R语言介绍
为什么使用R?
R:数据分析与可视化平台
R的获取和安装
http://cran.r-project.org 免费下载
一、R、Rtools安装
R语言:
-
免费开源
-
支持多平台,包括Windows、UNIX、Mac OS
-
擅长统计与可视化
Rtools:R语言辅助工具
安装:https://blog.csdn.net/Xingchen0101/article/details/126047772
二、Rstudio安装
Rstudio:R语言的集成开发环境(IDE)
安装:https://blog.csdn.net/Xingchen0101/article/details/126047772
三、配置Rtools路径
方法一:https://blog.csdn.net/Xingchen0101/article/details/126047772
方法二:
# 配置
install.packages('installr')
library(installr)
install.Rtools()
# 测试
Sys.which("make")
install.packages('devtools')四、Rstudio介绍
-
R版本选择
-
R镜像配置
chooseCRANmirror()
chooseBioCmirror()
-
Rstudio窗口、功能了解
-
脚本运行方式:单行运行、选中运行、整体运行
-
脚本注释
-
脚本创建和保存
-
用Rproject管理项目
五、创建新变量
变量名 <- 表达式
a <- 1+1
b <- 10-9
常用算术运算符
| + | 加 |
|---|---|
| - | 减 |
| * | 乘 |
| / | 除 |
| ^或** | 求幂 |
| x%%y | 求余(x mod y)5%%2的结果为1 |
| x%/%y | 整数除法 5%/%2的结果为2 |
课后小结-快捷键
运行:Windows是Atrl + Enter,Mac是Cmd + Enter
赋值号:Alt + -
注释:Ctrl+Shift+C
保存:Ctrl + S
清空控制台:Ctrl + L
一、R包介绍
R包是R函数、数据集、帮助文档等的集合。计算机上存储包的目录称为库(library)。R自带了一系列默认包(包括base、datasets等),它们提供了种类繁多的默认函数和数据集。
其他R包可通过下载来进行安装,不同的R包都有各自特定的功能。
R包网址:
CRAN清华镜像网址 https://mirrors.tuna.tsinghua.edu.cn/CRAN/
Bioconductor官网 https://www.bioconductor.org/packages/release/BiocViews.html#___Software
Github网址 https://github.com/lijian13/rinds【rinds包】
二、R包安装
# 清除对象
rm(list = ls())
# 直接安装包
install.packages("BiocManager")
install.packages('devtools')
install.packages('ggpubr')
# 从Bioconductor安装
BiocManager::install("clusterProfiler")
# 从Github上安装
devtools::install_github('lijian13/rinds') #前为用户名,后为包名
# 需要连接外网下载
# 从本地安装
devtools::install_local("D:/Shortcut/Desktop/A3_1.0.0.tar.gz")
包的两种调用方法
方法一:加载到环境中,包中的所有命令可以直接调用
library(BiocManager)
install( "clusterProfiler")
方法二:一次性调用,只能运行一个命令,包中的其他命令不可以直接调用
BiocManager::install( "clusterProfiler")
检验是否安装成功
方法一:加载包 library(ggpubr)
方法二:Rstudio里查看
一个包的安装思路
直接安装包—从Bioconductor安装—从Github上安装—从网站下载XX.tar.gz文件,从本地安装
三、R包操作
# 加载包
library(ggpubr)
require(ggpubr)
# 从环境中去除加载的R包
detach("package:ggpubr")
# 删除包
remove.packages("ggpubr")
# 更新包
update.packages()
四、R包查看
# 查看已经安装的包
installed.packages()
library()
# 查看环境中已经加载的包
search()
# 查看包的安装位置
.libPaths()
# 更改包的安装位置
.libPaths(new = "D:/新的/路径")
# 注意R里的路径是左斜杠
# 查看包的帮助信息
help(package="ggplot2")
# 列出R包中包含的所有数据集
data(package="ggplot2")
# R包版本查询
packageVersion("ggplot2")
五、看懂控制台输出信息
