🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
💫个人格言: "如无必要,勿增实体"

文章目录
- 常用经典目标检测算法概述
- 1. 滑动窗口与特征提取
- 2. Region-based方法
- R-CNN系列
- Mask R-CNN
- 3. 单阶段检测器
- YOLO系列
- SSD (Single Shot MultiBox Detector)
- 4. 基于锚框的方法
- 5. anchor-free方法
- 6. Transformer在目标检测中的应用
- 7. 总结与展望
常用经典目标检测算法概述
在计算机视觉领域,目标检测是一项基础且关键的任务,旨在从复杂背景中识别并定位出特定类别物体的位置。随着深度学习技术的发展,一系列经典的目标检测算法应运而生,为自动驾驶、视频监控、医疗影像分析等众多应用提供了强大的技术支持。本文将梳理并详细介绍几种常用的经典目标检测算法,包括其基本原理、主要特点及应用场景。
1. 滑动窗口与特征提取
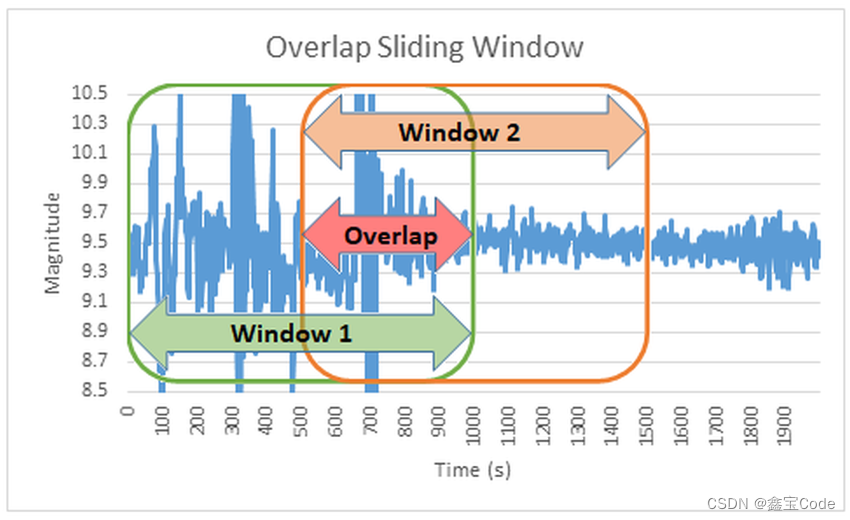
传统方法:
在深度学习流行之前,目标检测主要依赖于滑动窗口策略和手工设计的特征提取方法。代表性工作如Viola-Jones人脸检测算法,其核心在于:
-
滑动窗口:通过在图像上以不同尺度、位置移动一个固定大小的矩形窗口,对每个窗口内的区域进行分类判断,判断其是否包含目标。
-
特征提取:利用Haar特征或HOG(Histogram of Oriented Gradients)特征描述窗口内像素强度变化,以区分目标与背景。
尽管此类方法在特定场景下(如人脸检测)取得了一定效果,但面临计算量大、泛化能力有限、对目标姿态变化敏感等问题。
深度学习介入:
