目录
编辑
1. 选择排序基本思想
2. 直接选择排序
2.1 实现步骤
2.2 代码示例
2.3 直接选择排序的特性总结
3. 堆排序
3.1 实现步骤
3.2 代码示例
3.3 堆排序的特性总结
1. 选择排序基本思想
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。
2. 直接选择排序
2.1 实现步骤
1.从待排序序列中选择最小(或最大)的元素,将其与序列中的第一个元素交换位置。
2.在剩余的未排序序列中选择最小(或最大)的元素,将其与序列中的第二个元素交换位置。
3.重复上述步骤,每次在剩余未排序序列中选择最小(或最大)的元素,放到已排序部分的末尾,直到所有元素都被排序。
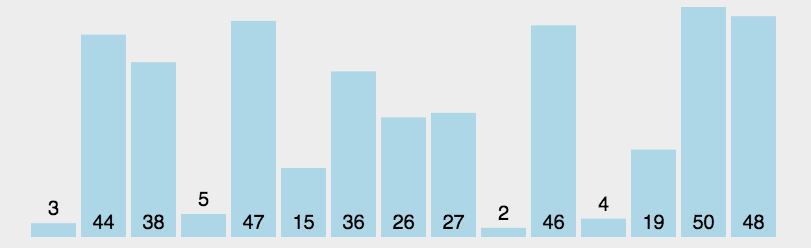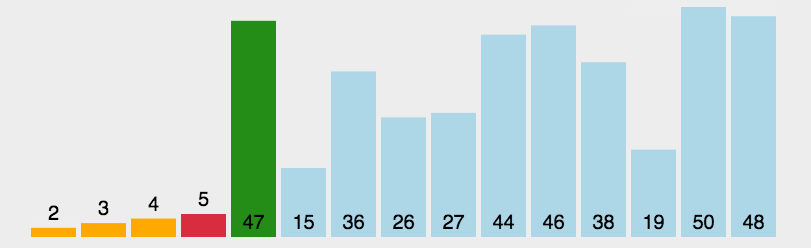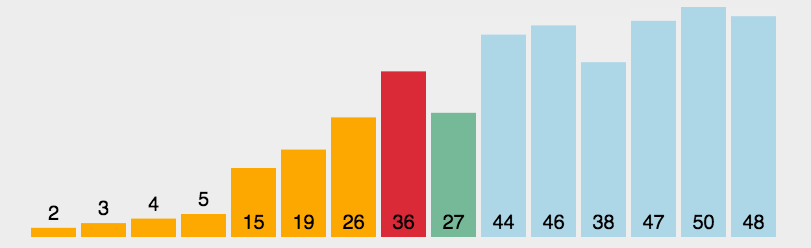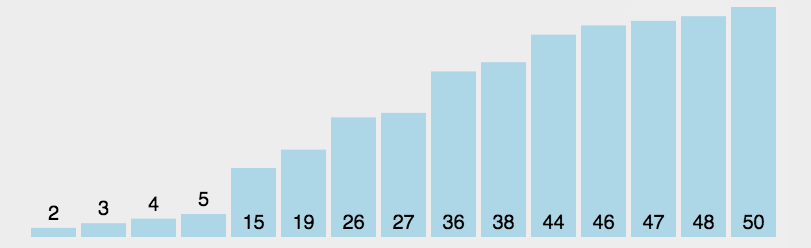
2.2 代码示例
//交换
void Swap(int* p, int* q)
{
int tmp = *p;
*p = *q;
*q = tmp;
}
//选择排序
void SelectSort(int* a, int n)
{
int begin = 0, end = n - 1;
while (begin < end)
{
//定义最小值和最大值的下标
int mini = begin, maxi = begin;
//每次找到未排序部分的最小值和最大值的下标
for (int i = begin + 1; i <= end; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
//将找到的最小元素与未排序部分的第一个元素交换位置
Swap(&a[begin], &a[mini]);
//如果最大元素的下标和begin位置重复了,就更新最大元素的下标
if (maxi == begin)
{
maxi = mini;
}
//将找到的最大元素与未排序部分的最后一个元素交换位置
Swap(&a[end], &a[maxi]);
++begin;
--end;
}
}
//打印
void PrintSort(int* a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
//测试
int main()
{
int a[] = { 13, 5, 7, 19, 0, 12, 4, 8, 8, 16 };
SelectSort(a, sizeof(a) / sizeof(int));
PrintSort(a, sizeof(a) / sizeof(int));
return 0;
}
2.3 直接选择排序的特性总结
1. 直接选择排序思考非常好理解,但是效率不是很好。因此,选择排序通常不适用于大规模数据集,但在少量元素的情况下可能是一种不错的选择。
2. 时间复杂度:选择排序每次从未排序部分选择最小(或最大)的元素放到已排序部分的末尾,因此它的时间复杂度为O(N^2),其中n是数组的大小。即使在最好的情况下,选择排序的时间复杂度也是O(N^2)。
3. 空间复杂度:O(1)。
4. 稳定性:不稳定
3. 堆排序
3.1 实现步骤
堆是一种特殊的完全二叉树,分为最大堆和最小堆。需要注意的是排升序要建大堆,排降序建小堆。
基本思想:
- 将待排序的序列构建成一个最大堆。
- 从最大堆中取出堆顶元素(最大元素),将其与堆中最后一个元素交换位置,然后将剩余元素重新调整成大堆。
- 重复上述步骤,直到所有元素都被取出,最终得到一个有序序列。
实现步骤:
- 构建最大堆:从最后一个非叶子节点开始,依次向上调整使得每个节点都满足最大堆的性质。
- 将堆顶元素与堆中最后一个元素交换位置,然后将剩余元素重新调整成大堆。
- 重复上述步骤,直到所有元素都被取出,最终得到一个有序序列。

3.2 代码示例
//交换
void Swap(int* p, int* q)
{
int tmp = *p;
*p = *q;
*q = tmp;
}
//向下调整
void AdjustDown(int* a, int size, int parent)
{
int child = parent * 2 + 1;
while (child < size)
{
// 假设左孩子小,如果假设错了,就更新一下
if (child + 1 < size && a[child + 1] > a[child])
{
++child;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
// 堆排序
void HeapSort(int* a, int n)
{
// O(N)
// 构建大堆
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
// O(N*logN)
//依次取出堆顶元素,调整
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
--end;
}
}
//打印
void PrintSort(int* a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
//测试
int main()
{
int a[] = { 1, 5, 7, 9, 0, 2, 4, 8, 8, 6 };
HeapSort(a, sizeof(a) / sizeof(int));
PrintSort(a, sizeof(a) / sizeof(int));
return 0;
}
3.3 堆排序的特性总结
- 堆排序虽然效率高,但在数据量较小的情况下可能不如其他简单的排序算法,因为构建堆的过程比较耗时。
- 时间复杂度:O(N*logN),其中N是待排序序列的长度。
- 空间复杂度:堆排序是一种原地排序算法,不需要额外的空间来存储临时数据,只需要在原数组上进行操作,所以它的空间复杂度为O(1)。
- 稳定性:不稳定,即相同元素的相对位置在排序后可能发生变化。