文章目录
- 数据库知识介绍
- 数据库系统的ACID特性
- 分布式系统和CAP理论
- 关系型数据库与非关系型数据库
- 关系型数据库
- 非关系型数据库
- OldSQL、NoSQL、NewSQL
- OldSQL
- NoSQL
- NewSQL
- OLTP、OLAP、HTAP
- 前言:为什么选择TiDB学习?
- pingCAP介绍
- TiDB介绍
- TiDB的影响力
- TiDB概括
- 创作背景
- 论文阅读:TiDB: A Raft-based HTAP Database
- 基于Raft的HTAP数据库
- Raft算法
- 问题描述
- RSM模型
- 算法详情
- TiDB
- TiDB架构
- 分布式存储层-Multi-Raft存储
- Placement Driver(PD)
- 计算引擎层
- 优化
- 加速来自客户端的请求
- Regions管理
- 海量region
- 动态区域拆分和合并
- 日志重放
- 列存引擎 Delta Tree
- Segment: B+ Tree
- Levels LSM Tree
- 比较
- 分析处理
- 实验
- OLPA能力
- OLAP
- HTAP
- 总结
TiDB: A Raft-based HTAP Database
Dongxu Huang, Qi Liu, Qiu Cui, Zhuhe Fang∗ , Xiaoyu Ma, Fei Xu, Li Shen, Liu Tang, Yuxing Zhou, Menglong Huang, Wan Wei, Cong Liu, Jian Zhang, Jianjun Li, Xuelian Wu, Lingyu Song, Ruoxi Sun, Shuaipeng Yu, Lei Zhao, Nicholas Cameron, Liquan Pei, Xin Tang
PingCAP
https://dl.acm.org/doi/pdf/10.14778/3415478.3415535

TiDB是一个基于Raft的HTAP数据库。数据库中,设计了由行存储和列存储组成的 Multi-Raft 存储系统。行存储是基于Raft算法构建的。它异步复制Raft日志到 learners,learners将元组的行格式转换为列格式,形成一个实时可更新的列存储。系统构建了一个SQL引擎来处理大规模分布式事务和昂贵的分析查询。SQL引擎可以最优地访问行格式和列格式的数据副本。系统还包含了一个强大的分析引擎TiSpark,帮助TiDB连接到Hadoop生态系统。
数据库知识介绍
数据库系统的ACID特性
ACID,是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。

- A:Atomicity – 原子性
一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有被执行过一样。 - C:Consistency – 一致性
在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。 - I:Isolation – 隔离性
数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。 - D:Durability – 持久性
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
关系型数据库严格遵循ACID理论。但当数据库要开始满足横向扩展、高可用、模式自由等需求时,需要对ACID理论进行取舍,不能严格遵循ACID。以CAP理论和BASE理论为基础的NoSQL数据库开始出现。
https://www.sohu.com/a/191132281_197042
分布式系统和CAP理论
分布式系统的核心理念是让多台服务器协同工作,完成单台服务器无法处理的任务,尤其是高并发或者大数据量的任务。分布式系统最大的特点是可扩展性,它能够适应需求变化而扩展。企业级应用需求经常随时间而不断变化,这也对企业级应用平台提出了很高的要求。
如果我们期待实现一套严格满足ACID的分布式事务,很可能出现的情况就是系统的可用性和严格一致性发生冲突。在可用性和一致性之间永远无法存在一个两全其美的方案。对于支持分布式存储的系统,严格一致性与可用性需要互相取舍,由此延伸出了CAP理论来定义分布式存储遇到的问题。
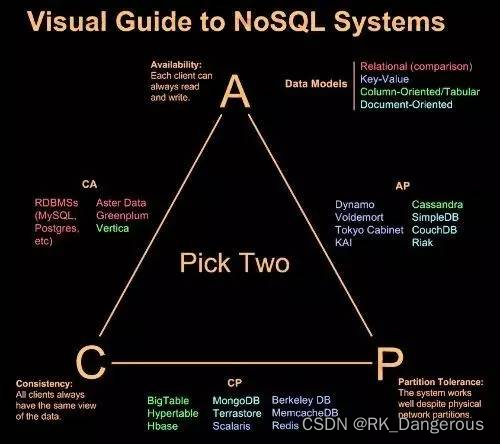
CAP理论指出:一个分布式系统不可能同时满足一致性(C:Consistency)、可用性(A:Availability)、分区容错性(P:Partitiontolerance)这三个基本需求,并且最多只能满足其中的两项。
-
C(Consistency)一致性
一致性是指“all nodes see the same data at the same time”,更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。 -
A – Availability – 可用性
可用性是指“Reads and writes always succeed”,即服务一直可用,而且是正常响应时间。对于一个可用性的分布式系统,每一个非故障的节点必须对每一个请求作出响应。好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。在通常情况下,可用性与分布式数据冗余、负载均衡等有着很大的关联。 -
P(Partition tolerance)分区容错性
分区容错性是指“the system continues to operate despite arbitrary message loss or failureof part of the system”,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
分区容错性和扩展性紧密相关。在分布式应用中,可能因为一些分布式的原因导致系统无法正常运转。好的分区容错性要求能够使应用虽然是一个分布式系统,但看上去却好像是一个可以运转正常的整体。比如现在的分布式系统中有某一个或者几个机器宕掉了,其它剩下的机器还能够正常运转满足系统需求,或者是机器之间有网络异常,将分布式系统分隔成未独立的几个部分,各个部分还能维持分布式系统的运作,这样就具有好的分区容错性。 -
CA without P
如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但其实分区不是你想不想的问题,而是始终会存在,因此CA的系统更多的是允许分区后各子系统依然保持CA。 -
CP without A
如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。 -
AP without C
要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
https://mp.weixin.qq.com
https://www.sohu.com/a/191132281_197042
关系型数据库与非关系型数据库
关系型数据库
关系型数据库是一个结构化的数据库,采用了关系模型来组织数据的数据库。关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
结构化数据指的是由二维表结构来逻辑表达和实现的数据,严格遵循数据格式与长度规范,也称作为行数据,特点为:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。
