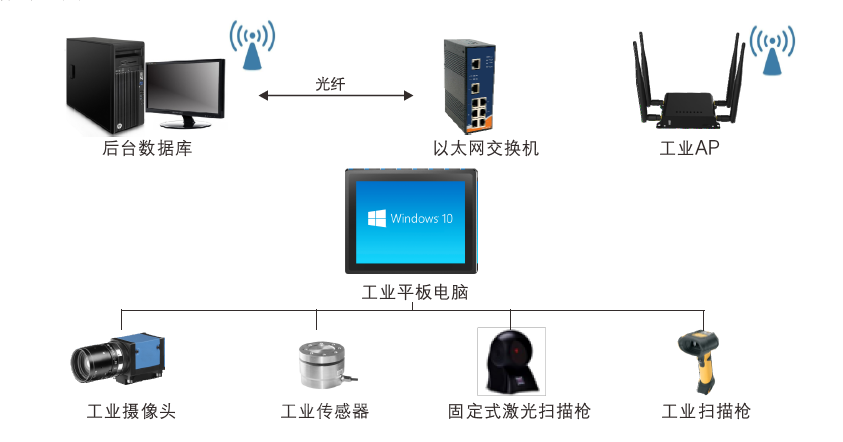
在 HuggingFace 上下载模型时,经常会看到模型的名称会带有fp16、GPTQ,GGML等字样,对不熟悉模型量化的同学来说,这些字样可能会让人摸不着头脑,我开始也是一头雾水,后来通过查阅资料,总算有了一些了解,本文将介绍一些常见的模型量化格式,因为我也不是机器学习专家,所以本文只是对这些格式进行简单的介绍,如果有错误的地方,欢迎指正。
What 量化
量化在 AI 模型中,特别是在深度学习模型中,通常指的是将模型中的参数(例如权重和偏置)从浮点数转换为低位宽度的整数,例如从 32 位的浮点数转换为 8 位整数。通俗地说,量化就像是把一本详细的、用高级词汇写的书简化为一个简短的摘要或儿童版故事。这个摘要或儿童版故事占用的空间更小,更容易传播,但可能会丢失一些原始书中的细节。
Why 量化
量化的目的主要有以下几点:
- 减少存储需求:量化后的模型大小会显著减小,这使得模型更容易部署在存储资源有限的设备上,如移动设备或嵌入式系统。
- 加速计算:整数运算通常比浮点运算更快,尤其在没有专门的浮点硬件支持的设备上。
- 减少能耗:在某些硬件上,整数运算消耗的能量更少。
但是,量化也有一个缺点:它可能会导致模型的精度下降。因为你实际上是在用较低的精度来表示原始的浮点数,可能会损失一些信息,这意味着模型的能力会变差。为了平衡这种精度损失,研究者们开发了各种量化策略和技术,如动态量化、权重共享等,可以在尽量少降低模型能力的情况下,尽可能多地降低模型所需的损耗。打个比方,如果我们一个模型的完整能力是 100,模型大小和推理所需内存也是 100,我们将这个模型量化后,模型的能力可能会降低到 90,但模型大小和推理所需内存可能会降低到 50,这个就是量化的目的。
FP16/INT8/INT4
HuggingFace 上模型名称如果没有特别标识,比如Llama-2-7b-chat、chatglm2-6b,那么说明这些模型一般是全精度的(FP32,但也有些是半精度 FP16),而如果模型名称中带有fp16、int8、int4等字样,比如Llama-2-7B-fp16、chatglm-6b-int8、chatglm2-6b-int4,那么说明这些模型是量化后的模型,其中fp16、int8、int4字样表示模型的量化精度。
量化精度从高到低排列顺序是:fp16>int8>int4,量化的精度越低,模型的大小和推理所需的显存就越小,但模型的能力也会越差。
以ChatGLM2-6B为例,该模型全精度版本(FP32)的大小为 12G,推理所需用到的显存为 12~13G,而量化后的 INT4 版本模型大小为 3.7G,推理所需显存为 5G,可以看到量化后的模型大小和显存需求都大大减小了。
FP32 和 FP16 精度的模型需要在 GPU 服务器上运行,而 INT8 和 INT4 精度的模型可以在 CPU 上运行。
GPTQ
GPTQ 是一种模型量化的方法,可以将语言模型量化成 INT8、INT4、INT3 甚至 INT2 的精度而不会出现较大的性能损失,在 HuggingFace 上如果看到模型名称带有GPTQ字样的,比如Llama-2-13B-chat-GPTQ,说明这些模型是经过 GPTQ 量化的。以Llama-2-13B-chat为例,该模型全精度版本的大小为 26G,使用 GPTQ 进行量化成 INT4 精度后的模型大小为 7.26G。
如果你用的是开源模型LLama,可以使用GPTQ-for-LLaMA这个库来进行 GPTQ 量化,它可以将相关的Llama模型量化成 INT4 精度的模型。
但现在更流行的一个 GPTQ 量化工具是AutoGPTQ,它可以量化任何 Transformer 模型而不仅仅是Llama,现在 Huggingface 已经将 AutoGPTQ 集成到了 Transformers 中,具体的使用方法可以参考这里。
GGML