| 类型 | 控制台输出 | 做法 |
|---|---|---|
| 运行结果 |
| 命令运行结束 |
| 报错Error |
| 命令运行失败,检查问题 |
| 警告:Warning |
| 一般可忽略 |
| 命令正在运行 |
| 等待或者中断运行 |
| 命令不完整 |
| 按esc键退出,或者补全命令 |
| 询问选择 |
| 【a/s/n】先n,不行再a;【yes/no】先no,不行再yes |
| 没输出 |
| 命令已成功运行 |






课后小结
安装R包时需要加双引号"package_name",或者单引号'package_name',加载R包时不需要,引号是英文状态下的引号。
一条命令更新所有R包
install.packages("rvcheck")
library(rvcheck)
# 检查R版本
rvcheck::check_r()
# 更新所有R包
rvcheck::update_all(check_R=FALSE,which=c("CRAN","BioC","github"))R的使用
(1)R区分大小写
(2)R语句是由函数和赋值构成的;R的赋值符号<
(3)工作空间
getwd()#查看当前的工作目录
setwd()#设定当前的工作目录,括号内有引号
(4)R中的路径都要用正斜杠/
(5)文本输入:函数source("")#此脚本必须要在当前工作目录下
(6)包的安装 install.packages("")
包的更新 update.packages("")
(7)包的载入 library()#不需要引号
数据类型与数据结构—初识与类型判断
数据类型判断
class()函数用于查看数据类型,用法是class(变量名)
注意事项
-
括号是英文状态下的
-
变量名不用加引号
-
TRUE和FALSE的全写或简写形式都要大写
对象(object)
对象:是指可以赋值给变量的任何事物,包括常量、数据结构、函数,甚至图形。(赋值号右侧内容)
对象名称:必须以字母开头,并且只能包含字母、数字、_ 和 . (赋值号左侧内容)
2.R语言:创建数据集
向量、因子、矩阵、数据框以及列表
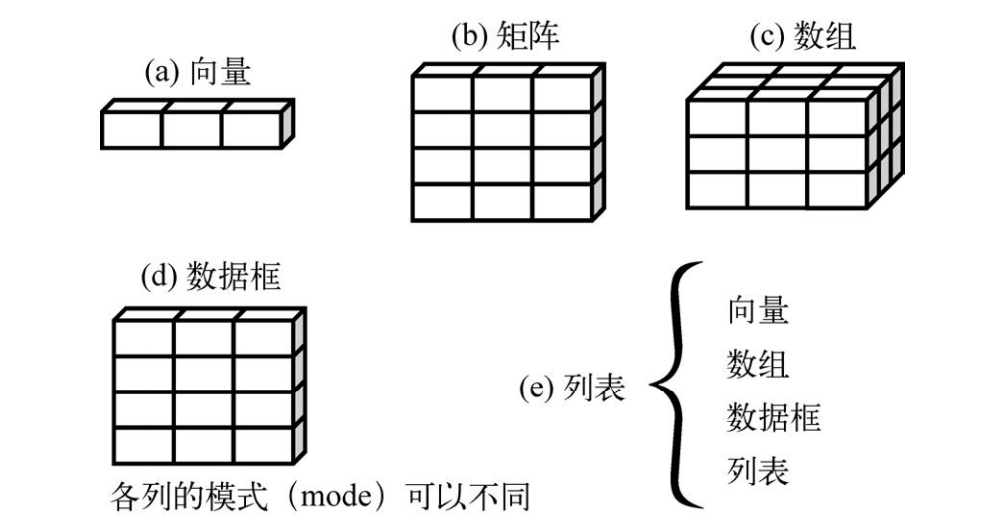
摘自《R语言实战》
# 向量
v1 <- c(1,5,3,3);v1
v2 <- c("A","B","C","D");v2
v3 <- c(TRUE,TRUE,FALSE,FALSE);v3
# 矩阵
mat <- matrix(1:20,nrow=5,ncol=4)
mat
# 数组
ar <- array(1:24,c(2,4,3))
ar
# 数据框
df <- data.frame(v1,v2,v3)
df
# 列表
list1 <- list(v1,v2,v3,df)
list1数据结构判断
class()函数也可用于判断数据结构
class(v1)
class(mat)
class(ar)
class(df)
class(list1)

向量:用函数c()创建
-
单个向量中的数据必须拥有相同的类型或模式
-
(数值型、字符型或逻辑型)
-
方括号:我们可以访问向量中的特定元素
#创建变量
a <- c(1, 2, 5, 3, 6, -2, 4)
b <- c("one", "two", "three")
c <- c(TRUE, TRUE, TRUE, FALSE, TRUE, FALSE)
#使用中括号访问元素
a <- c(1, 2, 5, 3, 6, -2, 4)
a[3]
a[c(1, 3, 5)]
a[2:6]
向量(vector)是用于存储数值型、字符型、逻辑型数据的一维数组。
向量创建
普通向量 c()
c(1,5,3,3) #数值型向量
c("A","B","C","D") # 字符型向量
c(TRUE,TRUE,FALSE,FALSE) # 逻辑型向量
2:6 # 连续整数型向量的快捷创建
重复型 rep()
参数each指定每个元素重复几次,参数times指定整个向量重复几次,each优先于times。
rep("a", times = 3)
rep(c(a,b), times = 3)
rep(c(1,6), each = 3)
rep(c(1,6),times=4,each=2)
序列型 seq()
参数by指定步长,参数length.out指定产生的元素个数
seq(from = 1, to = 3, by = 0.3)
seq(from = 10, to = 1, by = -1)
seq(1, 3, length.out = 10)
数据类型自动转换
优先次序:字符型>数值型>逻辑型
c("m",2)
c("m",TRUE)
c(2,FALSE)
注意事项
-
单个向量内部必须具有相同的数据类型(数值型、字符型、逻辑型)
-
标量是只含有一个元素的向量,它们用于保存常量。
向量索引
x <- 11:20
x[2]
x[c(2,4,5)]
x[2:5]
x[-c(2,5)]
x[-(2:5)]
修改向量中部分元素
x[c(2,4,5)] <- c(2,4,5)
x
理解向量化运算
weight <- c(68,72,57,90,65,81)
height <- c(175,180,165,190,172,181)
bizhi <- weight/height
