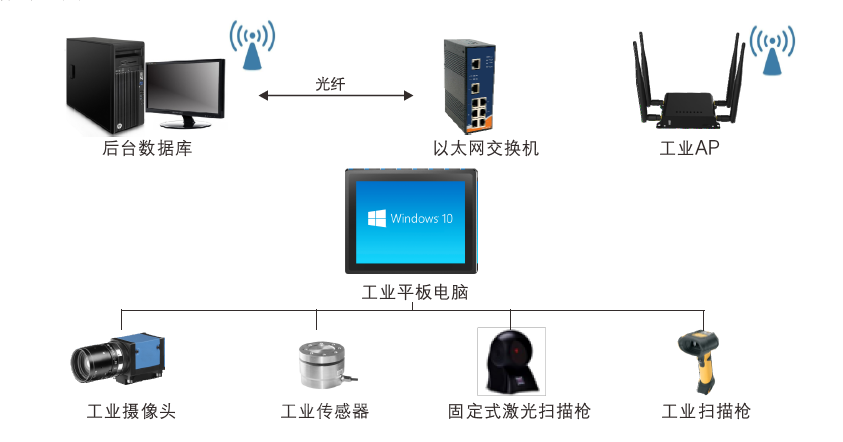
文章目录
- 解决方案
- 步骤
- 示例代码
- 结论
在处理复杂的SQL查询时,我们经常会遇到需要多次引用子查询或中间结果的情况。这可能会使得查询变得冗长且难以理解。为了解决这个问题,PostgreSQL(以及其他一些SQL数据库系统)引入了公共表表达式(Common Table Expressions,简称CTE)的概念。CTE允许我们定义一个临时的结果集,这个结果集可以在后续的查询中被多次引用,从而使查询逻辑更清晰、更易于维护。
解决方案
使用CTE,你可以将复杂的查询分解为多个逻辑部分,每个部分都可以单独定义和测试。然后,你可以在主查询中引用这些CTE,以构建最终的查询结果。
步骤
- 定义CTE:使用
WITH子句来定义CTE。每个CTE都有一个名称和一个查询定义。 - 引用CTE:在后续的查询中,你可以像引用普通的表或视图一样引用CTE。
- 构建主查询:使用CTE和其他表或视图来构建你的主查询。
示例代码
假设我们有一个名为orders的表,其中包含订单信息,以及一个名为customers的表,其中包含客户信息。我们想要找出每个客户的总订单金额,并筛选出总金额超过某个阈值的客户。
不使用CTE的查询可能会是这样:
SELECT
c.customer_id,
c.customer_name,
SUM(o.order_amount) AS total_order_amount
FROM
customers c
JOIN
orders o ON c.customer_id = o.customer_id
GROUP BY
c.customer_id, c.customer_name
HAVING
SUM(o.order_amount) > 1000;
这个查询虽然功能正确,但如果逻辑更复杂,就会很难维护。现在,我们使用CTE来简化这个查询:
WITH TotalOrders AS (
SELECT
c.customer_id,
c.customer_name,
SUM(o.order_amount) AS total_order_amount
FROM
customers c
JOIN
orders o ON c.customer_id = o.customer_id
GROUP BY
c.customer_id, c.customer_name
)
SELECT
customer_id,
customer_name,
total_order_amount
FROM
TotalOrders
WHERE
total_order_amount > 1000;
在这个示例中,我们首先定义了一个名为TotalOrders的CTE,它计算了每个客户的总订单金额。然后,在主查询中,我们简单地从这个CTE中选择出总金额超过1000的客户。这种方法使得查询逻辑更加清晰,也更容易维护。
结论
CTE是处理复杂SQL查询时的一个强大工具。它们允许你将查询分解为多个逻辑部分,使得每个部分都可以单独测试和优化。通过使用CTE,你可以创建出更易于理解和维护的查询逻辑,从而提高开发效率并减少错误。
相关阅读推荐
- 在Postgres中如何有效地管理大型数据库的大小和增长
- PostgreSQL中的索引类型有哪些,以及何时应选择不同类型的索引?
- 如何配置Postgres的自动扩展功能以应对数据增长
- 如何通过Postgres的日志进行故障排查
- 如何使用Postgres的JSONB数据类型进行高效查询
- Postgres数据库中的死锁是如何产生的,如何避免和解决
- 新项目应该选mongodb还是postgresql

↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓







![【Hadoop】- YARN架构[7]](https://img-blog.csdnimg.cn/direct/473efa710d864050853785ac7e785f1c.png)