讲 GGML 之前要先说下llama-cpp这个项目,它是开发者 Georgi Gerganov 基于 Llama 模型手撸的纯 C/C++ 版本,它最大的优势是可以在 CPU 上快速地进行推理而不需要 GPU。然后作者将该项目中模型量化的部分提取出来做成了一个模型量化工具:GGML,项目名称中的GG其实就是作者的名字首字母。
在 HuggingFace 上,如果看到模型名称带有GGML字样的,比如Llama-2-13B-chat-GGML,说明这些模型是经过 GGML 量化的。有些 GGML 模型的名字除了带有GGML字样外,还带有q4、q4_0、q5等,比如Chinese-Llama-2-7b-ggml-q4,这里面的q4其实指的是 GGML 的量化方法,从q4_0开始往后扩展,有q4_0、q4_1、q5_0、q5_1和q8_0,在这里可以看到各种方法量化后的数据。
GGUF
最近在 HuggingFace 上的模型还发现了一些带有GGUF字样的模型,比如Llama-2-13B-chat-GGUF,GGUF其实是 GGML 团队增加的一个新功能,GGUF 与 GGML 相比,GGUF 可以在模型中添加额外的信息,而原来的 GGML 模型是不可以的,同时 GGUF 被设计成可扩展,这样以后有新功能就可以添加到模型中,而不会破坏与旧模型的兼容性。
但这个功能是Breaking Change,也就是说 GGML 新版本以后量化出来的模型都是 GGUF 格式的,这意味着旧的 GGML 格式以后会慢慢被 GGUF 格式取代,而且也不能将老的 GGML 格式直接转成 GGUF 格式。
关于 GGUF 更多的信息可以参考这里。
GPTQ vs GGML
GPTQ 和 GGML 是现在模型量化的两种主要方式,但他们之间有什么区别呢?我们又应该选择哪种量化方式呢?
两者有以下几点异同:
- GPTQ 在 GPU 上运行较快,而 GGML 在 CPU 上运行较快
- 同等精度的量化模型,GGML 的模型要比 GPTQ 的稍微大一些,但是两者的推理性能基本一致
- 两者都可以量化 HuggingFace 上的 Transformer 模型
因此,如果你的模型是在 GPU 上运行,那么建议使用 GPTQ 进行量化,如果你的模型是在 CPU 上运行,那么建议使用 GGML 进行量化。

Groupsize
在 HuggingFace 上,不管是什么格式的量化模型,模型名称中还经常出现一些32g、128g字样,比如pygmalion-13b-4bit-128g,这些又是表示什么意思呢?
128g中的g其实表示的是 groupsize 的意思,在量化技术中,权重可能会被分成大小为 groupsize 的组,并对每组应用特定的量化策略,这样的策略可能有助于提高量化的效果或保持模型的性能。
groupsize 的值有:1024、128、32,GPTQ 默认的 groupsize 值是 1024。如果 groupsize 没有值,那么 groupsize 就为-1( 注意不是 0)。groupsize 会影响模型的准确性和推理显存大小,groupsize 根据同等精度模型准确性和推理显存从高到底的排列顺序是:32 > 128 > 1024 > None(-1),也就是说 None(-1) 是准确性和显存占用最低的,而 32 是最高的。
总结
本文总结了 HuggingFace 上模型的常见量化格式,量化技术是 AI 模型部署的重要技术,它可以大大减小模型的大小和推理所需的显存。想要让大语言模型真正地走进普通人的生活,在每个人的手机上能运行起来,做到真正意义上的“普及”,那么量化技术以后肯定是必不可少的,因此掌握一些量化技术是非常有必要的。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。








![【Hadoop】- YARN架构[7]](https://img-blog.csdnimg.cn/direct/473efa710d864050853785ac7e785f1c.png)