# 向量化运算的自动补齐
a <- 1:5
b <- 1:3
a+b
课后小结
?函数名:查看函数的帮助。如?rep()
矩阵(matrix)
是由相同数据类型的元素构成的二维数组,数据类型为数值型、字符型或逻辑型。
矩阵:函数matrix()创建

矩阵下标的使用
矩阵创建
data1 <- 1:12
rnames <- c('A','B','C')
cnames <- c('V1','V2','V3','V4')
# 按列排列(默认)
mat1 <- matrix(data = data1, nrow = 3, ncol = 4, byrow = F,
dimnames = list(rnames,cnames))
mat1
# 按行排列
mat2 <- matrix(data = data1, nrow = 3, ncol = 4, byrow = T,
dimnames = list(rnames,cnames))
mat2
data2 <- 1:8
mat3 <- matrix(data = data2, nrow = 2)
mat3
mat4 <- matrix(data = data2, nrow = 4)
mat4
矩阵索引
# 取出矩阵的第一行
mat1[1,]
# 取出矩阵的第一列
mat1[,1]
# 取出矩阵第2列的第1-3个元素
mat1[1:3,2]
矩阵运算
# 矩阵转置
t(mat1)
# 矩阵加法
mat1 + mat2
# 矩阵相乘(要求“第一个矩阵列数”等于“第二个矩阵行数”)
mat3 %*% mat4
# 取矩阵对角线上的值
diag(mat1)
# 求方阵逆矩阵
solve(mat3[,1:2])
# 求方阵的行列式
det(mat3[,1:2])
矩阵函数
# 求矩阵列求和、求平均
colSums(mat1)
colMeans(mat1)
# 求矩阵行求和、求平均
rowSums(mat1)
rowMeans(mat1)
拓展
注意矩阵中只能有一种数据类型,只要有一个元素为字符型,则其他元素都会是字符型。
有时在采用矩阵进行数值运算时,可能会因为掺入了字符型数据而报错,这时要对矩阵的数据类型进行排查。
数组 & 列表—创建、索引
数据框可通过函数data.frame()创建
-
mydata$A:记号$是被用来选取一个给定数据框中的某个特定变量
-
在每个变量名前都键入一次mydata$很麻烦
-
可以联合使用函数attach()和detach()或单独使用函数with()来简化代码
-
函数attach()可将数据框添加到R的搜索路径中
-
函数attach()可将数据框添加到R的搜索路径中
-
函数detach()将数据框从搜索路径中移除
数组
数组(array)与矩阵类似,数组中的数据类型也只能有一种,但是维数可以大于2。
两种创建方式。
数组创建
# 方式一
ary1 <- array(data = 1:24)
dim(ary1) <- c(3,4,2)
ary1
# 方式二
dim1 <- c('A1','A2','A3')
dim2 <- c('B1','B2','B3','B4')
dim3 <- c('C1','C2')
ary2 <- array(data = 1:24,dim = c(3,4,2),dimnames = list(dim1,dim2,dim3))
ary2
数组索引
ary2[2,3,1]
列表
列表(list)是一种最复杂的数据结构,它可以由不同的对象混合构成。列表中的对象可以是向量、矩阵、数组、数据框以及列表本身。
列表创建
a <- 1:10
b <- c("one","two","three")
c <- matrix(1:8,nrow = 2)
d <- array(1:18,c(2,3,3))
list1 <- list(A=a,B=b,C=c,D=d)
list1
列表索引
# 方法一
list1$B
# 方法二
list1[[2]]
拓展
数据框中要求每个列向量的长度相同,而列表没有要求,所以当多个向量的长度不等时通常用列表存储。
R中函数的返回结果中通常包含了不同的对象,因而也常用列表存储。
逻辑运算符&数据类型转换
逻辑运算符
| 运算符 | 描述 |
|---|---|
| < | 小于 |
| <= | 小于或等于 |
| > | 大于 |
| >= | 大于或等于 |
| == | 等于 |
| != | 不等于 |
| !x | 非x |
| x|y | x或y |
| x&y | x和y |
| all() | 全部为真则为真 |
| any() | 至少一个为真则为真 |
用法示例
8>5
8==5
8!=5
v <- 1:10
# 判断向量中的数是否大于5
v>5
# 取出向量中大于5的数
v[v>5]
# 取出向量中不等于5的数
v[v!=5]
# 取出向量中不大于5的数
v[!v>5]
x <- -5
y <- 5
# 判断x和y是否大于0
x>0 & y>0
# 判断x或y是否大于0
x>0 | y>0
# 都满足条件才为真
all(c(x,y)>0)
# 任一个满足条件就为真
any(c(x,y)>0)
错误示范
# 判断x和y是否大于0
x&y >0
数据类型判断与转换
| 判断 | 转换 |
|---|---|
| is.numeric() | as.numeric() |