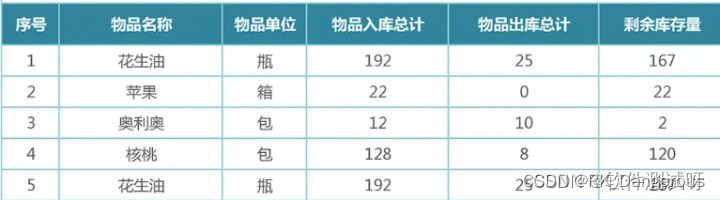
优点:
- 容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解
- 使用方便:通用的 SQL 语言使得操作关系型数据库非常方便
- 易于维护:丰富的完整性 (实体完整性、参照完整性和用户定义的完整性) 大大减低了数据冗余和数据不一致的概率
- 数据稳定:数据持久化到磁盘,没有丢失数据风险
不足:
- 网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
- 网站每天产生的数据量是巨大的,对于关系型数据库来说,在一张包含海量数据的表中查询,效率是非常低的。
- 在基于 web 的结构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。当需要对数据库系统进行升级和扩展时,往往需要停机维护和数据迁移。
- 性能欠佳:在关系型数据库中,导致性能欠佳的最主要原因是多表的关联查询,以及复杂的数据分析类型的复杂 SQL 报表查询。为了保证数据库的 ACID 特性,必须尽量按照其要求的范式进行设计,关系型数据库中的表都是存储一个格式化的数据结构。
非关系型数据库
非关系型数据库指非关系型的,分布式的,且一般不保证遵循ACID原则的数据存储系统。非关系型数据库以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,不局限于固定的结构,可以减少一些时间和空间的开销。非关系型数据库可分为文档型、key-value型、列式数据库、图形数据库。它严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。
优点:
- 用户可以根据需要去添加自己需要的字段,为了获取用户的不同信息,不像关系型数据库中,要对多表进行关联查询。仅需要根据id取出相应的value就可以完成查询。
- 适用于SNS(Social Networking Services)中,例如 facebook,微博。系统的升级,功能的增加,往往意味着数据结构巨大变动,这一点关系型数据库难以应付,需要新的结构化数据存储。由于不可能用一种数据结构化存储应付所有的新的需求,因此,非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
不足:
- 只适合存储一些较为简单的数据,对于需要进行较复杂查询的数据,关系型数据库显得更为合适。
- 不适合持久存储海量数据。
https://mp.weixin.qq.com
https://blog.csdn.net/weixin_57794111/article/details/125697630
https://blog.csdn.net/weixin_27009347/article/details/113598397
OldSQL、NoSQL、NewSQL
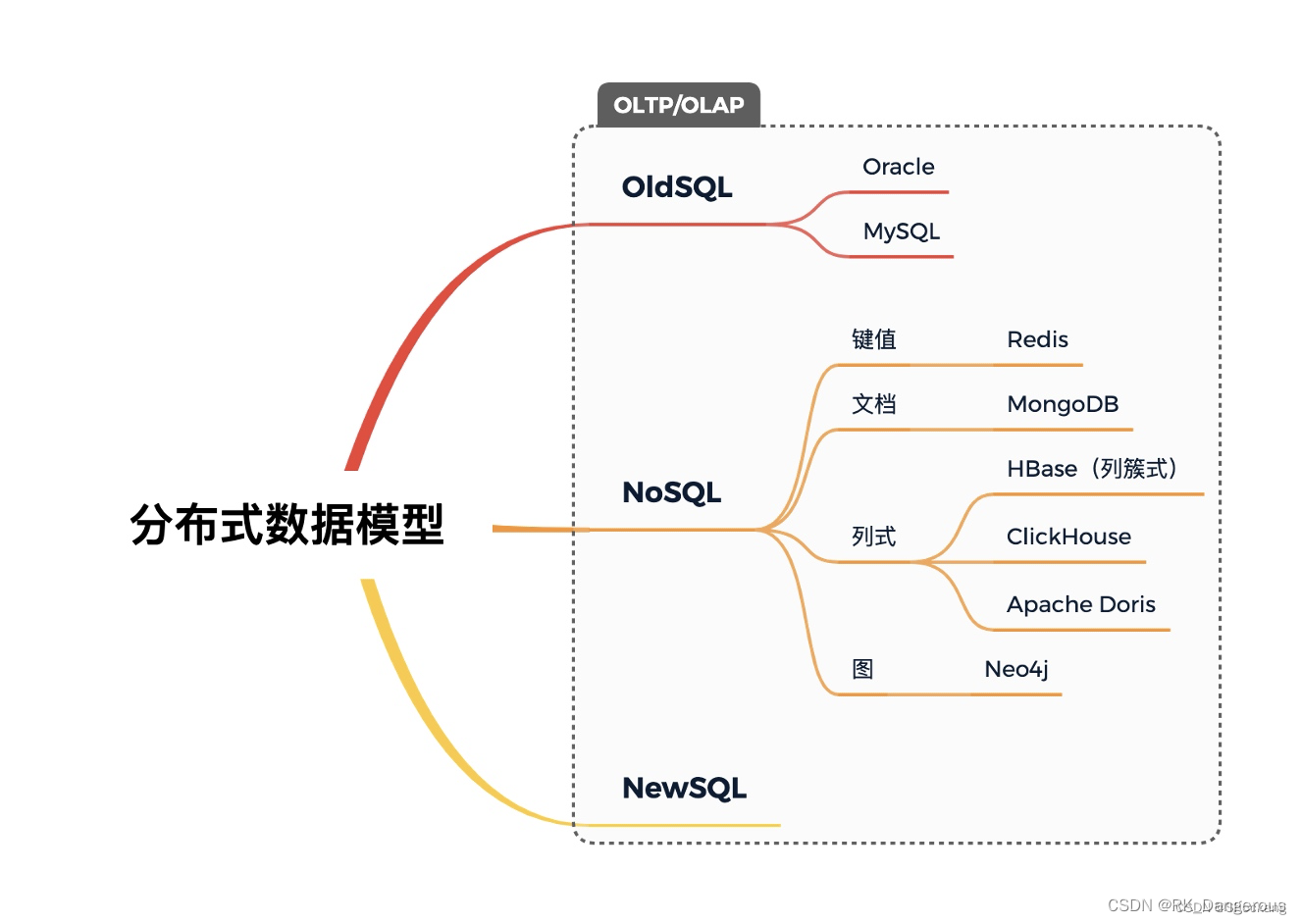
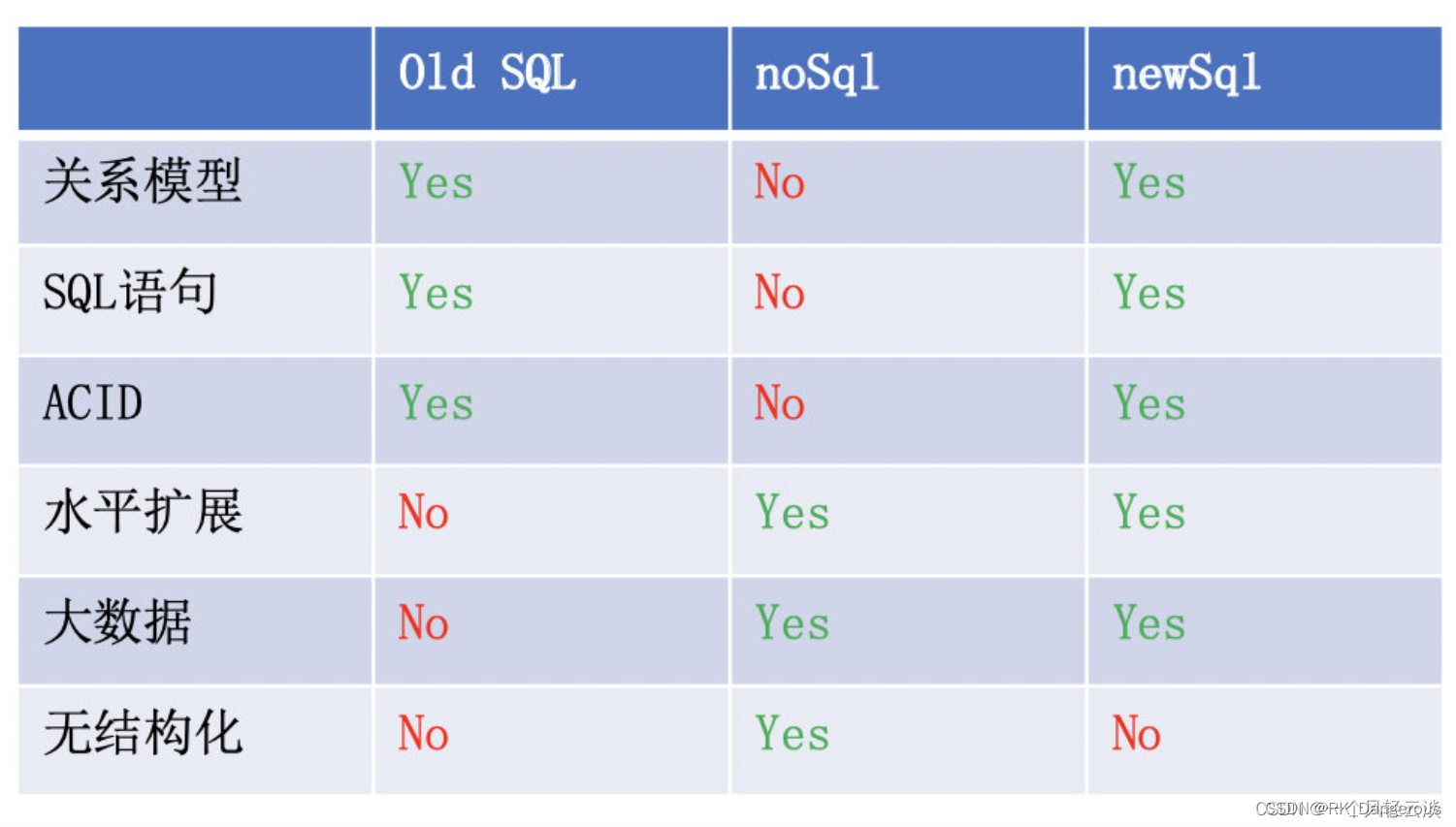
OldSQL
OldSQL 通常是在与 NoSQL 数据库相对比时使用的术语,用于指代传统的 SQL(结构化查询语言)数据库。传统的 SQL 数据库是基于关系模型的数据库,它使用表格和预定义模式来存储和管理数据。传统的 SQL 数据库具有强大的事务支持、复杂查询能力和丰富的数据完整性约束。
NoSQL
NoSQL是 Non-relational SQL或者Not Only SQL的英文简写,泛指非关系型的数据库,是不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL 数据库采用非关系模型,不使用固定的表格和预定义模式。NoSQL 数据库更灵活,适用于大规模的分布式数据存储和处理,并且在一些应用场景下表现出更好的性能和扩展性。
NewSQL
NewSQL一词是由451 Group的分析师Matthew Aslett在研究论文中提出的。它代指对老牌数据库厂商做出挑战的一类新型数据库系统。
NewSQL 是对各种新的可扩展/高性能数据库的简称,是指这样一类新式的关系型数据库管理系统,针对OLTP(读-写)工作负载,这类数据库不仅具有NoSQL对海量数据的存储管理能力,还保持了传统数据库支持ACID和SQL等特性。
https://blog.csdn.net/Shockang/article/details/131437186
https://blog.csdn.net/Shockang/article/details/115987223
https://baike.baidu.com/item/NewSQL/9529614?fr=ge_ala
https://blog.csdn.net/m0_62436868/article
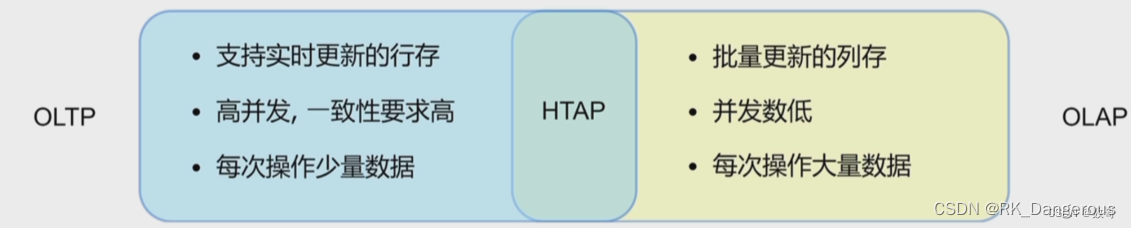
OLTP、OLAP、HTAP
-
OLTP
OLTP(On-line Transaction Processing,联机事务处理),也可以称面向交易的处理系统。它是传统关系型数据库的主要应用,是针对具体业务在数据库联机的日常操作,其主要面向基本的、日常的事务处理,如银行交易,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。
传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。 -
OLAP
OLAP(On-Line Analytical Processing,联机分析处理),一般针对某些主题的历史数据进行分析,支持管理決策。是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
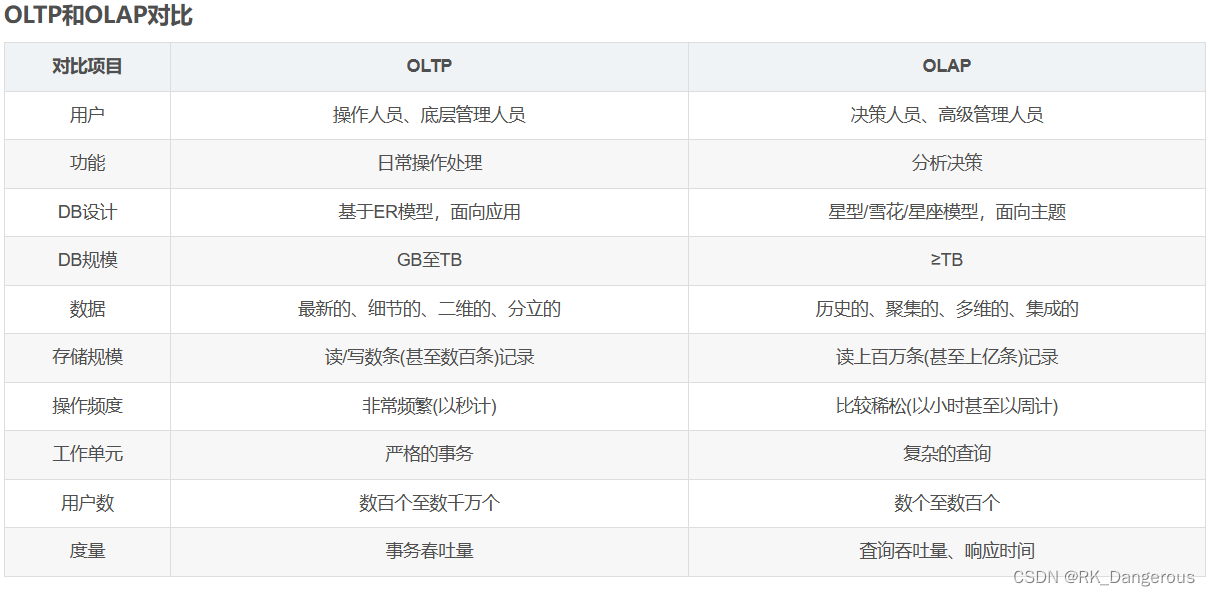
传统的数据管理企业为了同时支持两类业务,通常采用两个数据源,分别对两套系统进行优化设计。
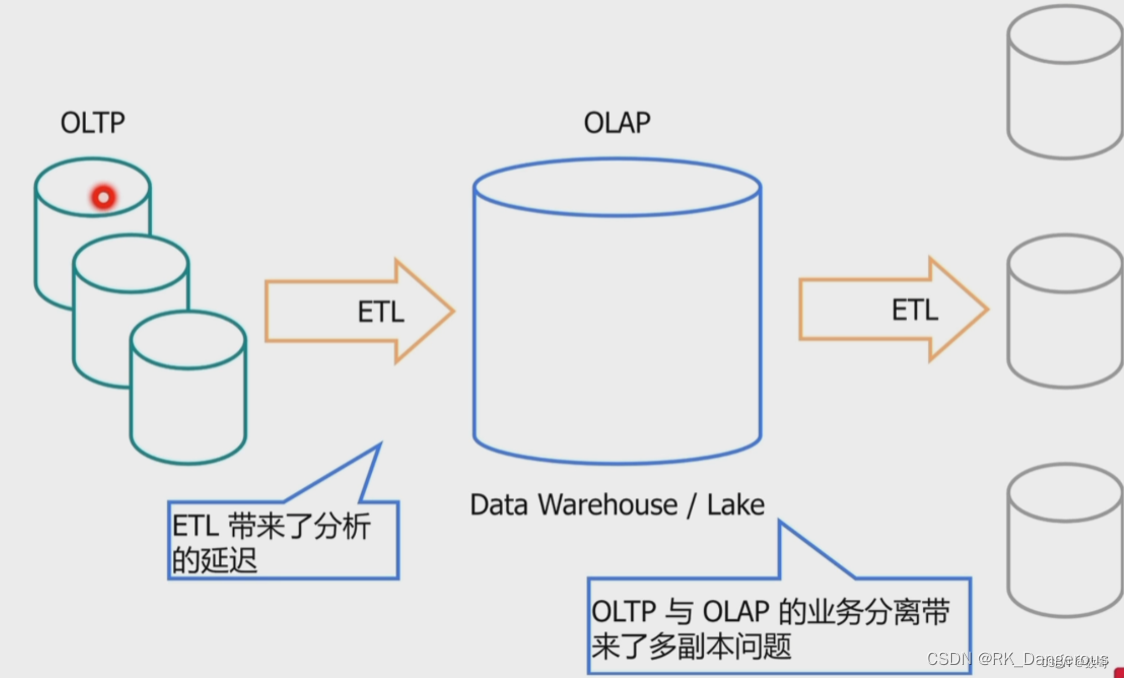
OLTP的数据定期会通过ETL工具把数据同步导入OLAP系统中,这就涉及到数据源滞后的问题。OLAP的数据滞后,导致分析出来的结果时效性不够,对决策支持类系统的要求不够。比如双11期间,用户购物的行为和推荐系统的推荐结果之间的时间差越短,越有可能提高销量。
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
ETL是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。
https://baike.baidu.com/item/ETL/1251949?fr=ge_ala
https://www.fanruan.com/bw/etl


HTAP是混合OLTP和OLAP业务同时处理的系统,2014年Garnter公司给出了严格的定义:混合事务/分析处理(HTAP)是一种新兴的应用体系结构,它打破了事务处理和分析之间的“墙”。它支持更多的信息和“实时业务”的决策。
https://blog.csdn.net/Shockang/article/details/115816568
https://blog.csdn.net/wangzhicheng987/article/details/131031835
https://blog.51cto.com/u_15060464/2650177
https://blog.csdn.net/Shockang/article/details/131437186
前言:为什么选择TiDB学习?