随着深度卷积神经网络(CNN)的兴起,特征提取部分被更强大的CNN模型所取代。例如,OverFeat算法首次将CNN应用于滑动窗口目标检测,通过共享计算实现对多个窗口的同时处理,显著提升了效率。
2. Region-based方法
R-CNN系列
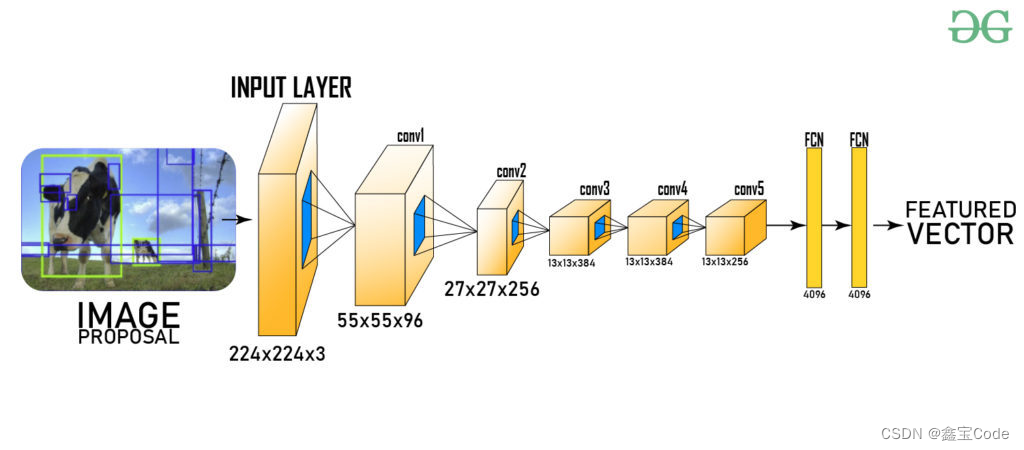
-
R-CNN (Region-based Convolutional Neural Networks):通过选择性搜索(Selective Search)生成候选区域(Region of Interest, RoI),然后对每个RoI独立地进行CNN特征提取,并通过SVM进行分类,最后使用边框回归精炼位置。R-CNN虽准确率高,但存在计算效率低、流程复杂的问题。
-
Fast R-CNN:引入RoI Pooling层,使整张图片只需经过一次CNN前向传播,所有RoI共享特征图,大大提高了计算效率。同时,将分类和边框回归任务合并到一个单一的多任务损失函数中。
-
Faster R-CNN:提出区域提议网络(Region Proposal Network, RPN),它与主干网络共享卷积层,直接从特征图上生成RoI,进一步整合了目标检测流程,成为两阶段目标检测方法的里程碑。
Mask R-CNN
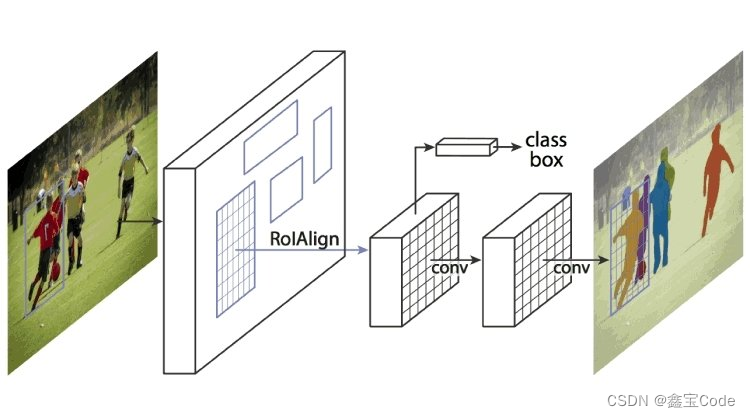
在Faster R-CNN基础上,Mask R-CNN增加了掩码分支,用于预测每个实例的精细像素级分割掩码,实现了目标检测与实例分割的统一框架。其创新点在于引入了RoIAlign层,解决了RoI Pooling带来的空间信息丢失问题,使得掩码预测更加精确。
3. 单阶段检测器
YOLO系列
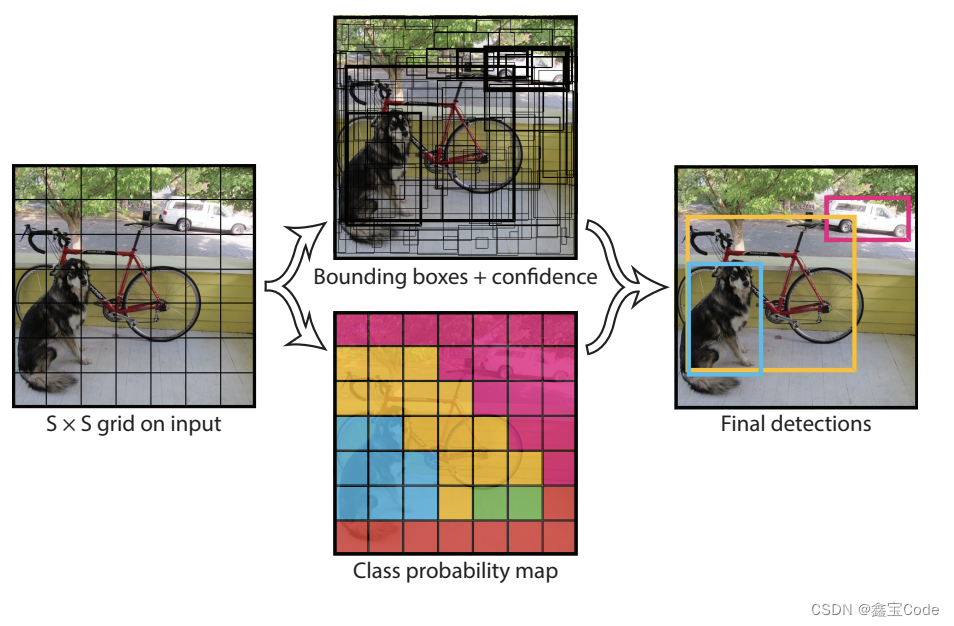
-