| is.character() | as.character() |
| is.logical() | as.logical() |
| is.vector() | as.vector() |
| is.matrix() | as.matrix() |
| is.array() | as.array() |
| is.list() | as.list() |
| is.data.frame() | as.data.frame() |
| is.factor() | as.factor() |
用法示例
x <- c(TRUE,FALSE,TRUE)
is.logical(x)
x
x <- as.numeric(x)
is.numeric(x)
x
x <- as.character(x)
is.character(x)
x
小贴士
可以通过()指定逻辑运算优先级,()内优先运算。
R中实用函数汇总
长度函数
# 求向量长度,即向量中元素个数
length(c(1,3,5,6,7))
# 计算字符串的长度
nchar("abcdef")
判断重复/独特的函数
x <- c(20,40,60,60,80,100,20)
# 去重复,留下向量中独特的元素
unique(x)
# 判断元素值是否重复,第一次出现均为FALSE
duplicated(x)
# 重复次数统计
table(x)
判断是否等同的函数
# identical()不仅要求两个向量的内容一致,而且要求两个向量的里面元素的顺序是一致的
identical(c(2,4),c(4,2))
identical(c(2,4),c(2,4))
排序函数
x <- c(200,600,800,400,100)
# 返回排序后的向量
sort(x,decreasing = F)
# 返回排序需要的索引
id <- order(x,decreasing = F)
x[id]
# 返回在所有数值中的排名(从小到大)
rank(x)
匹配函数
x <- c(1,2,3,4,5)
y <- c(4,5,6,7,8,9)
# 判断x的元素,是否能匹配上y的任意一个元素
x%in%y
# 判断x的元素匹配上了y的第几个元素
match(x,y)
# 判断x中满足条件的元素对应的坐标
which(x>3)
集合函数
x <- c(1,2,3,4,5,6)
y <- c(4,5,6,7,8,9)
# 求交集
intersect(x,y)
# 求并集
union(x,y)
# 求差集
setdiff(x,y)
setdiff(y,x)
常用统计函数
| 函数 | 举例 | 描述 |
|---|---|---|
| mean(x) | mean(c(1,5,10,15)) | 平均数 |
| median(x) | median(c(1,5,10,15)) | 中位数 |
| sd(x) | sd(c(1,5,10,15)) | 标准差 |
| var(x) | var(c(1,5,10,15)) | 方差 |
| range(x) | range(c(1,5,10,15)) | 求值域 |
| sum(x) | sum(c(1,5,10,15)) | 求和 |
| min(x) | min(c(1,5,10,15)) | 求最小值 |
| max(x) | max(c(1,5,10,15)) | 求最大值 |
| abs(x) | abs(c(-2,3,-4,5)) | 绝对值 |
| sqrt(x) | sqrt(c(1,5,10,15)) | 平方根 |
| log(x) | log(c(1,5,10,15)) | 求对数 |
| quantile(x,probs) | quantile(x=1:100,probs=c(0,0.5,0.8,1)) | 求分位数,其中probs可以是向量 |
数据框基础
数据框是一种二维的数据结构,行表示观测/记录,列表示变量/指标/字段。数据框不同列的数据类型可以不同,但同一列的数据类型要相同,所有列的长度要相同。
数据框创建
ID <- 1:6
grade <- c(1,2,4,3,6,5)
subject <- c("Math","English","Chinese","History","Biology","Chemistry")
score <- c(90,95,92,88,97,91)
df <- data.frame(ID,grade,subject,score)
数据框索引、修改
# 位置方式
df[1,3]
df[,c(1,3)]
df[1:3,2]
# $方式
df$subject
# 名称方式
df[,'subject']
# 交互式修改
df2=edit(df) # edit不改变原始数据
fix(df) # fix改变原始数据
数据框添加、删除变量
# 加载R包中数据集
data("iris")
# 添加变量
iris2 <- transform(iris,variable=Petal.Length*Petal.Width)
# 删除变量
iris2[,-6]
iris2$Species <- NULL
数据框去重复
# 保留每种花的第一个记录
iris3 <- iris[!duplicated(iris$Species),]
数据框排序