pingCAP介绍
数据库厂商pingCAP是分布式 HTAP 数据库 TiDB 的背后团队。

PingCAP成立于2015年,是一家企业级开源分布式数据库厂商,提供包括开源分布式数据库产品、解决方案与咨询、技术支持与培训认证服务。其从成立之初就以开源为长期核心战略,坚信开源是基础软件在全球范围取得成功的最优道路,把“开源”这个具有乌托邦色彩的词语化作现实,贯彻执行。PingCAP创立的分布式关系型数据库TiDB服务了上千家企业,成为企业数字化转型的关键引擎。在市场充满挑战的背景下,PingCAP以开源社区为依托,正在打造不分国界的全球产业生态,并将在企业数字化转型中提供更强大的助推力。

PingCAP在2020年中国独角兽企业排行榜位于113名,2022年8月入选福布斯中国发布的2022中国创新力企业50强榜单。开源项目包括 TiDB、TiKV、Chaos Mesh 等,截至 2020 年底,公司在 CNCF(Cloud Native Computing Foundation,云原生计算基金会) 全球贡献榜中连续两年保持第六位,在中国企业中贡献排名高居第一。

https://blog.csdn.net/weixin_39666736/article
https://baike.baidu.com/item/PingCAP/60056692?fr=ge_ala
https://cn.pingcap.com/product/
TiDB介绍
TiDB的影响力
大部分在开发应用上使用的是由甲骨文、微软等公司提供的MySQL、SQLserver,普通程序员很少在日常接触国产数据库,也很少能用到newSQl数据库,TiDB就是一种newSQL数据库。

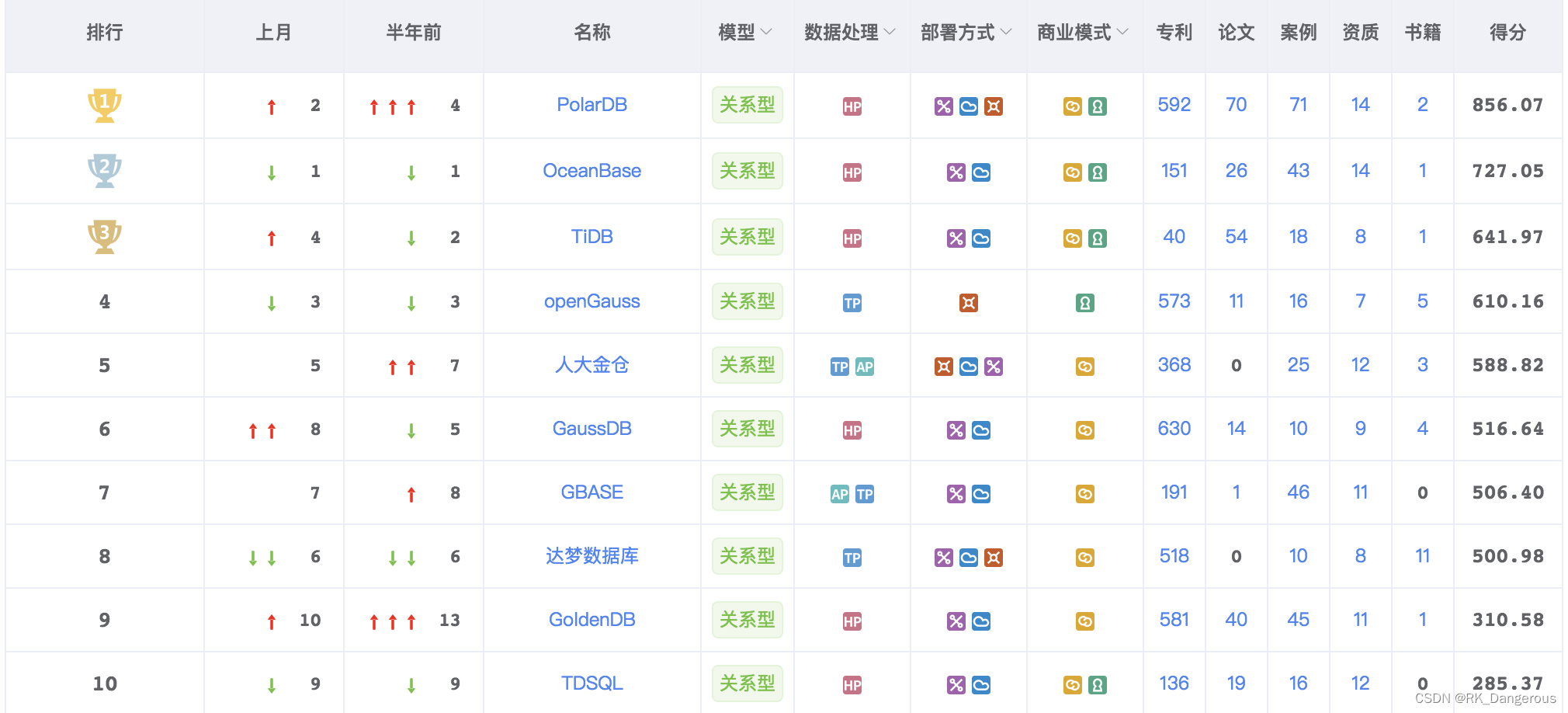
2024年2月墨天轮中国数据库流行度榜单出炉,TiDB以641.97分位列第三展现了其持续的技术进步和市场接受度。基于TiDB技术的杭州银行新一代核心业务系统于1月5日成功上线,标志着业界首次将云原生、分布式和全栈国产化技术应用于银行核心系统的实践。这一突破不仅在金融科技领域引起了广泛关注,也证明了TiDB在处理复杂、高要求的金融业务场景中的强大能力。随着更多企业和开发者的加入,TiDB及其背后的PingCAP正成为全球开源社区的关键力量,推动着开源技术的发展和创新。
TiDB概括
TiDB 是一个分布式 NewSQL 数据库。它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和 MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合 OLTP 场景还适OLAP 场景的混合数据库。
创作背景
开源分布式缓存服务 Codis 的作者,PingCAP 联合创始人& CTO ,资深 infrastructure 工程师的黄东旭,擅长分布式存储系统的设计与实现,开源狂热分子的技术大神级别人物。即使在互联网如此繁荣的今天,在数据库这片边界模糊且不确定地带,他还在努力寻找确定性的实践方向。2012 年底,他看到 Google 发布的两篇论文,得到了很大的触动,这两篇论文描述了 Google 内部使用的一个海量关系型数据库 F1/Spanner ,解决了关系型数据库、弹性扩展以及全球分布的问题,并在生产中大规模使用。“如果这个能实现,对数据存储领域来说将是颠覆性的”,黄东旭为完美方案的出现而兴奋, PingCAP 的 TiDB 在此基础上诞生了。
https://blog.csdn.net/m0_62436868/article
https://zhuanlan.zhihu.com/p/683161447
论文阅读:TiDB: A Raft-based HTAP Database
TiDB是一个基于Raft的HTAP数据库。数据库中,设计了由行存储和列存储组成的 Multi-Raft 存储系统。行存储是基于Raft算法构建的。它异步复制Raft日志到 learners,learners将元组的行格式转换为列格式,形成一个实时可更新的列存储。系统构建了一个SQL引擎来处理大规模分布式事务和昂贵的分析查询。SQL引擎可以最优地访问行格式和列格式的数据副本。系统还包含了一个强大的分析引擎TiSpark,帮助TiDB连接到Hadoop生态系统。
基于Raft的HTAP数据库
本文提出建立一个基于共识算法的HTAP系统,并实现了一个基于Raft的HTAP数据库TiDB。它是一个开源项目,为HTAP工作负载提供高可用性、一致性、可扩展性、数据新鲜度和隔离性。
Raft算法
问题描述
分布式系统中的节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing)。基于消息传递通信模型的分布式系统,不可避免地会发生以下错误:进程可能会慢、垮、重启,消息可能会延迟、丢失、重复(不考虑“Byzantinefailure”)。
在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么它们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个「一致性算法」以保证每个节点看到的指令一致。
RSM模型
Raft算法将这类问题抽象为“ReplicatedState Machine(复制状态机)”,每台Server保存用户命令的日志,供本地状态机顺序执行。即为了保证“Replicated State Machine”的一致性,我们只需要保证“ReplicatedLog”的一致性。
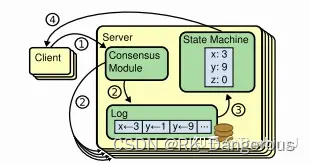
Raft遵守RSM模型 ,它包括几个模块:
- 日志:记录应该做哪些操作。
- 状态机:真正进行读写的物理存储。
- 共识模块:负责使多个节点日志相同。
状态机是什么?
