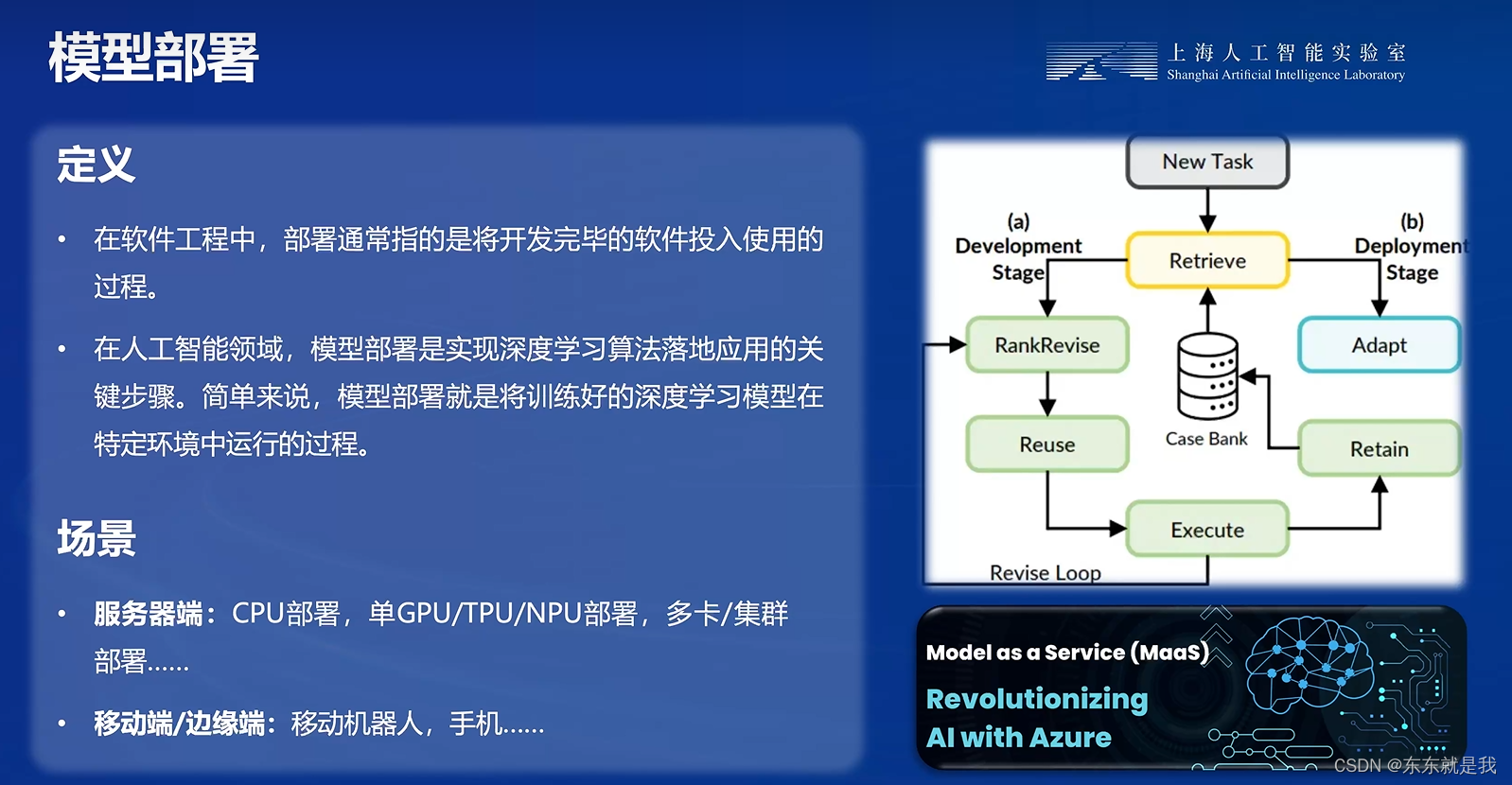
大模型部署简介
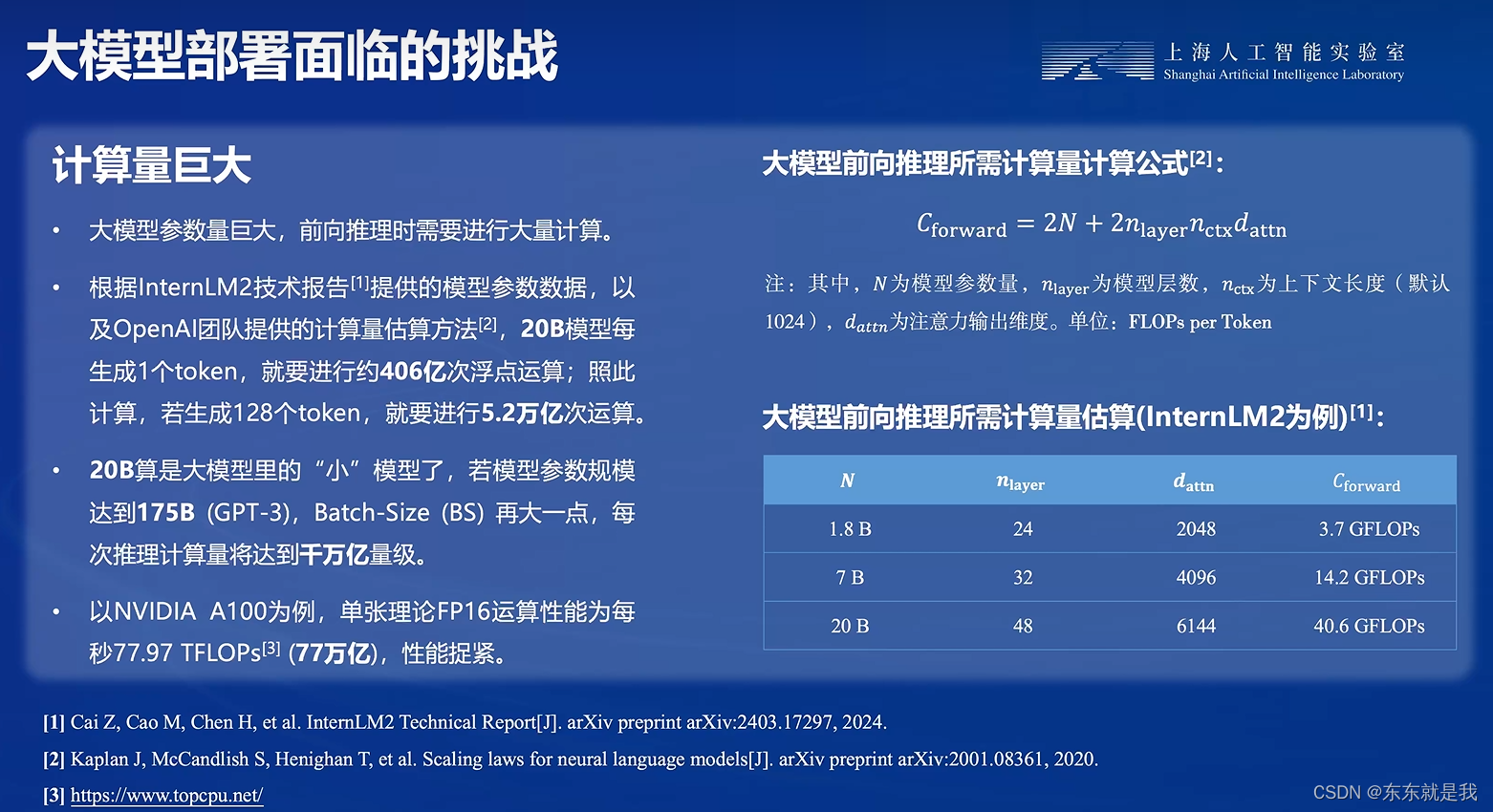
难点
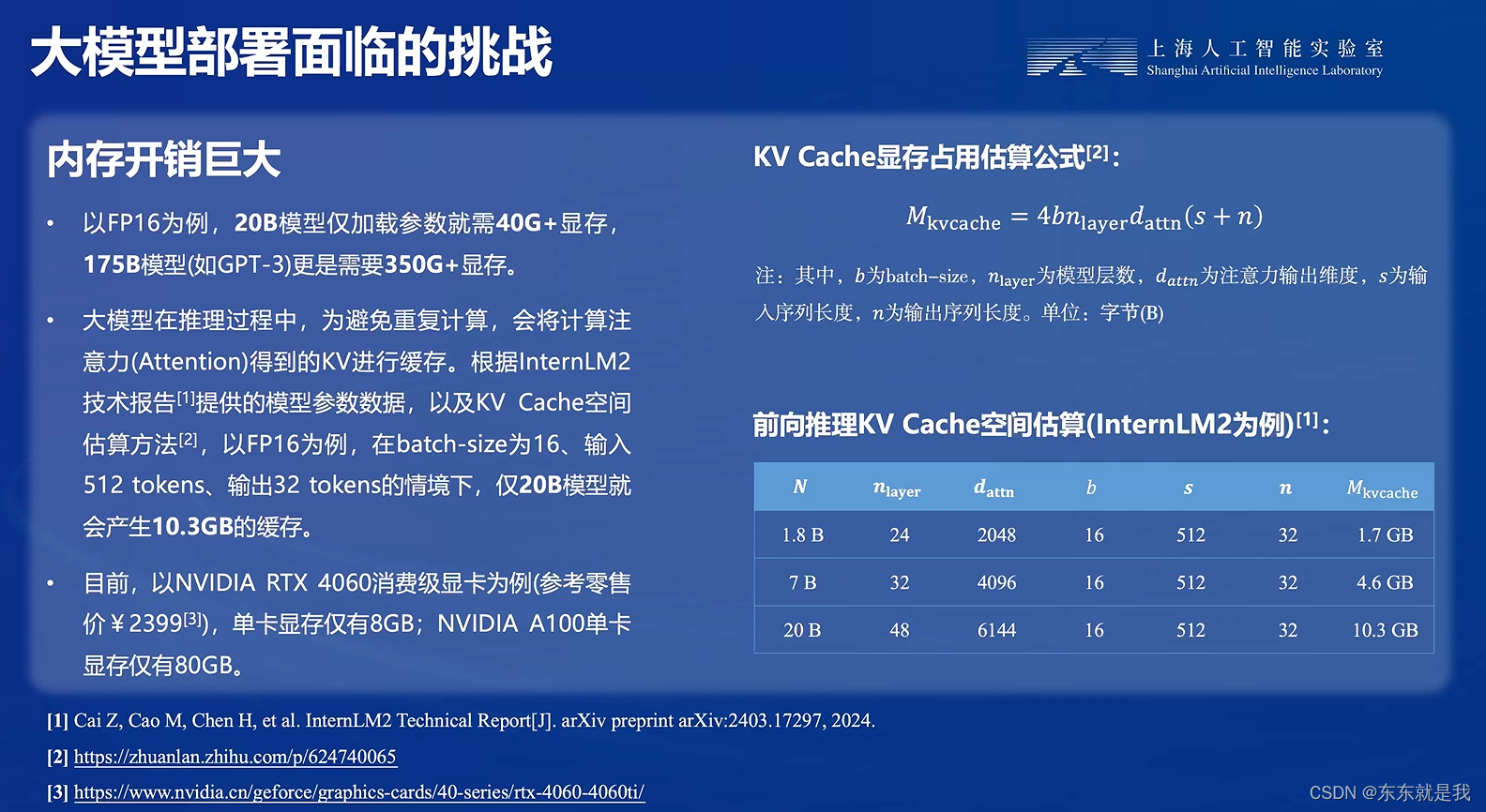
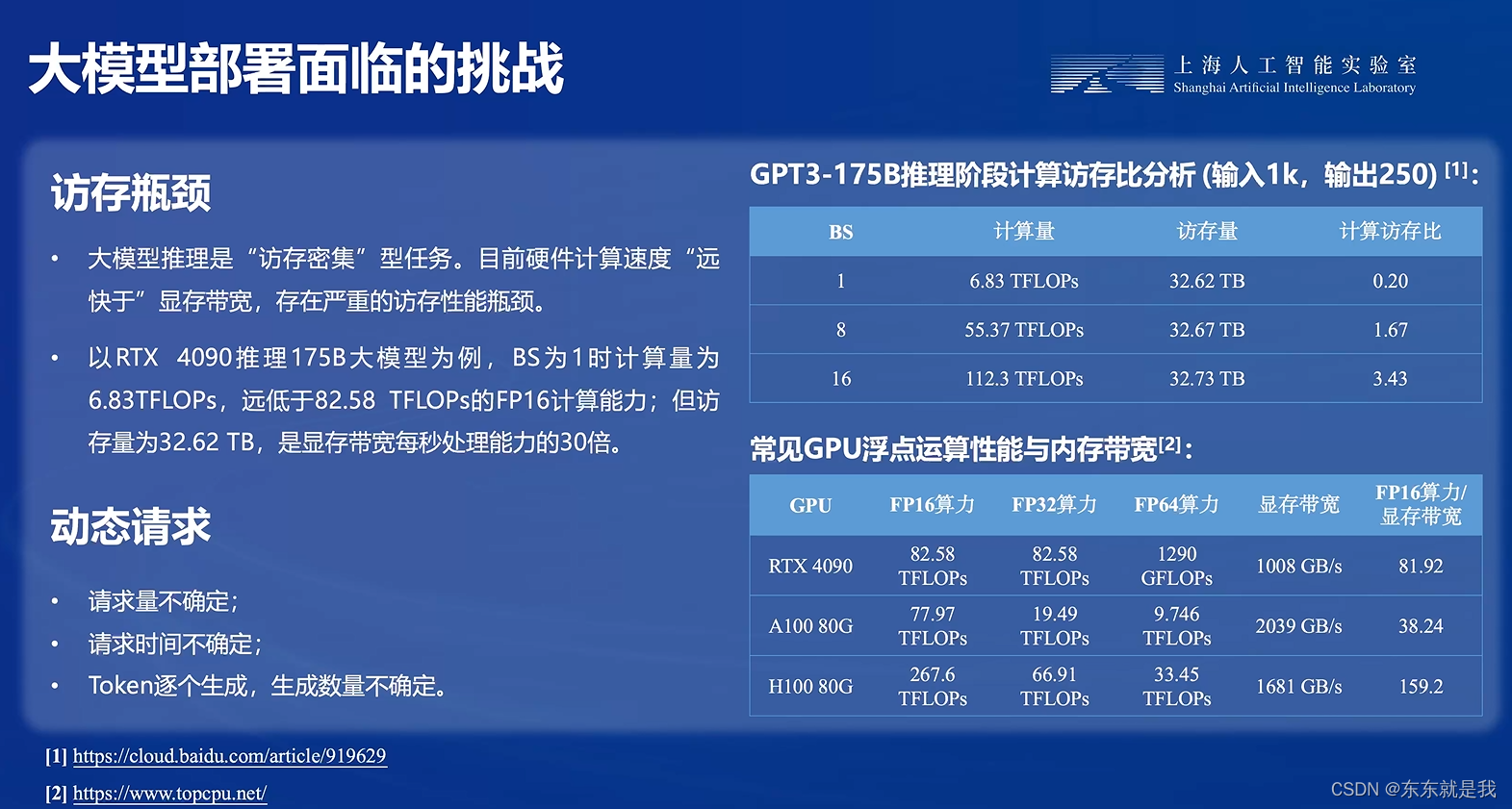
大模型部署的方法

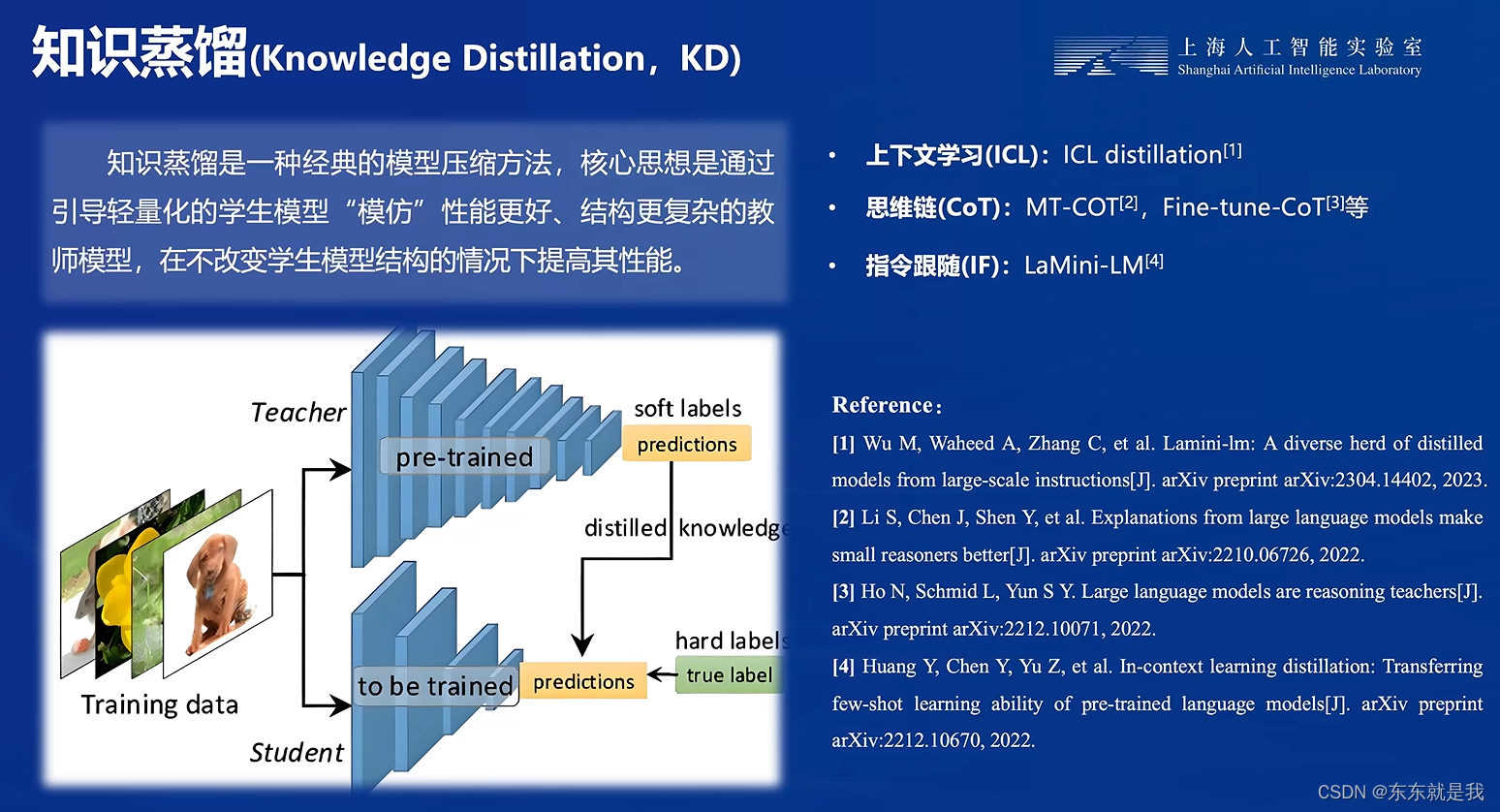

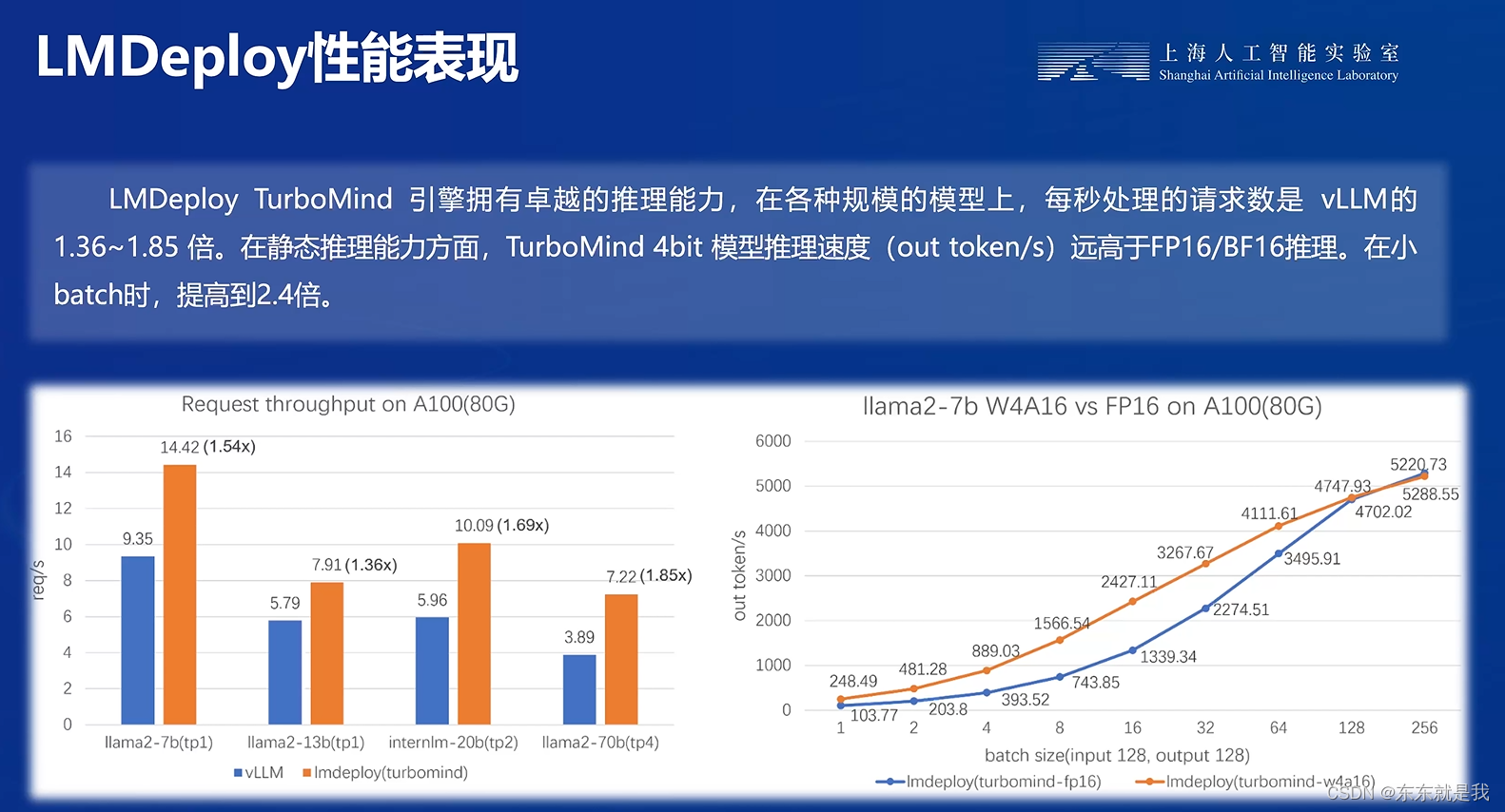
LMDeploy



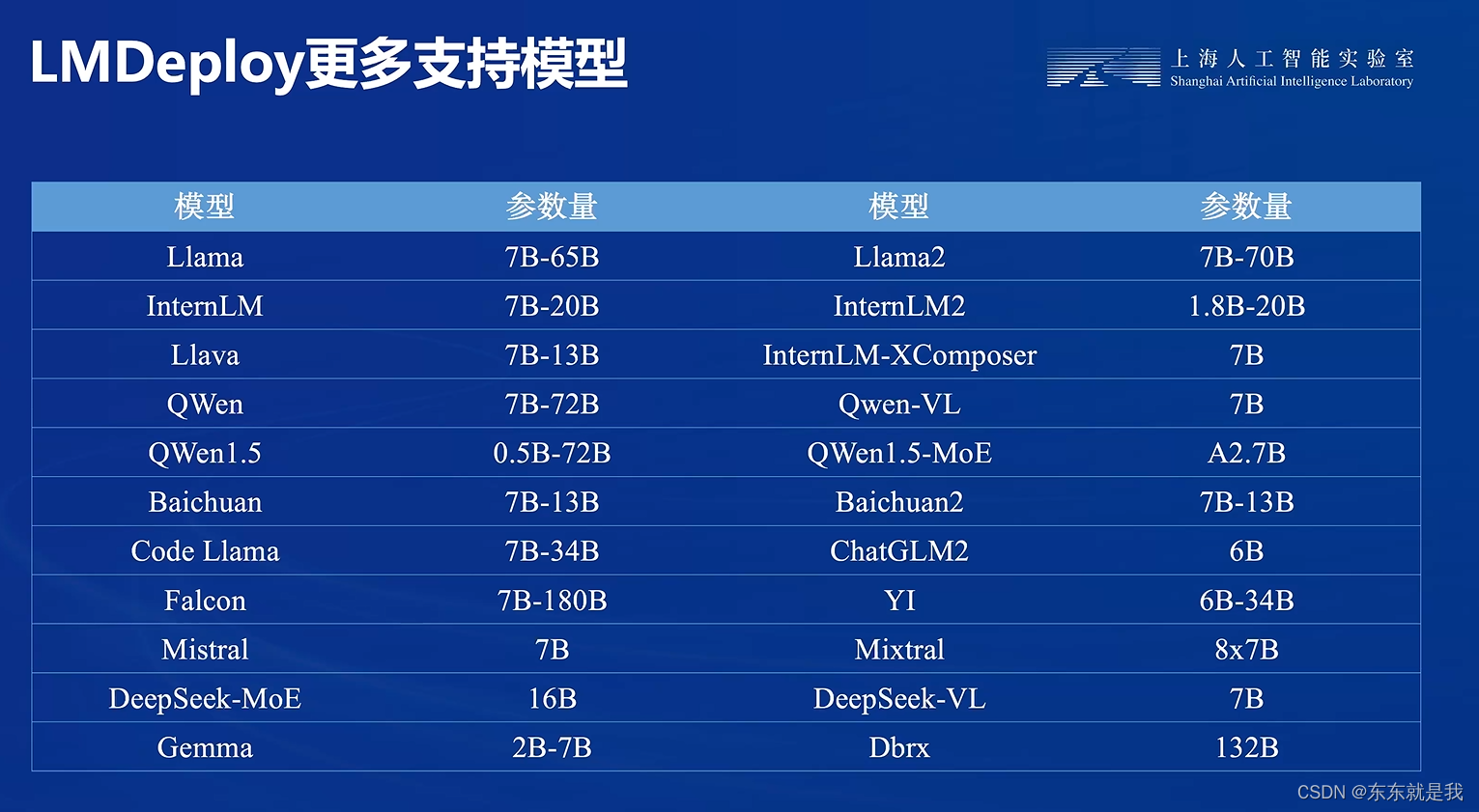