# 行按照花萼长度从小到大的次序排
iris2 <- iris[order(iris$Sepal.Length,decreasing = F),]
常用函数
names(iris2)
colnames(iris2)
rownames(iris2)
dim(iris2)
nrow(iris2)
ncol(iris2)
# 查看前几行
head(iris2)
# 查看后几行
tail(iris2)
# 探索数据框结构
str(iris2)
summary(iris2)
# 求和、求平均
colMeans(iris2[,1:4])
colSums(iris2[,1:4])
# 转置
iris3 <- t(iris2)
缺失值
R中缺失值用符号NA(Not Available)表示,缺失值和空字符串的意义不同。
table(is.na(iris2))
# 缺失值
iris2[1,1] <- NA
# 空字符串
iris2[2,1] <- ""
# 移除所有含有缺失值的观测
iris2 <- na.omit(iris2)数据框取子集
data(iris)
iris_sub1 <- iris[iris$Species=='setosa', c('Sepal.Length','Petal.Length')]
# subset()函数
iris_sub2 <- subset(iris, iris$Species=='setosa',select = 1:3)
iris_sub2 <- subset(iris, iris$Species=='setosa',select = c(Sepal.Length,Petal.Length))
# 随机抽样
SampleRow <- sample(1:nrow(iris),size=5,replace=F)
iris[SampleRow,]
数据框合并
横向合并:列合并,确保两个数据框行的次序相同。
纵向合并:行合并,确保两个数据框具有相同的变量。
公共变量合并:可以是一个变量或者多个变量。
df <- data.frame(ID=1:150,
color=rep(c('red','green','blue'),times=50),
length=rep(c('high','middle','low'),times=50))
# 横向合并
newdf <- cbind(iris,df)
# 纵向合并
df2 <- data.frame(ID=151:180,
color=rep(c('red','green','blue'),times=10),
length=rep(c('high','middle','low'),times=10))
df3 <- rbind(df2,df[1:100,])
# 按照共有变量合并
iris$ID <- 150:1
df2 <- df[1:100,]
newdfI <- merge(iris,df3,by='ID') # 取相交
newdfL <- merge(iris,df3,by='ID',all.x=T) #左连接
newdfR <- merge(iris,df3,by='ID',all.y=T) #右连接
数据整合
数据整合:将多组观测替换为由这些观测计算出的描述性统计量。
#FUN参数除了常见的描述统计量之外之外,也可以自定义函数。
aggregate(newdf[,1:4],by=list(newdf$Species),FUN = mean)
aggregate(newdf[,1:4],by=list(newdf$Species,newdf$color),FUN = mean)数据重构(长宽格式转换)
理论
数据重构:通过修改数据的行和列来改变数据的结构。
长格式:相对于宽格式而言,观测更多,变量更少(<=)。
宽格式:相对于长格式而言,观测更少,变量更多(>=)。
宽变长:减少分类变量个数,形成更多观测。
长变宽:增加分类变量个数,以减少观测个数。
数据准备
# reshap2包
install.packages('reshape2')
library(reshape2)
#构建数据框
Id <- as.character(c(1,1,2,2))
Grade<-as.character(c(1,2,1,2))
Math <- c(60,70,80,90)
History <- c(65,75,85,95)
data <- data.frame(Id,Grade,Math,History)
宽变长
# 宽变长
longdata <- melt(data,ID=c("Id","Grade"),variable.name = "Subject")
长变宽
# 长变宽
# 把Subject拆分形成新变量,新变量个数等于Subject独特值数
dcast(longdata,Id+Grade~Subject)
# 把Grade拆分形成新变量,新变量个数等于Grade独特值数
dcast(longdata,Id+Subject~Grade)
# 把Subject+Grade拆分形成新变量,新变量个数等于Subject+Grade独特值数
dcast(longdata,Id~Subject+Grade)
长格式和宽格式不是绝对的。
数据重构整合
数据重构并整合,类似于aggregate()函数的整合功能,但是更加灵活。