状态机,也称为有限状态机(Finite State Machine, FSM),是一种用于描述系统状态变化的数学模型。
状态机包括状态寄存器和组合逻辑电路,能够根据控制信号按照预先设定的状态进行状态转移,是协调相关信号动作、完成特定操作的控制中心。状态机主要由状态寄存器和转移条件组成,状态寄存器用于保存系统的当前状态,而转移条件则描述了状态转移的条件。通过监测输入信号的变化,状态机可以在不同状态之间进行转移,从而实现对系统行为的控制。
共识模块让所有节点日志相同,每个节点再按照顺序把日志Apply到本地状态机上,每个节点的状态机也最终会相同。
算法详情
Raft算法将Server划分为3种角色:领导者(Leader)、跟从者(Follower)和候选者(Candidate)
- Leader:接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志。
- Follower:接受并持久化Leader同步的日志,在Leader告知日志可以提交之后,提交日志。
- Candidate:Leader选举过程中的临时角色,由Follower向Leader转换的中间状态。
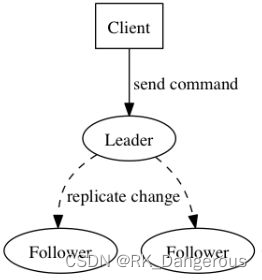
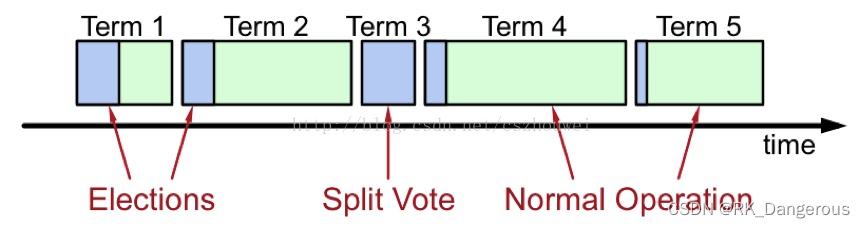
Raft要求系统在任意时刻最多只有一个Leader,正常工作期间只有Leader和Followers。Raft算法将时间分为一个个的任期(term),每一个term的开始都是Leader选举。在成功选举Leader之后,Leader会在整个term内管理整个集群。如果Leader选举失败,该term就会因为没有Leader而结束。 Raft 算法将时间划分成为任意不同长度的任期(term)。任期用连续的数字进行表示。每一个任期的开始都是一次选举(election),一个或多个候选人会试图成为领导人。如果一个候选人赢得了选举,它就会在该任期的剩余时间担任领导人。在某些情况下,选票会被瓜分,有可能没有选出领导人,那么,将会开始另一个任期,并且立刻开始下一次选举。Raft 算法保证在给定的一个任期最多只有一个领导人。
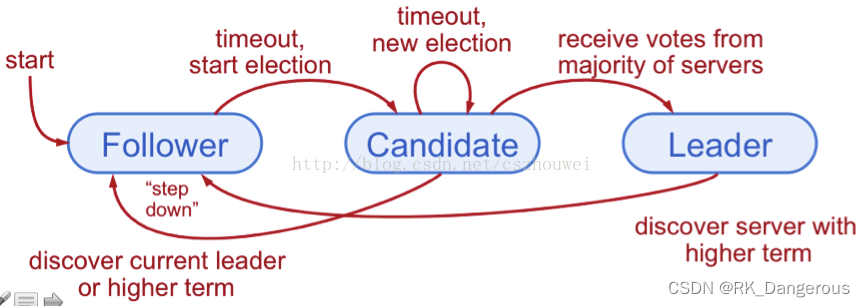
step1:Leader的选举过程
Raft 使用心跳(heartbeat)触发Leader选举。当服务器启动时,初始化为Follower。
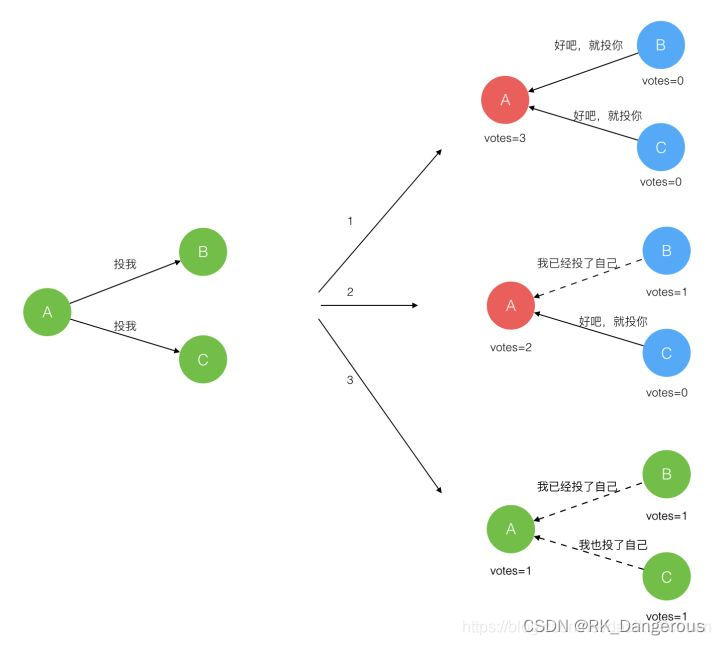
每一个Follower都有一个时钟,是一个随机的值,表示的是Follower等待成为Leader的时间,谁的时钟先跑完,则将其当前term加一然后转换为Candidate,发起Leader选举。
Candidate首先会给自己投票并且向所有其他服务器周期发送RequestVote RPC(远程过程调用),如果Follower在选举超时时间内没有收到Leader的heartbeat,就会等待一段随机的时间后发起一次Leader选举。对于一个Candidate可能有三种情况:
- 赢得了多数的选票,成功选举为Leader;
- 收到了Leader的消息,表示有其它服务器已经抢先当选了Leader;
- 没有服务器赢得多数的选票,Leader选举失败,等待选举时间超时后发起下一次选举。
step2:日志复制
Leader选出后,就开始接收客户端的请求(客户端的每一个请求都包含被复制状态机执行的指令)。Leader把请求作为日志条目(Log entries)加入到它的日志中,然后并行的向其他服务器发起 AppendEntries RPC(远程过程调用)复制日志条目。当这条日志被复制到大多数服务器上,Leader将这条日志应用到它的状态机并向客户端返回执行结果。如果 follower 宕机或者运行缓慢或者丢包,leader会不断的重试,直到所有的 follower 最终都复制了所有的日志条目。
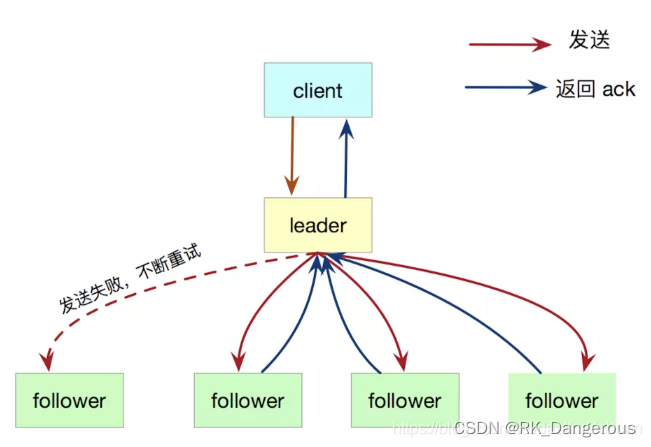
日志由有序编号(log index)的日志条目组成。每个日志条目包含它被创建时的任期号(term)和用于状态机执行的命令。如果一个日志条目被复制到大多数服务器上,就被认为可以提交(commit)了。
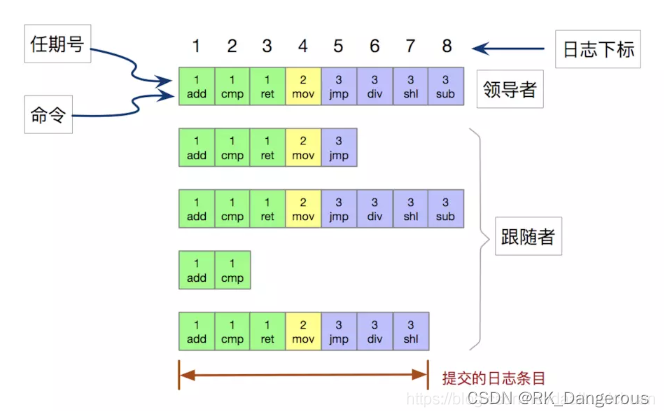
每次 RPC 发送附加日志时,leader 会把这条日志条目的前面的日志的下标和任期号一起发送给 follower,如果 follower 发现和自己的日志不匹配,那么就拒绝接受这条日志,这个称之为一致性检查。
https://zhuanlan.zhihu.com/p/623293317
https://blog.csdn.net/cszhouwei/article/details/38374603
https://cloud.tencent.com/developer/article/2168468
TiDB
文章提出了一个基于Raft的HTAP数据库:TiDB。数据使用行格式存储在多个Raft组中,以服务事务性查询。每个组由一个leader和followers组成。我们为每个组添加了一个专用节点learner角色,以异步复制来自leader的数据。
异步是一种操作模式,指的是在程序的执行过程中,某个任务或操作被发起后,不必等待该操作完成,程序可以继续执行其他任务。
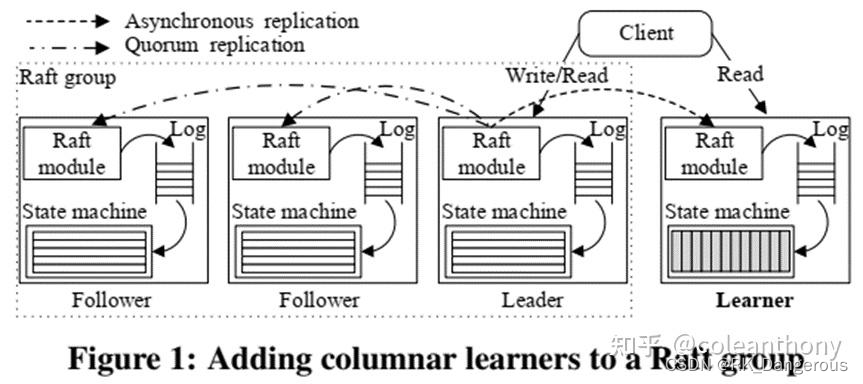
learner将日志中的行格式元组转换为列格式,以便副本更适合于分析查询。
对于如下数据:
行格式存储为:
列格式存储为:
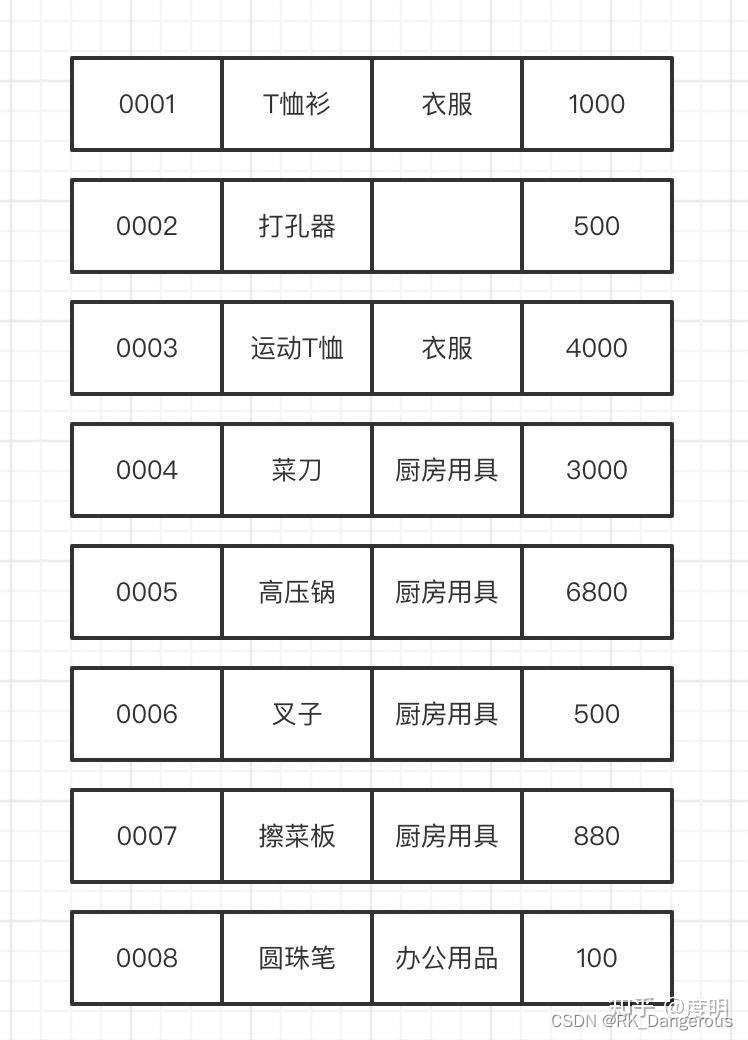
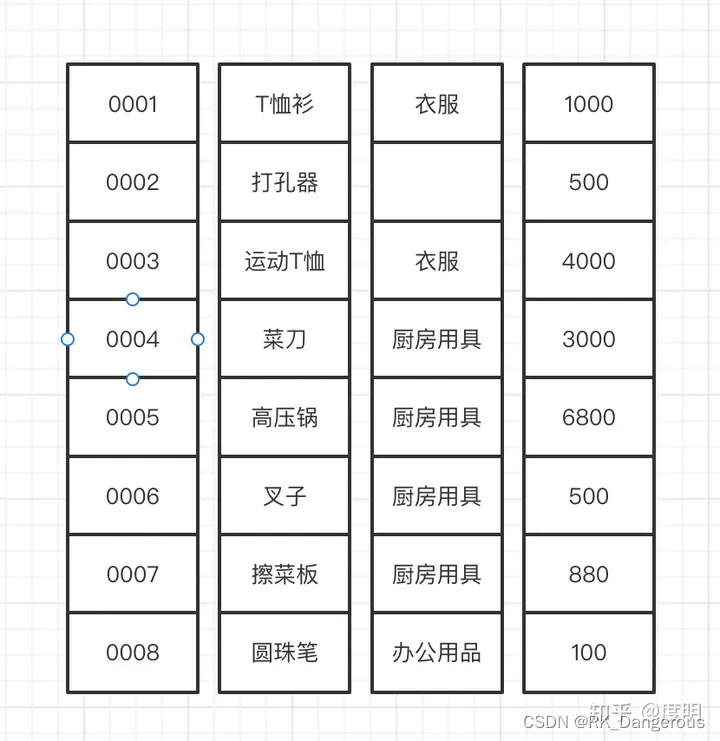
事务性查询需要高效的数据更新,而连接或聚合等分析性查询需要读取列的子集,但这些列需要读取大量行。基于行的格式可以利用索引来有效地服务于事务性查询。基于列的格式可以有效地利用数据压缩和向量化处理。因此,在复制到Raft learner时,数据从基于行的格式转换为基于列的格式。