YOLO (You Only Look Once):开创性地提出了单阶段目标检测框架,将整幅图像一次性输入到CNN中,直接输出边界框坐标及其对应的类别概率。YOLO简化了检测流程,显著提升了速度,但早期版本在小目标检测和定位精度上略逊于两阶段方法。
-
YOLOv2/YOLO9000:通过批量归一化(Batch Normalization)、跨层连接(Skip Connections)、多尺度预测等改进,提升了检测精度和速度。同时,提出联合训练方法,实现了对超过9000类物体的实时检测。
-
YOLOv3:进一步扩大网络深度和宽度,采用更精细的特征金字塔结构,增强了对小目标的检测能力。
SSD (Single Shot MultiBox Detector)
SSD同样属于单阶段检测器,其核心思想是在不同尺度的特征图上直接预测边界框和类别概率。与YOLO相比,SSD设计了多层特征融合机制,兼顾了对小目标和大目标的检测。此外,SSD使用默认框(Anchor Boxes)而非YOLO的均匀网格,更符合实际物体尺寸分布。
4. 基于锚框的方法
除SSD外,许多后续的单阶段或多阶段检测器(如RetinaNet、RFCN等)均采用了锚框机制。锚框是一种预先设定的不同尺度、长宽比的参考框,用于预测时与ground truth进行匹配并调整,有助于提高检测器对各种形状目标的适应性。
5. anchor-free方法
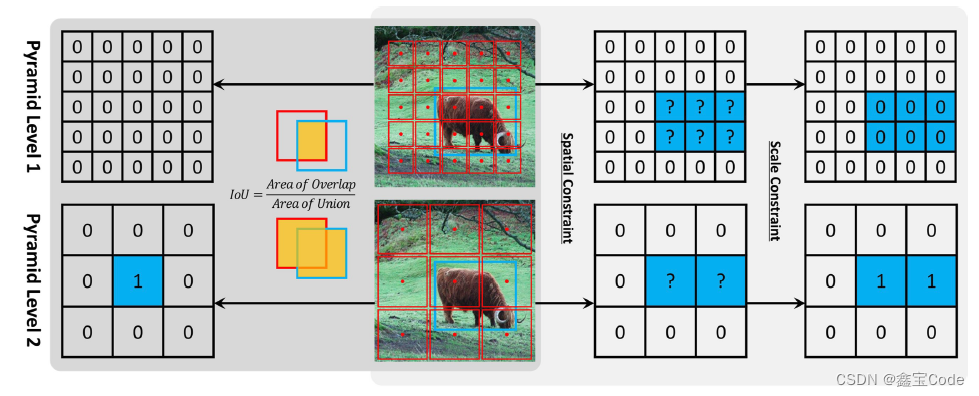
近期,无锚框(anchor-free)的目标检测方法受到关注,它们试图摆脱对预定义锚框的依赖,简化模型结构并提高检测性能。
-
CornerNet:通过直接预测物体的左上角和右下角坐标,以及相应的嵌入向量来区分同一类别的不同实例。
-
CenterNet:进一步简化,仅预测物体中心点、宽高和类别,利用热力图表示中心点,显著降低了模型复杂度。