# 整合
# 某人某科目 不同学期成绩均值
dcast(longdata,Id~Subject,mean)
# 某学期某科目 不同学生成绩均值
dcast(longdata,Grade~Subject,mean)
# 某学生某学期 不同科目成绩均值
dcast(longdata,Id~Grade,mean)apply族函数
R语言中的apply族函数是重要的批量处理函数,其中常用的函数有apply、tapply、lapply、sapply、mapply。这些函数底层通过C实现,效率比手工遍历高效。apply族函数通过运算向量化(Vectorization)实现高效能运算,比起传统的for、while函数常常能获得更好的性能。
apply函数
apply : 对矩阵、数据框、数组(二维、多维)等矩阵型数据,按行或列应用函数FUN进行循环计算,并以返回计算结果。
apply(X, MARGIN, FUN, …)
-
X:数组、矩阵、数据框等矩阵型数据
-
MARGIN:按行计算或按列计算,1表示按行,2表示按列
-
FUN:自定义的调用函数,如mean/sum等(其结果与colMeans,colSums,rowMeans,rowSums是一样的)
> mat=matrix(c(1,2,3,4,5,6),2)
> mat
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> apply(mat,2,max)
[1] 2 4 6
tapply函数
tapply: 将数据按照不同方式分组,生成类似列联表形式的数据结果。
tapply(X, INDEX, FUN = NULL, …, default = NA, simplify = TRUE)
X:数组、矩阵、数据框等分割型数据向量
-
INDEX:一个或多个因子的列表(因子列表),每个因子的长度都与x相同
-
FUN: 自定义的调用函数
-
simplify指是否简化输出结果(类比sapply对于lapply的简化)
> manager <- c(1, 2, 3, 4, 5)
> country <- c("US", "US", "UK", "UK", "UK")
> gender <- c("M", "F", "F", "M", "F")
> age <- c(32, 45, 25, 39, 99)
> leadership <- data.frame(manager, country, gender, age)
> #求在不同country水平下的age的均值
> tapply(leadership$age, leadership$country, mean)
UK US
54.33333 38.50000
> #求在不同country和gender交叉水平下的age的均值, 输出得到矩阵数据
> tapply(leadership$age, list(leadership$country, leadership$gender), mean)
F M
UK 62 39
US 45 32
lapply函数
lapply : 对列表、数据框按列进行循环,输入必须为列表(list),返回值为列表(list)。
lapply(X, FUN, …)
-
X:列表、数据框
-
FUN:自定义的调用函数
> # 输入为列表
> data1<-list(x = 1:10, y = matrix(1:12, 3, 4))
> data1
$x
[1] 1 2 3 4 5 6 7 8 9 10
$y
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> lapply(data1, sum)
$x
[1] 55
$y
[1] 78
> # 输入为数据框
> data2=data.frame(matrix(1:12,c(3,4)))
> data2
X1 X2 X3 X4
1 1 4 7 10
2 2 5 8 11
3 3 6 9 12
> lapply(data2, function(x) x+3)
$X1
[1] 4 5 6
$X2
[1] 7 8 9
$X3
[1] 10 11 12
$X4
[1] 13 14 15
sapply函数
sapply : 类似于lapply函数,但输入为列表(list),返回值为向量。sapply(X, FUN, …,simplify )
-
X:列表、矩阵、数据框
-
FUN:自定义的调用函数
-
simplify=F:返回值的类型是list,此时与lapply完全相同
-
simplify=T(默认值):返回值的类型由计算结果定,如果函数返回值长度为1,则sapply将list简化为vector;如果返回的列表中每个元素的长度都大于1且长度相同,那么sapply将其简化为一个矩阵;如果列表中的元素长度不相同时,仍以列表形式返回。
> # 输入为列表
> data1<-list(x = 1:10, y = matrix(1:12, 3, 4))
> data1
$x
[1] 1 2 3 4 5 6 7 8 9 10
$y
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> sapply(data1, sum)
x y
55 78
> sapply(data1, function(x) x+1)