总结:learner从 leader 节点异步复制事务日志(leader在响应客户端之前不需要等待成功),为OLAP查询构造新的副本。
https://zhuanlan.zhihu.com/p/565760018
TiDB架构
TiDB支持MySQL协议,可以通过与MySQL兼容的客户端访问。它有三个核心组件:分布式存储层、Placement Driver(PD)和计算引擎层。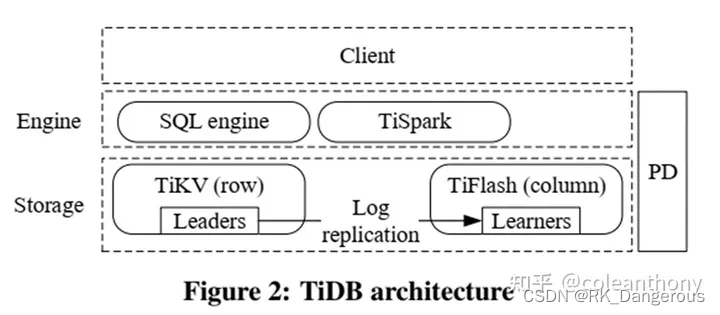
分布式存储层-Multi-Raft存储
分布式存储层由行存储(TiKV)和列存储(TiFlash)组成。逻辑上,存储在TiKV中的数据是一个有序的键值映射。每个元组被映射成一个键值对。键由它的表ID和行ID组成,值是实际的行数据,其中表ID和行ID是唯一的整数,行ID将来自一个主键列。
为了向外扩展,我们采用范围分区策略,将大的键值映射分割成许多连续的范围,每个范围称为一个region。为了获得高可用性,每个region都有多个副本。使用Raft共识算法来维护每个region的副本之间的一致性,形成一个Raft组。不同Raft组的leader将数据从TiKV异步复制到TiFlash。TiKV和TiFlash可以部署在单独的物理资源中,从而在处理事务性查询和分析性查询时提供隔离。
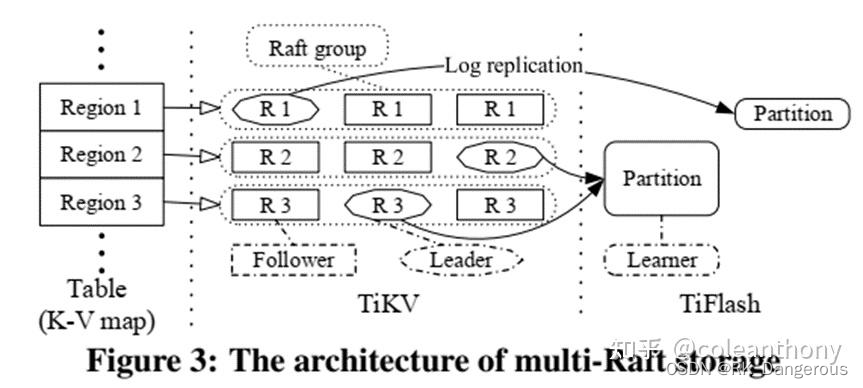
存储层由一个基于行的存储TiKV和一个基于列的存储TiFlash组成。存储层将一个大的表映射成一个大的键值映射,这个键值映射被分割成许多region存储在TiKV中。每个region使用Raft共识算法来保持副本之间的一致性,以实现高可用性。当数据复制到TiFlash时,多个region可以合并成一个分区,方便表扫描。TiKV和TiFlash之间的数据通过异步日志复制保持一致。多个Raft组在分布式存储层管理数据,称之为Multi-Raft存储。
Placement Driver(PD)
PD是 TiDB 里面全局中心总控节点,它负责整个集群的调度,负责全局 ID 的生成,以及全局时间戳 TSO 的生成等。PD 还保存着整个集群 TiKV 的元信息,负责给 client 提供路由功能。PD的架构如图所示:

PD集成了ETCD,其Raft协议保证了数据的一致性。
Etcd(分布式键值存储系统)是CoreOS基于Raft协议开发的分布式key-value存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。
- Store:集群中的存储实例,对应TiKV。
- Region:数据的存储单元,负责维护存储的数据。包含多个副本,每个副本叫一个Peer。读写操作在主节点(leader节点)进行,相关信息通过Raft协议同步到follower节点。leader和follower之间组成一个group,就是raft group。
计算引擎层
计算引擎层是无状态的,并且是可扩展的。SQL引擎有一个基于成本的查询优化器和一个分布式查询执行器。TiDB实现了基于Percolator的两阶段提交(2PC)协议,以支持分布式事务处理。查询优化器可以根据查询优化选择从TiKV和TiFlash读取数据。
Percolator是由谷歌推出的,在海量数据(PB级)上实现增量计算的平台。它使得在已有的结果集上进行小粒度的更新(small updates)更加快速。
- 离线计算,就好比火车(绿皮车),每天发一次,每次能拉 1000 多人,延迟非常大,但每次能处理非常多的数据;
- 实时计算,就好比小汽车(私家车),每次拉的人不多,但满足时效性,想走就能走,但成本相对比较大;
- 增量计算,就好比是高铁(地铁或公交车),10 分钟来一趟,想来不一定能来,想走得去公交车站等车,但一趟车也能拉很多人。

两阶段提交Two-phase Commit(2PC)协议是一种分布式一致性(consistency)协议,常被用于分布式系统中,用于保证各个参与节点数据一致性,即各节点事务一致性,即分布式系统整体事务原子性(atomic)。简单来说,就是分布式系统中的所有参与者,对于请求的事务要不所有参与者都提交,要不所有参与者都回退。
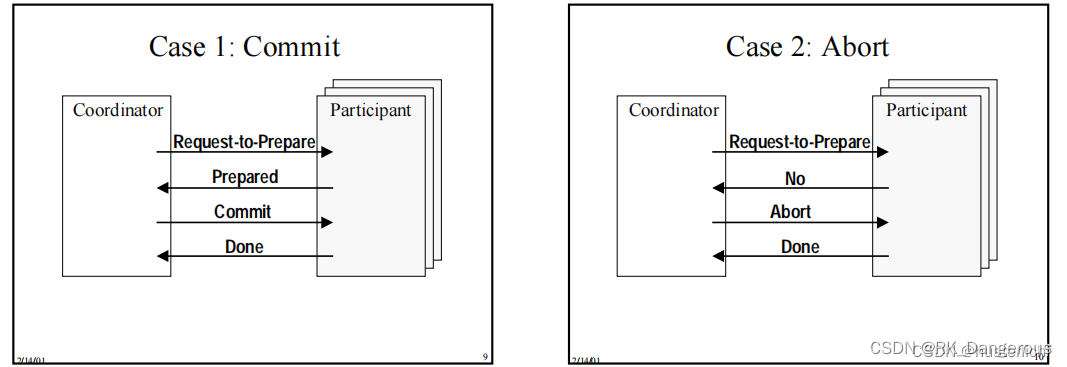
其中,Coordinator是协调事务提交的组件、Participant 可以被事务T访问的资源管理器(resource manager)。
- 阶段一 (phase 1)
1、 coordinator 发送Request-to-Prepare 消息到每一个 participant
2、 coordinator 等待所有participant去投票(vote)
3、每个participant:如果准备好了就会投票(Prepared),也会因为其他原因投票(No)、也许会延迟投票- 阶段二 (phase 2)
1、如果coordinator 收到所有participant的Prepared消息,则会决定去提交该事务;否则会决定终止该事务
2、coordinator 发送他的决定到每一个participant(Commit or Abort)
3、participant通过回复Done来确认收到的Commit 或者Abort
TiDB还集成了Spark,这有助于将存储在TiDB中的数据与Hadoop分布式文件系统(HDFS)进行集成。
Apache Spark是一个开源的、快速通用的计算引擎,专为处理大规模数据而设计。它由加州大学伯克利分校的AMP实验室(Algorithms, Machines, and People Lab)开发,并由Apache软件基金会管理。
计算引擎是一种专门处理数据的程序,它可以是高度抽象聚合体,使用者按照指定的方式编写对应接口代码,然后执行就能得到需要的结果。
Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System)。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
https://blog.csdn.net/weixin_39540280/article/details