-
FCOS (Fully Convolutional One-Stage Object Detection):完全基于全卷积网络,每个像素预测所属目标的类别、距离边界框四个边的距离以及是否为中心点,避免了复杂的锚框设计和匹配过程。
6. Transformer在目标检测中的应用
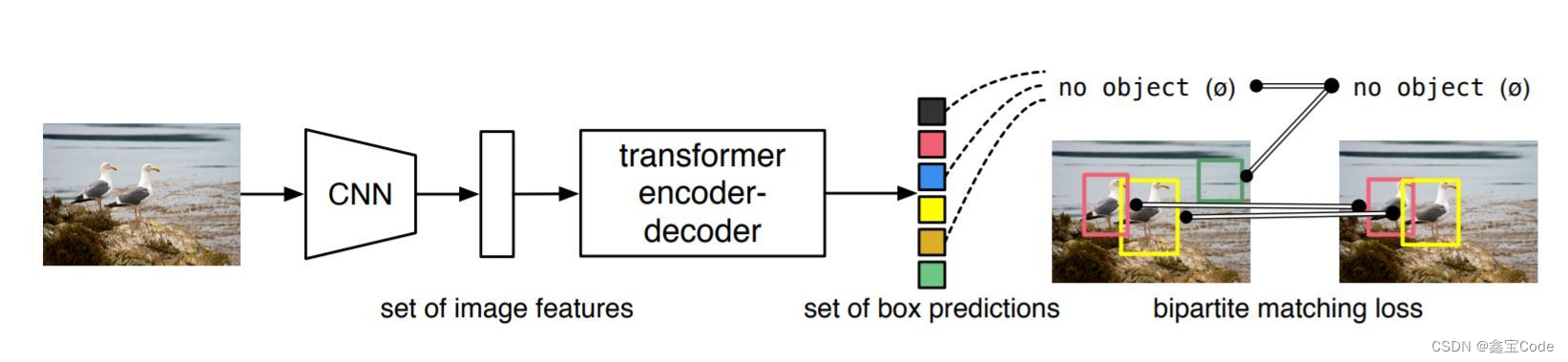
随着Transformer在自然语言处理领域的成功,其自注意力机制也被引入目标检测任务。DETR(Detection Transformer)是首个将Transformer用于端到端目标检测的模型,通过编码器-解码器架构,直接预测出固定数量的边界框及其类别,无需非极大值抑制(NMS)等后处理步骤,简化了目标检测流程。
7. 总结与展望
经典目标检测算法从最初的滑动窗口、手工特征,发展到深度学习驱动的两阶段、单阶段、基于锚框、无锚框乃至Transformer模型,不断在精度与速度之间寻找平衡,适应各类应用场景的需求。未来,目标检测研究将继续探索更高效、更鲁棒的模型架构,可能的方向包括:
-
轻量化与加速:针对边缘设备和实时应用,研发更小、更快的检测模型。
-
多模态融合:结合图像、文本、语音等多源信息,提升复杂场景下的检测性能。
-
开放世界检测:处理未见类别和异常情况,增强模型的泛化能力和适应性。
-
跨域迁移:减少对大规模标注数据的依赖,实现模型在不同数据集、任务间的有效迁移。
以上就是常用经典目标检测算法的概述。随着技术的不断创新与演进,我们期待看到更多前沿成果推动目标检测技术迈上新的台阶。



](https://img-blog.csdnimg.cn/direct/8417c872a6c44a93923dd1d5d72e4671.png)