$x
[1] 2 3 4 5 6 7 8 9 10 11
$y
[,1] [,2] [,3] [,4]
[1,] 2 5 8 11
[2,] 3 6 9 12
[3,] 4 7 10 13
>
> # 输入为数据框
> data2=data.frame(matrix(1:12,c(3,4)))
> data2
X1 X2 X3 X4
1 1 4 7 10
2 2 5 8 11
3 3 6 9 12
> sapply(data2, function(x) x+3)
X1 X2 X3 X4
[1,] 4 7 10 13
[2,] 5 8 11 14
[3,] 6 9 12 15
mapply函数
mapply: 支持传入两个以上的列表,mapply是sapply的多变量版本(multivariate sapply)。
mapply(FUN, …, MoreArgs = NULL, SIMPLIFY = TRUE, USE.NAMES = TRUE)
-
FUN:要应用的函数
-
...:要传递给FUN的参数列表。可以是多个参数,每个参数列表都是以逗号分隔的
-
SIMPLIFY:一个逻辑值,指定是否尝试简化结果
> a <- mapply(function(x,y) x^y, c(1:5), c(1:5))
> a
[1] 1 4 27 256 3125
> b <- matrix(1:12,c(3,4),dimnames=list(c("a","b","c"),c("A","B","C","D")))
> b
A B C D
a 1 4 7 10
b 2 5 8 11
c 3 6 9 12
> mapply(sum, b[,1],b[,3],b[,4])
a b c
18 21 24
> mapply(sum,b[1,],b[2,],b[3,])
A B C D
6 15 24 33
总结
apply对数据按行列操作
lapply、sapply对数据按列进行批量操作
tapply对数据按分组进行操作
mapply对多个输入数据,即多变量进行批量操作,是sapply的多变量版本
因子:函数factor()
-
变量可归结为名义型、有序型(好,很好,非常好)或连续型变量
-
类别(名义型)变量和有序类别(有序型)变量在R中称为因子(factor)
-
要表示有序型变量,需要为函数factor()指定参数ordered=TRUE
-
数值型变量可以用levels和labels参数来编码成因子
代码如下:
#因子的使用
A<- c(1, 2, 3, 4)
B <- c(25, 34, 28, 52)
C <- c("Type1", "Type2", "Type1", "Type1")
D <- c("Poor", "Improved", "Excellent", "Poor")
C<- factor(C)
D <- factor(D, order = TRUE)#表示有序型变量
mydata <- data.frame(A,B,C,D)#将其合并为数据框
str(mydata)#提供R中某个对象的信息
summary(mydata)#显示统计对象的统计概要
数组:可通过array()函数创建
代码如下:
#创建2*3*4三维数组
data1 <- c("A1", "A2")
data2 <- c("B1", "B2", "B3")
data3 <- c("C1", "C2", "C3", "C4")
z <- array(1:24, c(2, 3, 4), dimnames = list(data1,
data2, data3))
z
列表:使用函数list()创建
-
R的数据类型中最为复杂的一种
-
某个列表中可能是若干向量、矩阵、数据框
-
甚至其他列表的组合
代码如下:
#用levels和labels参数来编码成因子
sex<-c(1,2)
sex
sex<-factor(sex,levels = c(1,2),labels = c("male","female"))
sex
#创建列表
g <- "My First List"
h <- c(25, 26, 18, 39)
j <- matrix(1:10, nrow = 5)
k <- c("one", "two", "three")
mylist <- list(title = g, ages = h, j, k)
mylist
描述性统计分析
summary()函数: summary(mydata)
-
提供最小值、最大值、四分位数和数值型变量的均值
-
因子向量和逻辑型向量的频数统计
apply()函数:apply(mydata,1,mean)
-
1表示行,2表示列
-
注:MARGIN1和2是必须要有的参数,没有就会报错
sapply(x, FUN, options)
-
FUN为一个任意的函数
-
可以在这里插入的典型函数有mean()、sd()、var()、min()、max()、median()、length()、range()和quantile()
-
需要用到function 函数
Hmisc包中的describe()函数
-
变量和观测的数量、缺失值和唯一值的数目、平均值、分位数
-
五个最大的值和五个最小的值
pastecs包中的stat.desc()函数
-