https://blog.csdn.net/wux_labs/article/details/128897148
https://zhuanlan.zhihu.com/p/24809131
https://cloud.tencent.com/developer/article/1765944
https://baike.baidu.com/item/Percolator/3772109?fr=ge_ala
https://blog.csdn.net/qq_41768644/article/details/132071823
https://baike.baidu.com/item/hdfs/4836121?fr=ge_ala
https://www.sohu.com/a/763263629_374240
https://zhuanlan.zhihu.com/p/679544882
优化
加速来自客户端的请求
从TiKV leader读取数据提供了线性化的语义。这意味着当在时间t从region leader读取一个值时,leader一定不能返回t时刻之后版本的值。TiKV实现了Raft论文中描述的读取优化。
- 读索引。leader响应读请求时,会将当前提交索引记录为本地读索引,然后向follower发送心跳消息,确认自己的leader角色。如果确实是leader,一旦应用索引大于或等于读索引,它就可以返回该值。这种方法提高了读性能,尽管它会导致一些网络开销。
- 租约读。它减少了由读索引引起的心跳的网络开销。leader和follower商定一个租期,在租期内follower不会发出选举请求,这样leader就不会被改变。在租期内,leader可以响应任何读请求,而不需要连接follower。如果每个节点的CPU时钟相差不大,这种方法就能很好地工作。
另外,除了leader, follower还可以响应来自客户端的读请求,这叫做follower read。
Regions管理
海量region
为了在服务器间平衡 region, PD 对region进行调度,并限制副本的数量和位置。一个关键的约束是在不同的TiKV实例上放置一个region的三个副本(至少),以确保高可用性。PD是通过心跳从服务器收集特定信息来初始化的。它还监控每个服务器的工作负载,并在不影响应用程序的情况下将热点区域迁移到不同的服务器上。
动态区域拆分和合并
为了保持region之间的顺序,我们只合并键空间中相邻的region。PD根据观察到的工作负载,动态地向TiKV发送拆分和合并命令。split操作将一个region划分为几个新的、更小的region,每个region覆盖原始region中连续的键范围。覆盖最右边范围的region重用原始region的Raft组。其他区域则使用新的Raft组。
public void readMessage(final HandlerContext ctx, final RegionPingEvent event) throws Exception {
if (event.isReady()) {
return;
}
final MetadataStore metadataStore = event.getMetadataStore();
final RegionHeartbeatRequest request = event.getMessage();
final long clusterId = request.getClusterId();
final ClusterStatsManager clusterStatsManager = ClusterStatsManager.getInstance(clusterId);
clusterStatsManager.addOrUpdateRegionStats(request.getRegionStatsList());
final Set<Long> stores = metadataStore.unsafeGetStoreIds(clusterId);
if (stores == null || stores.isEmpty()) {
return;
}
if (clusterStatsManager.regionSize() >= stores.size()) {
// one store one region is perfect
return;
}
final Pair<Region, RegionStats> modelWorker = clusterStatsManager.findModelWorkerRegion();
if (!isSplitNeeded(request, modelWorker)) {
return;
}
LOG.info("[Cluster: {}] model worker region is: {}.", clusterId, modelWorker);
final Long newRegionId = metadataStore.createRegionId(clusterId);
final Instruction.RangeSplit rangeSplit = new Instruction.RangeSplit();
rangeSplit.setNewRegionId(newRegionId);
final Instruction instruction = new Instruction();
instruction.setRegion(modelWorker.getKey().copy());
instruction.setRangeSplit(rangeSplit);
event.addInstruction(instruction);
}
合并两个相邻的region与分裂一个region是相反的。两个region的并置副本通过两阶段操作在每个服务器上本地合并,即停止一个region的服务,并将其与另一个region合并。
日志重放
