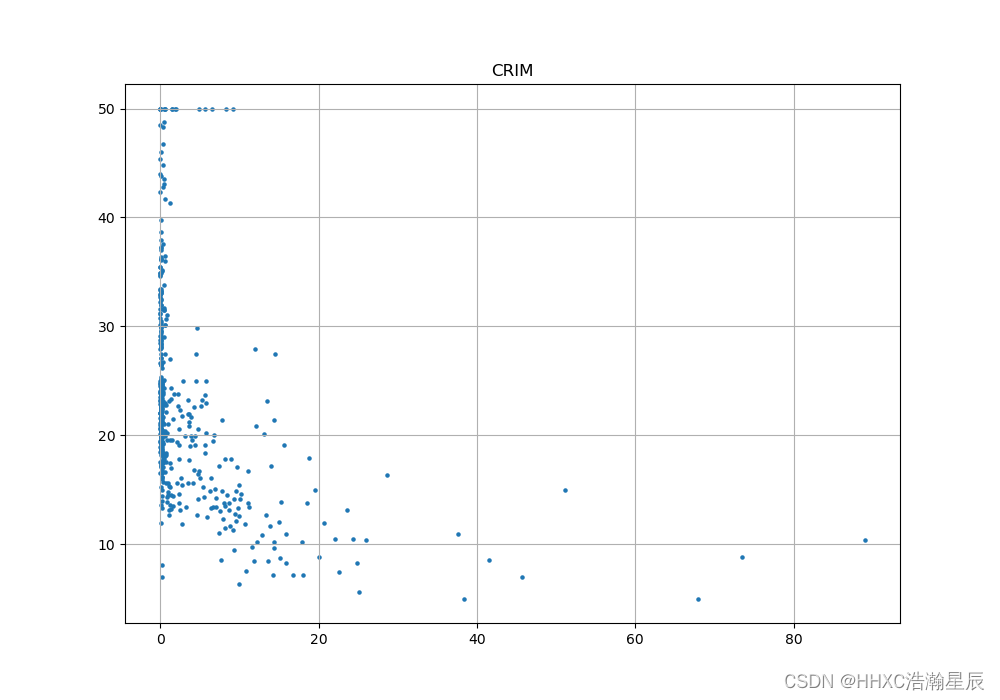
分析:
可以看到,犯罪率越低的地方,房价呈现越高,但是相关性不高
- 再一次以
RM为例
from sklearn.datasets import load_boston # 导入数据集
import matplotlib.pyplot as plt
boston = load_boston()
x = boston['data'] # 影响房价的特征信息
y = boston['target'] # 房价
name = <