格式为:stat.desc(x, basic=TRUE, desc=TRUE,norm=FALSE, p=0.95)
-
若basic=TRUE(默认值),则计算其中所有值、空值、缺失值的数量,以及最小值、最大值、值域,还有总和
-
若desc=TRUE(同样也是默认值),则计算中位数、平均数、平均数的标准误、平均数置信度为95%的置信区间、方差、标准差以及变异系数
-
若norm=TRUE(不是默认的),则返回正态分布统计量,包括偏度和峰度(以及它们的统计显著程度)和Shapiro-Wilk正态检验结果
-
这里使用了p值来计算平均数的置信区间(默认置信度为0.95)
psych包也拥有一个名为describe()的函数
-
可以计算非缺失值的数量、平均数、标准差、中位数、截尾均值、绝对中位差、最小值、最大值、值域、偏度、峰度和平均值的标准误
使用aggregate()分组获取描述性统计量
-
格式:aggregate(mydata,by=list(name1=mydata$A, mean)
-
如果有多个分组变量,可以使用by=list(name1=groupvar1,name2=groupvar2, ... , nameN=groupvarN)这样的语句
-
缺点:无法一次计算若干个统计量(mean,sd)
使用by()分组计算描述性统计量(同时计算多个统计量)
-
注意:用到了function()函数
分组计算的扩展summaryBy()函数
-
doBy包中summaryBy()函数的使用格式为:
summaryBy(formula, data=dataframe, FUN=function)
-
注意:用到了function()函数
代码如下
#summary()函数
vars <- c("mpg", "hp", "wt")
head(mtcars[vars])
summary(mtcars[vars])
#apply()函数
apply(mtcars,1,mean)#1表示行,2表示列
#sapply()函数
mystats <- function(x, na.omit = FALSE) {
if (na.omit)
x <- x[!is.na(x)]
m <- mean(x)
n <- length(x)
s <- sd(x)
skew <- sum((x - m)^3/s^3)/n
kurt <- sum((x - m)^4/s^4)/n - 3
return(c(n = n, mean = m, stdev = s, skew = skew, kurtosis = kurt))
}
sapply(mtcars[vars], mystats)
#Hmisc包中的describe()函数
library(Hmisc)
describe(mtcars[vars])
#pastecs包中的stat.desc()函数
library(pastecs)
stat.desc(mtcars[vars])
#psych包也拥有一个名为describe()的函数
library(psych)
describe(mtcars[vars])
#分组描述统计的方法
#使用aggregate()分组获取描述性统计量
aggregate(mtcars[vars], by = list(am = mtcars$am), mean)
aggregate(mtcars[vars], by = list(am = mtcars$am), sd)
#doBy包中summaryBy()函数
install.packages("doBy")
library(doBy)
mystats <- function(x, na.omit = FALSE) {
if (na.omit)
x <- x[!is.na(x)]
m <- mean(x)
n <- length(x)
s <- sd(x)
skew <- sum((x - m)^3/s^3)/n
kurt <- sum((x - m)^4/s^4)/n - 3
return(c(n = n, mean = m, stdev = s, skew = skew, kurtosis = kurt))
}
summaryBy(mpg + hp + wt ~ am, data = mtcars, FUN = mystats)19个全球气候数据图层+数据说明文件
链接:https://pan.baidu.com/s/1wZB9RqAvKMhs3t8OdeEkaA
提取码:1207
图绘制:中国数据+中国省界
链接:https://pan.baidu.com/s/1qtjYmm-XKiuKXviomp0KeQ
提取码:1207
地图绘制:云南边界+四川边界+贵州边界
链接:https://pan.baidu.com/s/1199tThT9QqsTMM-BrDdelg
提取码:1207

![[Collection与数据结构] 二叉树(三):二叉树精选OJ例题(下)](https://img-blog.csdnimg.cn/direct/4f296d76b5234dd18709cd687cfdb8d3.png)



![Redis集合[持续更新]](https://img-blog.csdnimg.cn/img_convert/3e662e81235cf3e798d531d15fe67c77.png)