redo log,重做日志,也叫重放日志。和undo log回滚日志一样,都是在数据库发生意外时用来进行数据恢复的,通过前面一篇文章对undo log的总结,我们都知道undo log记录的是数据更新前的样子,主要保证事务的原子性;而redo log则记录的是事务执行过程中的修改情况,redo log主要保证事务的持久性。
learner节点接收Raft组的Raft日志,并将行格式的元组转换为列式数据。为了保持提交数据的线性化语义,它们按照先进先出(FIFO)策略被重放。日志重放有三个步骤:
- 压缩日志:事务性日志被分为三种状态:预写、提交或回滚。回滚日志中的数据不需要写入磁盘,因此压缩过程根据回滚日志删除无效的预写日志,并将有效的日志放入缓冲区。
- 解码元组:将缓冲区中的日志解码为行格式的元组,去除冗余的事务信息。然后,解码后的元组被放入行格式的缓冲区中。
- 转换数据格式:如果行缓冲区中的数据大小超过大小限制或其持续时间超过时间间隔限制,这些行格式元组被转换为列格式数据,并写入本地分区数据池。
schema
使用本地缓存的schema(提要)进行转换,schema会定期与TiKV同步。为了将元组实时转换为列格式,learner节点必须知道最新的schema。最新的schema信息存储在TiKV中。为了减少TiFlash向TiKV请求最新schema的次数,每个learner节点都维护一个schema缓存。如果缓存的schema过期了,被解码的数据和本地schema就会不匹配,数据必须重新转换。
- 定期同步:schema同步器定期从TiKV获取最新的schema,并将更改应用到其本地缓存中。在大多数情况下,这种随机同步降低了schema同步的频率。
- 强制同步:如果schema同步器检测到不匹配的schema,它会主动从TiKV获取最新的schema。当元组和schema之间的列号不同或列值溢出时,会触发此操作。

列存引擎 Delta Tree
为了在列式存储上支持实时更新,论文为TiFlash研发了新的列存引擎Delta Tree。它可以在支持高 TPS 写入的同时,仍然能保持良好的读性能。
TPS,一个表达系统处理能力的性能指标,每秒处理的消息数(Transaction Per Second)
Delta Tree 的架构设计充分参考了 B+ Tree 和 LSM Tree 的设计思想。从整体上看,Delta Tree 将表数据按照主键进行 range 分区,切分后的数据块称为 Segment;然后 Segment 内部则采用了类似 LSM Tree 的分层结构。分区是为了减少每个区的数据量,降低复杂度。
Segment: B+ Tree
B+树是一种树数据结构,通常用于数据库和操作系统的文件系统中。B+树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+树元素自底向上插入,这与二叉树恰好相反。
B+树是B树的一种变形形式,B+树上的叶子结点存储关键字以及相应记录的地址,叶子结点以上各层作为索引使用。一棵m阶的B+树定义如下:
(1)每个结点至多有m个子女;
(2)除根结点外,每个结点至少有[m/2]个子女,根结点至少有两个子女;
(3)有k个子女的结点必有k个关键字。
B+树的查找与B树不同,当索引部分某个结点的关键字与所查的关键字相等时,并不停止查找,应继续沿着这个关键字左边的指针向下,一直查到该关键字所在的叶子结点为止。
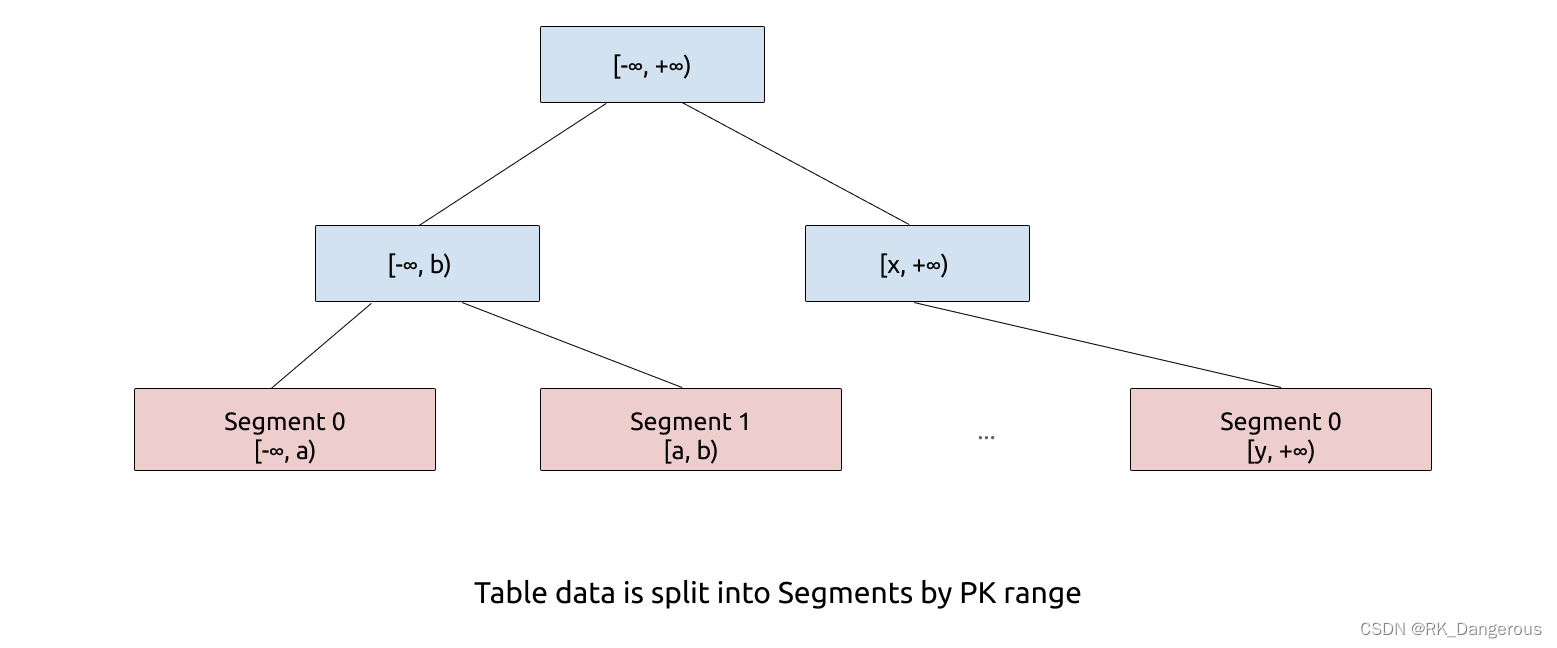
Levels LSM Tree
在 Segment 内部,通过类似 LSM Tree 的分层的方式组织数据。
LSM Tree全称日志结构合并树(Log-Structured Merge Tree)。对于存储介质为磁盘或固态盘的数据库,长期以来主流使用B+树这种索引结构来实现快速数据查找。当数据量不太大时,B+树读写性能表现非常好。但是在海量数据情况下,B+树越来越高,由于B+树更新和删除数据时需要沿着B+树逐层进行页分裂和页合并,严重影响数据写入性能。为了解决这种情况,google在论文《Bigtable: A Distributed Storage System for Structured Data》中介绍了一种新的数据组织结构LSM Tree(Log-Structured Merge Tree)
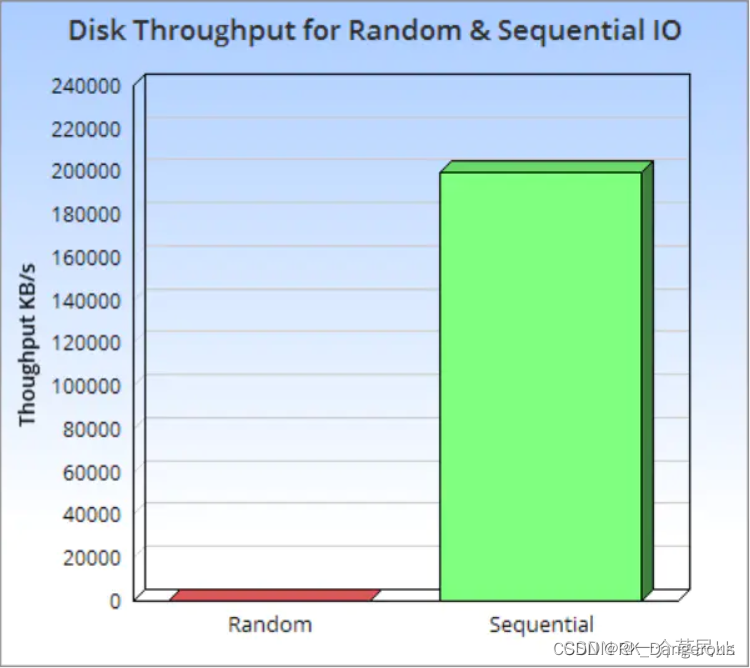
LSM Tree是一个分层、有序、针对块存储设备(HDD和SSD)特点而设计的数据存储结构。他的核心理论基础还是磁盘的顺序写速度比随机写速度快非常多,即使是SSD,由于块擦除和垃圾回收的影响,顺序写速度还是比随机写速度快很多。
LSM Tree将存储数据切分为一系列的SSTable(Sorted String Table),并将SSTable分为 Level 0 - Level N。每个SSTable内的数据都是有序的任意字节组,并且SSTable一旦写入磁盘中就像日志一样无法修改。对于LSM Tree若需要修改或者删除数据并不是直接对旧数据进行操作,而是将新数据写入新的SSTable中。若需删除数据则是写一个相应数据的删除标记的记录到一个新的SSTable中。依照这种方法也确保了LSM Tree写数据时对磁盘的操作都是顺序块写入操作,而没有随机写操作。
LSM Tree这种独特的写入方式,导致在查找数据的时候,LSM Tree 不能像B+ Tree那样在一个统一的索引表中进行查找,而是从最新的SSTable到老的SSTable中依次进行查找。如果在新的SSTable中找到了需要查找的数据或者相应的删除标记,则直接返回查找结果;若没找到,再到老的SSTable中进行查找,直到老的SSTable查找完。为了提高查找效率,LSM Tree对SSTable进行分层、有序组织,就是将SSTable组织成多层,同一层可以有多个SSTable,并且每个SSTable内的数据是有序的。同时,LSM Tree会将多个SSTable合并(Compact)为一个新的SSTable,这样可以减少SSTable的数量,同时把修改前的数据或删除的数据真正从SSTable中删除,减少SSTable的大小,对提高查找性能起到了极其重要的作用。
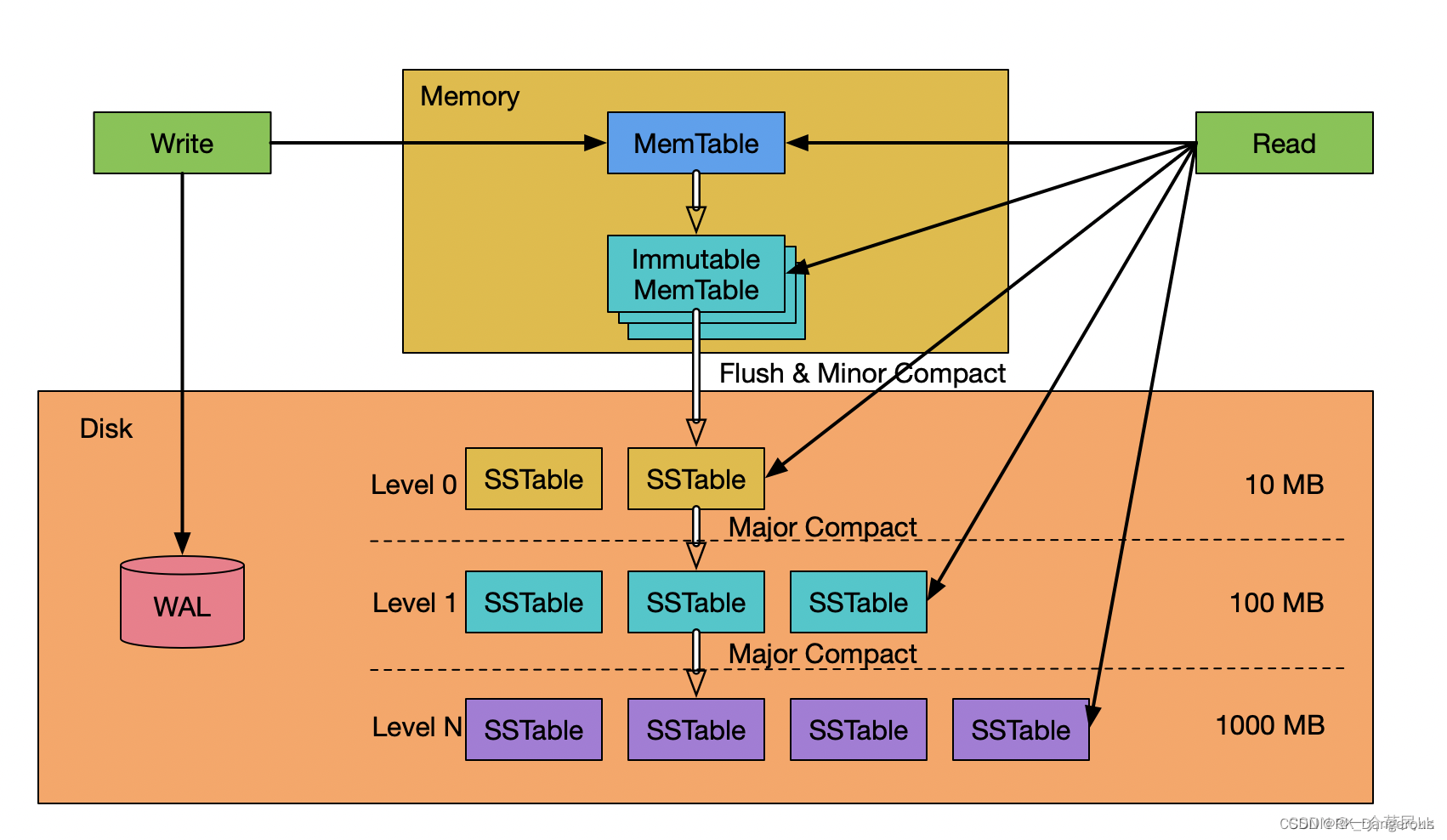