实践
安装
studio-conda -t lmdeploy -o pytorch-2.1.2
conda activate lmdeploy
pip install lmdeploy[all]==0.3.0
模型
ls /root/share/new_models/Shanghai_AI_Laboratory/
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/
# cp -r /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/
transformer运行模型
touch /root/pipeline_transformer.py
将以下内容复制粘贴进入pipeline_transformer.py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("/root/internlm2-chat-1_8b", trust_remote_code=True)
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and cause OOM Error.
model = AutoModelForCausalLM.from_pretrained("/root/internlm2-chat-1_8b", torch_dtype=torch.float16, trust_remote_code=True).cuda()
model = model.eval()
inp = "hello"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=[])
print("[OUTPUT]", response)
inp = "please provide three suggestions about time management"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=history)
print("[OUTPUT]", response)
python /root/pipeline_transformer.py
使用lmdeploy 运行模型
lmdeploy chat /root/internlm2-chat-1_8b
lmdeploy 量化
设置kv cache缓存
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.5
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.01
使用w4A16量化
安装
pip install einops==0.7.0
量化模型
lmdeploy lite auto_awq \
/root/internlm2-chat-1_8b \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /root/internlm2-chat-1_8b-4bit
运行
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq --cache-max-entry-count 0.01
lmdeploy 服务
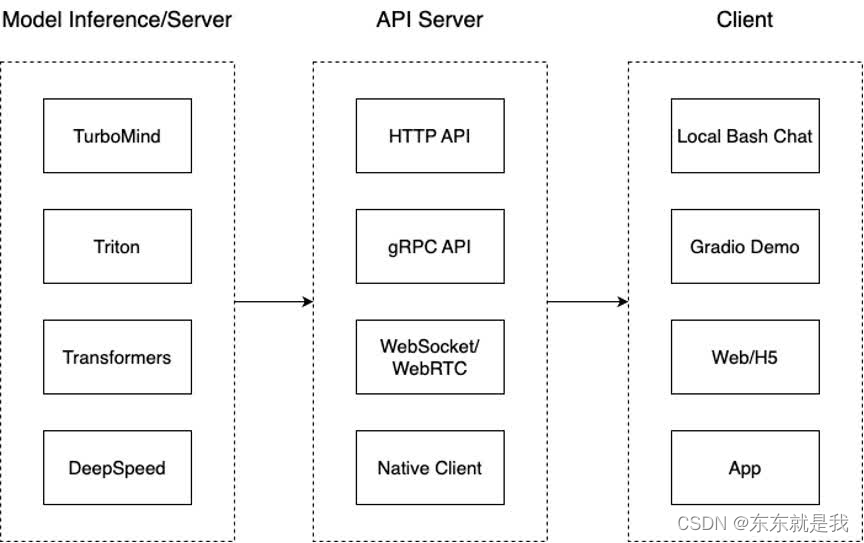
模型推理/服务。主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
API Server。中间协议层,把后端推理/服务通过HTTP,gRPC或其他形式的接口,供前端调用。
Client。可以理解为前端,与用户交互的地方。通过通过网页端/命令行去调用API接口,获取模型推理/服务。
启动服务器
lmdeploy serve api_server \
/root/internlm2-chat-1_8b \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1