因为 Segment 的数据量相对于其他 LSM Tree 实现要小的多,所以 Delta Tree 只需要固定的两层,即 Delta Layer 和 Stable Layer,分别对应 LSM Tree 的 L0 和 L1。
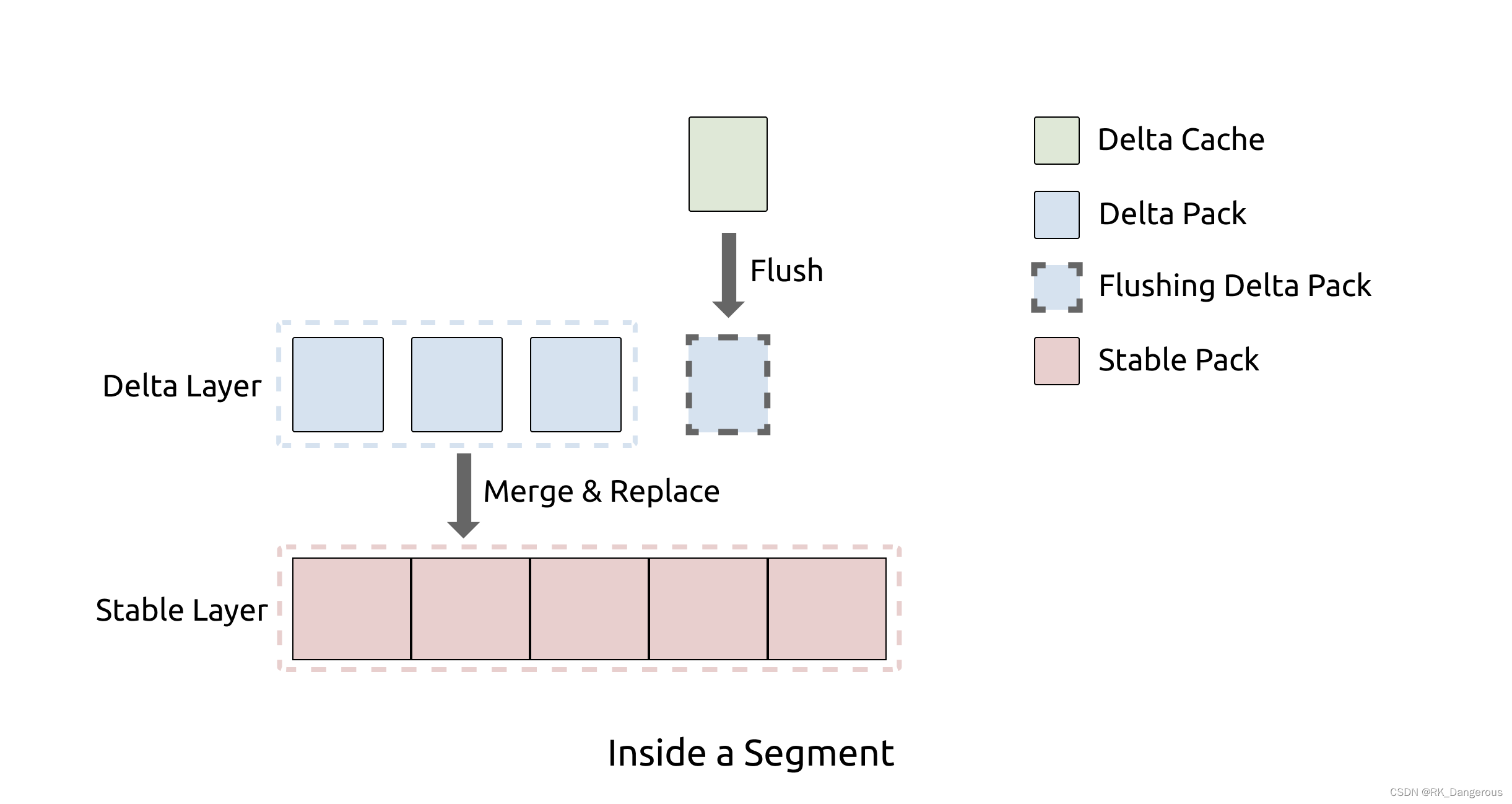
对于 LSM Tree 来说,层数越少,写放大越小。默认配置下,Delta Tree 的理论写放大(不考虑压缩)约为 19 倍。因为列式存储连续存储相同类型的数据,天然对压缩算法更加友好,在生产环境下,Delta Tree 引擎常见的实际写放大低于 5 倍。
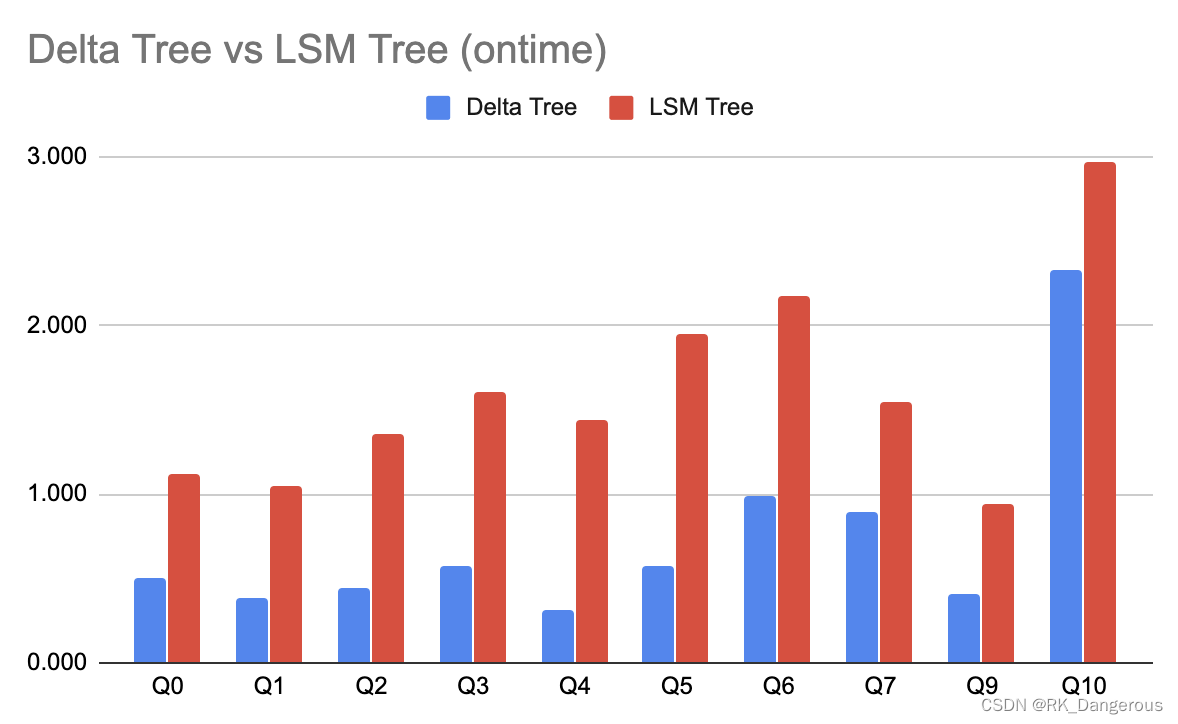
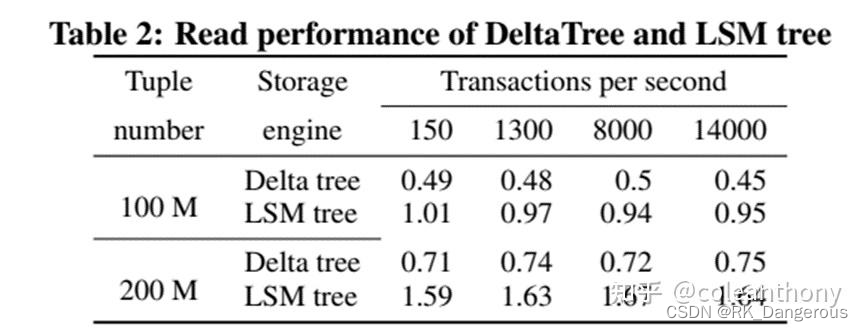
比较
下面是在使用 ontime 数据集,不同 SQL 的耗时对比。可以看到 Delta Tree 在大部分情况下有更大的优势,这不仅归功于 Delta Tree 有更好的 Scan 性能,也因为它支持了粗糙索引(如 Min-Max),可以避免读无关数据。
分析处理
TiDB通过两个查询优化阶段实现查询优化:基于规则的查询优化(rule-based optimization,RBO)产生逻辑计划,然后基于成本的优化(cost-based optimization,CBO)将逻辑计划转换为物理计划。
- RBO:裁剪不需要的列、消除projection(投影)、下推predicates(谓词,用于描述数据行之间关系的条件)、导出predicates、常量floding、消除"group by"或外连接、取消子查询嵌套。
- CBO:会根据执行成本从候选计划中选择最优的计划。
实验
实验评估TiDB的OLTP和OLAP能力。
OLPA能力
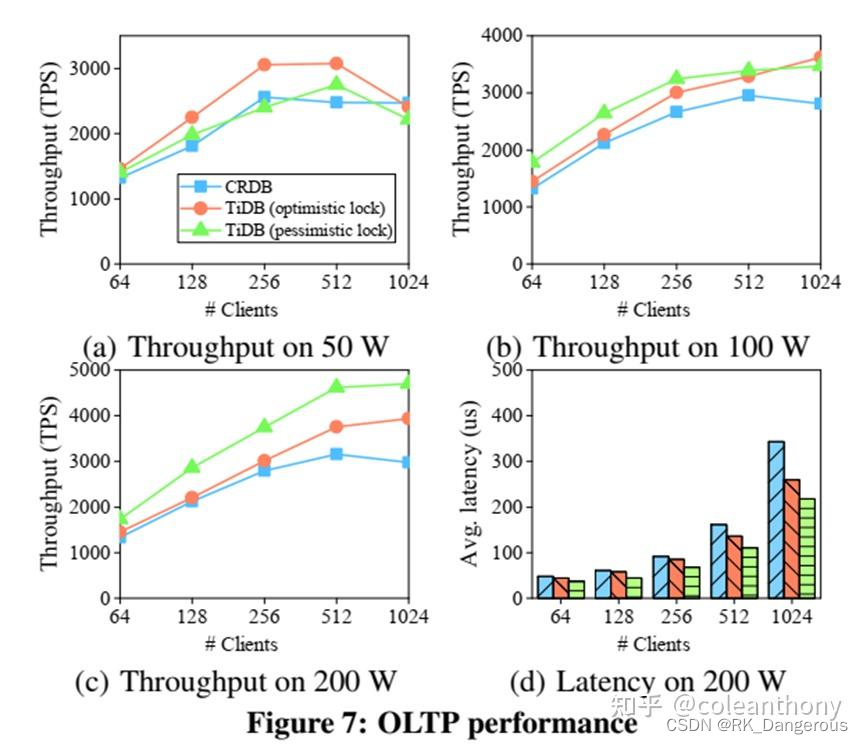
图7(b)和图7©中的吞吐量图与图7(a)不同。在图7(a)中,对于小于256个客户机,无论是乐观锁定还是悲观锁定,TiDB的吞吐量都随着客户机数量的增加而增加。对于256个以上的客户端,乐观锁定的吞吐量保持稳定,然后开始下降,而悲观锁定的吞吐量在512个客户端时达到最大,然后下降。图7(b)和图7©中TiDB的吞吐量一直在增加。
OLAP
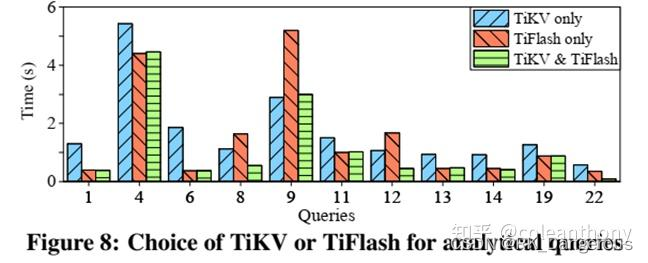
考察SQL引擎选择TiKV和TiFlash的能力。将每个查询运行5次,并计算平均执行时间。如图8所示,只从一种存储中获取数据,两种存储都不优越。同时从TiKV和TiFlash请求数据,性能总是更好。
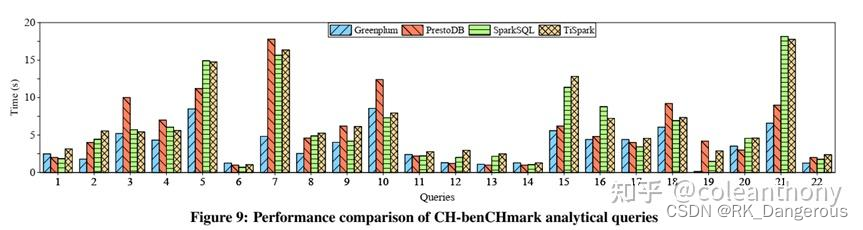
此外,将TiSpark与其他OLAP系统进行比较。使用CH-benCHmark的22个分析查询和500个仓库将TiSpark与SparkSQL、PrestoDB和Greenplum进行比较。TiSpark的性能可以与SparkSQL相媲美,因为它们使用的是相同的引擎。性能差距相当小,主要来自于访问不同的存储系统:扫描压缩的parquet文件更优,所以SparkSQL通常会outper- forms TiSpark。然而,在某些情况下,这种优势被抵消了,因为TiSpark可以将更多的计算推到存储层。
HTAP
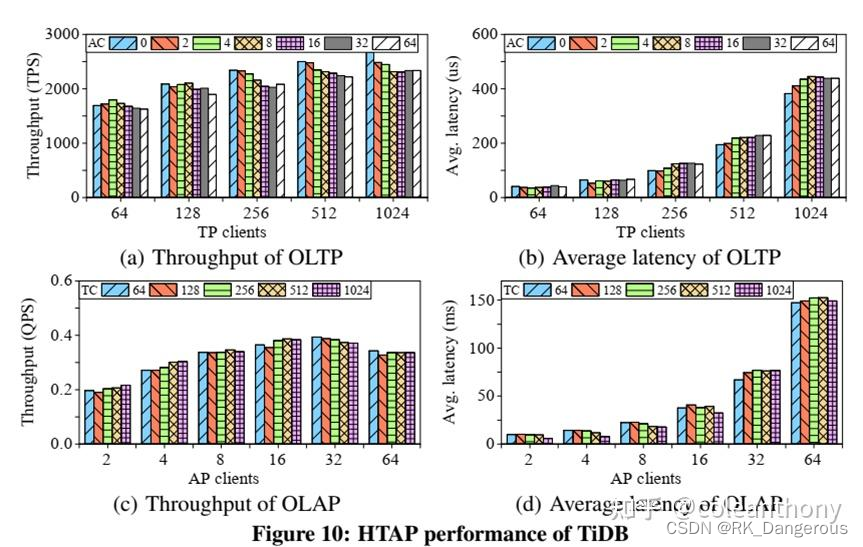
图10分别显示了使用不同数量的TP客户端和AP客户端的事务的吞吐量和平均延迟。
图10(a)和图10(b)吞吐量随着TP客户端数量的增加而增加,但在略小于512个客户端时达到最大值。与相同数量的TP客户端,与没有AP客户端相比,更多的分析处理客户端最多降低10%的TP吞吐量。这证实了TiKV和TiFlash之间的日志复制实现了高度隔离。
类似的吞吐量和延迟结果如图10( c)和10(d)所示,展示了TP对AP请求的影响。AP吞吐量很快就会在16个AP客户端下达到最大值,因为AP查询非常昂贵,并且会争夺资源。这样的争用会降低更多AP客户端的吞吐量。对于相同数量的AP客户端,吞吐量几乎保持不变,最多只下降5%。这说明TP对AP执行的影响并不显著。分析查询的平均延迟的增加源于更多的客户端等待时间的增加。
https://zhuanlan.zhihu.com/p/68952214
https://blog.csdn.net/Weixiaohuai/article/details/117896523
https://baike.baidu.com/item/B+%E6%A0%91/7845683
https://blog.csdn.net/qq_47159522/article/details/126751195
https://cloud.tencent.com/developer/article/1675820
https://wenku.baidu.com/view
https://blog.csdn.net/yumiao0220/article/details/137011515
总结
从现有的数据库演化而来。成熟的数据库可以在现有产品的基础上提供HTAP解决方案,它们特别注重加速分析查询。它们采用自定义方法分别实现数据一致性和高可用性。相比之下,TiDB自然受益于Raft中的日志复制,实现数据一致性和高可用性。
总的来说,TiDB构建在分布式的、基于行的存储TiKV之上,它使用了Raft算法。系统引入了用于实时分析的列式learners,它从TiKV异步复制日志,并将行格式的数据转换为列格式。这种在TiKV和TiFlash之间的日志复制以很少的开销提供实时数据一致性。TiKV和TiFlash可以部署在单独的物理资源上,有效地处理事务性查询和分析性查询。当TiDB扫描表进行事务查询和分析查询时,它们可以被TiDB优选地选择来访问。
https://zhuanlan.zhihu.com/p/679544882

![Redis集合[持续更新]](https://img-blog.csdnimg.cn/img_convert/3e662e81235cf3e798d531d15fe67c77.png)